Printed and electronic copies of Modeling and Simulation in Python are available from No Starch Press and Bookshop.org and Amazon.
Nondimensionalization#
In the previous chapter we swept the parameters of the Kermack-McKendrick (KM) model: the contact rate, beta, and the recovery rate, gamma.
For each pair of parameters, we ran a simulation and computed the total fraction of the population infected.
In this chapter we’ll investigate the relationship between the parameters and this metric, using both simulation and analysis.
The figures in the previous chapter suggest that there is a relationship between the parameters of the KM model, beta and gamma, and the fraction of the population that is infected. Let’s think what that relationship might be.
When
betaexceedsgamma, there are more contacts than recoveries during each day. The difference betweenbetaandgammamight be called the excess contact rate, in units of contacts per day.As an alternative, we might consider the ratio
beta/gamma, which is the number of contacts per recovery. Because the numerator and denominator are in the same units, this ratio is dimensionless, which means it has no units.
Describing physical systems using dimensionless parameters is often a useful move in the modeling and simulation game. In fact, it is so useful that it has a name: nondimensionalization (see http://modsimpy.com/nondim). So that’s what we’ll try first.
Exploring the Results#
In the previous chapter, we wrote a function, sweep_parameters,
that takes an array of values for beta and an array of values for gamma.
It runs a simulation for each pair of parameters and returns a SweepFrame with the results.
I’ll run it again with the following arrays of parameters.
beta_array = [0.1, 0.2, 0.3, 0.4, 0.5,
0.6, 0.7, 0.8, 0.9, 1.0 , 1.1]
gamma_array = [0.2, 0.4, 0.6, 0.8]
frame = sweep_parameters(beta_array, gamma_array)
Here’s what the first few rows look like:
frame.head()
| 0.2 | 0.4 | 0.6 | 0.8 | |
|---|---|---|---|---|
| Parameter | ||||
| 0.1 | 0.010756 | 0.003642 | 0.002191 | 0.001567 |
| 0.2 | 0.118984 | 0.010763 | 0.005447 | 0.003644 |
| 0.3 | 0.589095 | 0.030185 | 0.010771 | 0.006526 |
| 0.4 | 0.801339 | 0.131563 | 0.020917 | 0.010780 |
| 0.5 | 0.896577 | 0.396409 | 0.046140 | 0.017640 |
The SweepFrame has one row for each value of beta and one column for each value of gamma.
We can print the values in the SweepFrame like this:
for gamma in frame.columns:
column = frame[gamma]
for beta in column.index:
metric = column[beta]
print(beta, gamma, metric)
0.1 0.2 0.010756340768063644
0.2 0.2 0.11898421353185373
0.3 0.2 0.5890954199973404
0.4 0.2 0.8013385277185551
0.5 0.2 0.8965769637207062
0.6 0.2 0.942929291399791
0.7 0.2 0.966299311298026
0.8 0.2 0.9781518959989762
0.9 0.2 0.9840568957948106
1.0 0.2 0.9868823507202488
1.1 0.2 0.988148177093735
0.1 0.4 0.0036416926514175607
0.2 0.4 0.010763463373360094
0.3 0.4 0.030184952469116566
0.4 0.4 0.131562924303259
0.5 0.4 0.3964094037932606
0.6 0.4 0.5979016626615987
0.7 0.4 0.7284704154876106
0.8 0.4 0.8144604459153759
0.9 0.4 0.8722697237137128
1.0 0.4 0.9116692168795855
1.1 0.4 0.9386802509510287
0.1 0.6 0.002190722188881611
0.2 0.6 0.005446688837466351
0.3 0.6 0.010771139974975585
0.4 0.6 0.020916599304195316
0.5 0.6 0.04614035896610047
0.6 0.6 0.13288938996079536
0.7 0.6 0.3118432512847451
0.8 0.6 0.47832565854255393
0.9 0.6 0.605687582114665
1.0 0.6 0.7014254793376209
1.1 0.6 0.7738176405451065
0.1 0.8 0.0015665254038139675
0.2 0.8 0.003643953969662994
0.3 0.8 0.006526163529085194
0.4 0.8 0.010779807499500693
0.5 0.8 0.017639902596349066
0.6 0.8 0.030291868201986594
0.7 0.8 0.05882382948158804
0.8 0.8 0.13358889291095588
0.9 0.8 0.2668895539427739
1.0 0.8 0.40375121210421994
1.1 0.8 0.519583469821867
This is the first example we’ve seen with one for loop inside another:
Each time the outer loop runs, it selects a value of
gammafrom the columns of theSweepFrameand extracts the corresponding column.Each time the inner loop runs, it selects a value of
betafrom the index of the column and selects the corresponding element, which is the fraction of the population that got infected.
Since there are 11 rows and 4 columns, the total number of lines in the output is 44.
The following function uses the same loops to enumerate the elements of the SweepFrame, but instead of printing a line for each element, it plots a point.
from matplotlib.pyplot import plot
def plot_sweep_frame(frame):
for gamma in frame.columns:
column = frame[gamma]
for beta in column.index:
metric = column[beta]
plot(beta/gamma, metric, '.', color='C1')
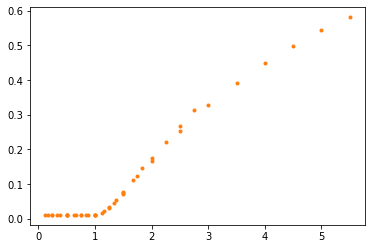
For each element of the SweepFrame it plots a point with the ratio beta/gamma as the \(x\) coordinate and metric – which is the fraction of the population that’s infected – as the \(y\) coordinate.
Here’s what it looks like:
plot_sweep_frame(frame)
decorate(xlabel='Contact number (beta/gamma)',
ylabel='Fraction infected')
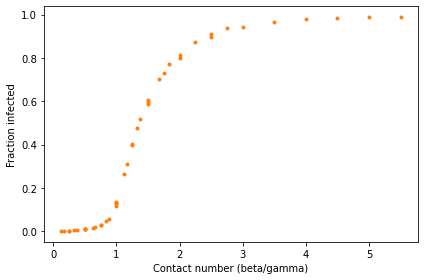
The results fall on a single curve, at least approximately. That means that we can predict the fraction of the population that will be infected based on a single parameter, the ratio beta/gamma. We don’t need to know the values of beta and gamma separately.
Contact Number#
From Chapter 11, recall that the number of new infections in a given day is \(\beta s i N\), and the number of recoveries is \(\gamma i N\). If we divide these quantities, the result is \(\beta s / \gamma\), which is the number of new infections per recovery (as a fraction of the population).
When a new disease is introduced to a susceptible population, \(s\) is approximately 1, so the number of people infected by each sick person is \(\beta / \gamma\). This ratio is called the contact number or basic reproduction number (see http://modsimpy.com/contact). By convention it is usually denoted \(R_0\), but in the context of an SIR model, that notation is confusing, so we’ll use \(c\) instead.
The results in the previous section suggest that there is a relationship between \(c\) and the total number of infections. We can derive this relationship by analyzing the differential equations from Chapter 11:
In the same way we divided the contact rate by the infection rate to get the dimensionless quantity \(c\), now we’ll divide \(di/dt\) by \(ds/dt\) to get a ratio of rates:
Which we can simplify as
Replacing \(\beta/\gamma\) with \(c\), we can write
Dividing one differential equation by another is not an obvious move, but in this case it is useful because it gives us a relationship between \(i\), \(s\), and \(c\) that does not depend on time. From that relationship, we can derive an equation that relates \(c\) to the final value of \(s\). In theory, this equation makes it possible to infer \(c\) by observing the course of an epidemic.
Here’s how the derivation goes. We multiply both sides of the previous equation by \(ds\):
And then integrate both sides:
where \(q\) is a constant of integration. Rearranging terms yields:
Now let’s see if we can figure out what \(q\) is. At the beginning of an epidemic, if the fraction infected is small and nearly everyone is susceptible, we can use the approximations \(i(0) = 0\) and \(s(0) = 1\) to compute \(q\):
Since \(\log 1 = 0\), we get \(q = 1\).
Now, at the end of the epidemic, let’s assume that \(i(\infty) = 0\), and \(s(\infty)\) is an unknown quantity, \(s_{\infty}\). Now we have:
Solving for \(c\), we get
By relating \(c\) and \(s_{\infty}\), this equation makes it possible to estimate \(c\) based on data, and possibly predict the behavior of future epidemics.
Analysis and Simulation#
Let’s compare this analytic result to the results from simulation. I’ll create an array of values for \(s_{\infty}\).
s_inf_array = linspace(0.003, 0.99, 50)
And compute the corresponding values of \(c\):
from numpy import log
c_array = log(s_inf_array) / (s_inf_array - 1)
To get the total infected, we compute the difference between \(s(0)\) and
\(s(\infty)\), then store the results in a Series:
frac_infected = 1 - s_inf_array
The ModSim library provides a function called make_series we can use to put c_array and frac_infected in a Pandas Series.
frac_infected_series = make_series(c_array, frac_infected)
Now we can plot the results:
plot_sweep_frame(frame)
frac_infected_series.plot(label='analysis')
decorate(xlabel='Contact number (c)',
ylabel='Fraction infected')
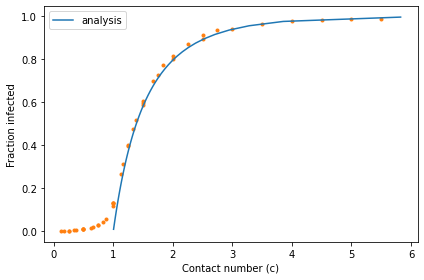
When the contact number exceeds 1, analysis and simulation agree. When the contact number is less than 1, they do not: analysis indicates there should be no infections; in the simulations there are a small number of infections.
The reason for the discrepancy is that the simulation divides time into a discrete series of days, whereas the analysis treats time as a continuous quantity. When the contact number is large, these two models agree; when it is small, they diverge.
Estimating Contact Number#
The previous figure shows that if we know the contact number, we can estimate the fraction of the population that will be infected with just a few arithmetic operations. We don’t have to run a simulation.
We can also read the figure the other way; if we know what fraction of the population was affected by a past outbreak, we can estimate the contact number.
Then, if we know one of the parameters, like gamma, we can use the contact number to estimate the other parameter, like beta.
At least in theory, we can. In practice, it might not work very well, because of the shape of the curve.
When the contact number is low, the curve is quite steep, which means that small changes in \(c\) yield big changes in the number of infections. If we observe that the total fraction infected is anywhere from 20% to 80%, we would conclude that \(c\) is near 2.
And when the contact number is high, the curve is nearly flat, which means that it’s hard to see the difference between values of \(c\) between 3 and 6.
With the uncertainty of real data, we might not be able to estimate \(c\) with much precision. But as one of the exercises below, you’ll have a chance to try.
Summary#
In this chapter we used simulations to explore the relationship between beta, gamma, and the fraction infected.
Then we used analysis to explain that relationship.
With that, we are done with the Kermack-McKendrick model. In the next chapter we’ll move on to thermal systems and the notorious coffee cooling problem.
Exercises#
This chapter is available as a Jupyter notebook where you can read the text, run the code, and work on the exercises. You can access the notebooks at https://allendowney.github.io/ModSimPy/.
Exercise 1#
At the beginning of this chapter, I suggested two ways to relate beta and gamma: we could compute their difference or their ratio.
Because the ratio is dimensionless, I suggested we explore it first, and that led us to discover the contact number, which is beta/gamma.
When we plotted the fraction infected as a function of the contact number, we found that this metric falls on a single curve, at least approximately.
That indicates that the ratio is enough to predict the results; we don’t have to know beta and gamma individually.
But that leaves a question open: what happens if we do the same thing using the difference instead of the ratio?
Write a version of plot_sweep_frame, called plot_sweep_frame_difference, that plots the fraction infected versus the difference beta-gamma.
What do the results look like, and what does that imply?
Exercise 2#
Suppose you run a survey at the end of the semester and find that 26% of students had the Freshman Plague at some point.
What is your best estimate of c?
Hint: if you display frac_infected_series, you can read off the answer.
Exercise 3#
So far the only metric we have considered is the total fraction of the population that gets infected over the course of an epidemic. That is an important metric, but it is not the only one we care about.
For example, if we have limited resources to deal with infected people, we might also be concerned about the number of people who are sick at the peak of the epidemic, which is the maximum of I.
Write a version of sweep_beta that computes this metric, and use it to compute a SweepFrame for a range of values of beta and gamma.
Make a contour plot that shows the value of this metric as a function of beta and gamma.
Then use plot_sweep_frame to plot the maximum of I as a function of the contact number, beta/gamma.
Do the results fall on a single curve?
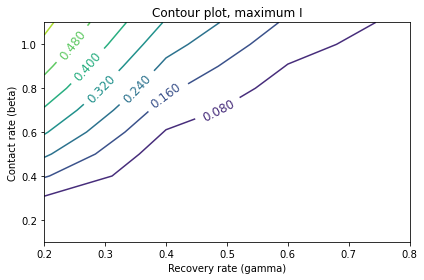
Under the Hood#
ModSim provides make_series to make it easier to create a Pandas Series. In this chapter, we used it like this:
frac_infected_series = make_series(c_array, frac_infected)
If you import Series from Pandas, you can make a Series yourself, like this:
from pandas import Series
frac_infected_series = Series(frac_infected, c_array)
The difference is that the arguments are in reverse order: the first argument is stored as the values in the Series; the second argument is stored as the index.
I find that order counterintuitive, which is why I use make_series.
make_series takes the same optional keyword arguments as Series, which you can read about at https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html.