Huffman Code
Contents
Huffman Code#
Click here to run this chapter on Colab
A Huffman code is a “type of optimal prefix code that is commonly used for lossless data compression”. There are three parts of that definition we have to unpack: “code”, “prefix”, and “optimal”.
In this context, a “code” is a mapping from symbols to bit strings. For example, ASCII is a character encoding that maps from characters (like letters, numbers, and punctuation) to seven-bit integers. Since all ASCII bit strings are the same length, it is a “fixed-length code”, as contrasted with Huffman codes, which are “variable-length codes”.
In order to decode something encoded in a variable-length code, there has to be some way to figure out where one bit string ends and the next begins. In general, there are three ways to solve this problem:
One option is to begin each bit string with a special sequence that indicates its length. This is how Unicode works.
Another option is to end each bit string with a special sequence that marks the end.
The third option is to use a “prefix code”, which is how Huffman codes work.
A prefix code is a code where no whole bit string in the code is a prefix of any bit string in the code. If a code has this property, we can decode it by reading bits one at a time and checking to see whether we have completed a valid bit string. If so, we know we are at the end of the bit string, because it cannot be the prefix of another bit string.
For example, the following is a prefix code with only three symbols:
symbol bit string
x 1
y 01
z 001
In this code, we can encode the string xyz with the bit string 101001, and we can decode the result without ambiguity.
So that’s what it means to say that a Huffman code is a prefix code; finally, Huffman codes are “optimal” in the sense that they give short codes to the most common symbols and longer codes to the least common symbols. The result is that they minimize the average number of bits needed to encode a sequence of symbols.
However, in order to achieve this feat, we have to know the relative frequencies of the symbols. One way to do that is to start with a “corpus”, which is a text that contains the symbols in the proportions we expect for the text we will encode.
As an example, I’ll use the text from the Huffman code Wikipedia page.
text = 'this is an example of a huffman tree'
We can use a Counter to count the number of times each symbol appears in this text.
from collections import Counter
c = Counter(text)
c
Counter({'t': 2,
'h': 2,
'i': 2,
's': 2,
' ': 7,
'a': 4,
'n': 2,
'e': 4,
'x': 1,
'm': 2,
'p': 1,
'l': 1,
'o': 1,
'f': 3,
'u': 1,
'r': 1})
Now let’s see how we can use these counts to build a Huffman code. The first step is to build a Huffman tree, which is a binary tree where every node contains a count and some nodes contain symbols.
To make a Huffman tree, we start with a sequence of nodes, one for each symbol.
To represent nodes, I’ll use a namedtuple.
from collections import namedtuple
Node = namedtuple('Node', ['count', 'letter', 'left', 'right'])
For example, here’s a node that represents the symbol a with count 4.
Since this node has no children, it is a leaf node.
left = Node(4, 'a', None, None)
left
Node(count=4, letter='a', left=None, right=None)
And here’s another leaf node that represents the symbol n and its count.
right = Node(2, 'n', None, None)
right
Node(count=2, letter='n', left=None, right=None)
One reason we’re using a namedtuple is that it behaves like a tuple, so if we compare two Node objects, we get a tuple-like sorting order.
left > right
True
If two nodes have the same count, they get sorted in alphabetical order by letter.
Making trees#
Given these two leaf nodes, we can make a tree like this:
count = left.count + right.count
root = Node(count, '\0', left, right)
root
Node(count=6, letter='\x00', left=Node(count=4, letter='a', left=None, right=None), right=Node(count=2, letter='n', left=None, right=None))
Because root has children, it is not a leaf node; it is an interior node.
In a Huffman tree, the interior nodes do not represent symbols, so I have set letter to the null character \0.
The count of an interior node is the sum of the count of its children.
Now, to build a Huffman tree, we’ll start with a collection of nodes, one for each symbol, and build the tree “bottom up” by following these steps:
Remove the node with the lowest count.
Remove the node with the next lowest count.
Make a new node with the nodes we just removed as children.
Put the new node back into the collection.
If there’s only one node in the collection, it’s the Huffman tree, and we’re done.
In general, we could use any kind of collection, but if we look at the operations required by this algorithm, the most efficient option is a heap.
But we’ll start by iterating through the Counter and making a list of Node objects,
nodes = [Node(count, letter, None, None)
for (letter, count) in c.items()]
nodes
[Node(count=2, letter='t', left=None, right=None),
Node(count=2, letter='h', left=None, right=None),
Node(count=2, letter='i', left=None, right=None),
Node(count=2, letter='s', left=None, right=None),
Node(count=7, letter=' ', left=None, right=None),
Node(count=4, letter='a', left=None, right=None),
Node(count=2, letter='n', left=None, right=None),
Node(count=4, letter='e', left=None, right=None),
Node(count=1, letter='x', left=None, right=None),
Node(count=2, letter='m', left=None, right=None),
Node(count=1, letter='p', left=None, right=None),
Node(count=1, letter='l', left=None, right=None),
Node(count=1, letter='o', left=None, right=None),
Node(count=3, letter='f', left=None, right=None),
Node(count=1, letter='u', left=None, right=None),
Node(count=1, letter='r', left=None, right=None)]
Next we’ll use the heap module to convert the list to a heap.
from heapq import heapify, heappop, heappush
heap = nodes.copy()
heapify(heap)
heap
[Node(count=1, letter='l', left=None, right=None),
Node(count=1, letter='p', left=None, right=None),
Node(count=1, letter='o', left=None, right=None),
Node(count=1, letter='r', left=None, right=None),
Node(count=2, letter='h', left=None, right=None),
Node(count=2, letter='i', left=None, right=None),
Node(count=1, letter='u', left=None, right=None),
Node(count=2, letter='s', left=None, right=None),
Node(count=1, letter='x', left=None, right=None),
Node(count=2, letter='m', left=None, right=None),
Node(count=7, letter=' ', left=None, right=None),
Node(count=4, letter='a', left=None, right=None),
Node(count=2, letter='t', left=None, right=None),
Node(count=3, letter='f', left=None, right=None),
Node(count=2, letter='n', left=None, right=None),
Node(count=4, letter='e', left=None, right=None)]
Now we can use the heap to make a tree.
Exercise: Write a function called make_tree that takes a heap of Node objects and uses the algorithm I described to make and return a Huffman tree. In other words, it should join up the nodes into a tree and return the root node.
Use this code to test it.
tree = make_tree(heap)
Drawing the Tree#
To see what it looks like, we’ll use NetworkX and a library called EoN.
try:
import EoN
except ImportError:
!pip install EoN
The following function traverses the Huffman tree and makes a NetworkX DiGraph.
import networkx as nx
def add_edges(parent, G):
"""Make a NetworkX graph that represents the tree."""
if parent is None:
return
for child in (parent.left, parent.right):
if child:
G.add_edge(parent, child)
add_edges(child, G)
G = nx.DiGraph()
add_edges(tree, G)
The following function traverses the tree again and collects the node labels in a dictionary.
def get_labels(parent, labels):
if parent is None:
return
if parent.letter == '\0':
labels[parent] = parent.count
else:
labels[parent] = parent.letter
get_labels(parent.left, labels)
get_labels(parent.right, labels)
labels = {}
get_labels(tree, labels)
def get_edge_labels(parent, edge_labels):
if parent is None:
return
if parent.left:
edge_labels[parent, parent.left] = '0'
get_edge_labels(parent.left, edge_labels)
if parent.right:
edge_labels[parent, parent.right] = '1'
get_edge_labels(parent.right, edge_labels)
edge_labels = {}
get_edge_labels(tree, edge_labels)
len(edge_labels)
30
Now we’re ready to draw.
from EoN import hierarchy_pos
def draw_tree(tree):
G = nx.DiGraph()
add_edges(tree, G)
pos = hierarchy_pos(G)
labels = {}
get_labels(tree, labels)
edge_labels = {}
get_edge_labels(tree, edge_labels)
nx.draw(G, pos, labels=labels, alpha=0.4)
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_color='C1')
draw_tree(tree)
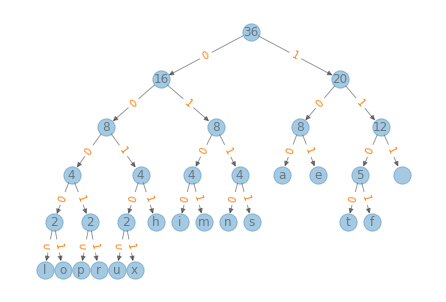
The result might not be identical to the tree on the Wikipedia page, but a letter in our tree should be on the same level as the same letter in their tree.
Making the Table#
The following function traverses the tree, keeping track of the path as it goes. When it finds a leaf node, it makes an entry in the table.
def is_leaf(node):
return node.left is None and node.right is None
def make_table(node, path, table):
if node is None:
return
if is_leaf(node):
table[node.letter] = path
return
make_table(node.left, path+'0', table)
make_table(node.right, path+'1', table)
table = {}
make_table(tree, '', table)
table
{'l': '00000',
'o': '00001',
'p': '00010',
'r': '00011',
'u': '00100',
'x': '00101',
'h': '0011',
'i': '0100',
'm': '0101',
'n': '0110',
's': '0111',
'a': '100',
'e': '101',
't': '1100',
'f': '1101',
' ': '111'}
Encoding#
We can use the table to encode a string by looking up each symbol in the string and joining the results into a bit string.
def encode(s, table):
t = [table[letter] for letter in s]
return ''.join(t)
Here’s an example, noting that we can encode strings other than the corpus we started with, provided that it contains no symbols that were not in the corpus.
code = encode('this is spinal tap',table)
code
'1100001101000111111010001111110111000100100011010000000111110010000010'
Decoding#
To decode the bit string, we start at the top of the tree and follow the path, turning left when we see a 0 and right when we see a 1.
If we get to a leaf node, we have decoded a symbol, so we should record it and then jump back to the top of the tree to start decoding the next symbol.
Exercise: Write a function called decode that takes as parameters a string on 0s and 1s and a Huffman tree. It should decode the message and return it as a string.
decode(code, tree)
'this is spinal tap'
Data Structures and Information Retrieval in Python
Copyright 2021 Allen Downey
License: Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International