You can order print and ebook versions of Think Bayes 2e from Bookshop.org and Amazon.
The Red Line Problem#
This example is based on an exercise from Think Bayes, 2nd edition:
The Red Line is a subway that connects Cambridge and Boston, Massachusetts. When I was working in Cambridge I took the Red Line from Kendall Square to South Station and caught the commuter rail to Needham. During rush hour Red Line trains run every 7-8 minutes, on average.
When I arrived at the subway stop, I could estimate the time until the next train based on the number of passengers on the platform. If there were only a few people, I inferred that I just missed a train and expected to wait about 7 minutes. If there were more passengers, I expected the train to arrive sooner. But if there were a large number of passengers, I suspected that trains were not running on schedule, so I expected to wait a long time.
While I was waiting, I thought about how Bayesian inference could help predict my wait time and decide when I should give up and take a taxi. This example presents the analysis I came up with.
In this previous example I solve a version of the Red Line Problem using grid algorithms. In this notebook, we’ll solve it using PyMC.
If you are not familiar with PyMC, you can start with this chapter from Think Bayes, especially the World Cup Problem. Or you can run that chapter on Colab.
You can read the slides I used to present this example.
Click here to run this notebook on Colab
# Get utils.py
from os.path import basename, exists
def download(url):
filename = basename(url)
if not exists(filename):
from urllib.request import urlretrieve
local, _ = urlretrieve(url, filename)
print('Downloaded ' + local)
download('https://github.com/AllenDowney/ThinkBayes2/raw/master/soln/utils.py')
try:
import empiricaldist
except ImportError:
!pip install empiricaldist
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
from utils import decorate
# Make the figures smaller to save some screen real estate
plt.rcParams['figure.dpi'] = 75
plt.rcParams['figure.figsize'] = [6, 3.5]
plt.rcParams['axes.titlelocation'] = 'left'
Before we get to the analysis, we have to make some modeling decisions. First, I will treat passenger arrivals as a Poisson process, which means I assume that passengers are equally likely to arrive at any time, and that they arrive at a rate, λ, measured in passengers per minute. Since I observe passengers during a short period of time, and at the same time every day, I assume that λ is constant.
On the other hand, the arrival process for trains is not Poisson. Trains to Boston are supposed to leave from the end of the line (Alewife station) every 7–8 minutes during peak times, but by the time they get to Kendall Square, the time between trains varies between 3 and 12 minutes.
To gather data on the time between trains, I wrote a script that downloads real-time data from the MBTA, selects south-bound trains arriving at Kendall Square, and records their arrival times in a database. I ran the script from 4 pm to 6 pm every weekday for 5 days, and recorded about 15 arrivals per day. Then I computed the time between consecutive arrivals. Here are the gap times, which I recorded in seconds, converted to minutes.
observed_gap_times = np.array([
428.0, 705.0, 407.0, 465.0, 433.0, 425.0, 204.0, 506.0, 143.0, 351.0,
450.0, 598.0, 464.0, 749.0, 341.0, 586.0, 754.0, 256.0, 378.0, 435.0,
176.0, 405.0, 360.0, 519.0, 648.0, 374.0, 483.0, 537.0, 578.0, 534.0,
577.0, 619.0, 538.0, 331.0, 186.0, 629.0, 193.0, 360.0, 660.0, 484.0,
512.0, 315.0, 457.0, 404.0, 740.0, 388.0, 357.0, 485.0, 567.0, 160.0,
428.0, 387.0, 901.0, 187.0, 622.0, 616.0, 585.0, 474.0, 442.0, 499.0,
437.0, 620.0, 351.0, 286.0, 373.0, 232.0, 393.0, 745.0, 636.0, 758.0,
]) / 60
I’ll use KDE to estimate the distribution of gap times.
from scipy.stats import gaussian_kde
kde_gap = gaussian_kde(observed_gap_times)
def plot_kde(kde, **options):
xs = np.linspace(0, 20, 101)
ps = kde(xs)
plt.plot(xs, ps, **options)
plot_kde(kde_gap, label='actual')
decorate(xlabel='Gap between trains (minutes)')
plt.savefig('red_line1.png', dpi=300)
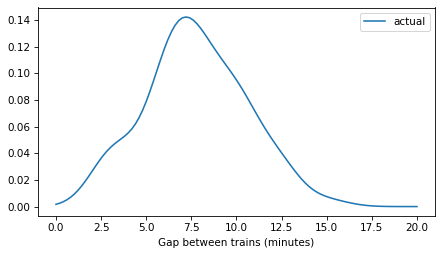
Length-biased sampling#
If you arrive at the station at a random time, you are more likely to arrive during a long gap than a small one. To estimate the distribution of gap times – as seen by a random arrival – we can use KDE again, with the gap times themselves as weights. For more about this kind of length-biased sampling, see Chapter 2 of Probably Overthinking It.
kde_prior = gaussian_kde(observed_gap_times, weights=observed_gap_times)
Here’s what these distributions look like – the actual distribution of times between trains and the observed distribution as seen by a random arrival.
plot_kde(kde_gap, label='actual')
plot_kde(kde_prior, label='observed')
decorate(xlabel='Gap between trains (minutes)')
plt.savefig('red_line2.png', dpi=300)
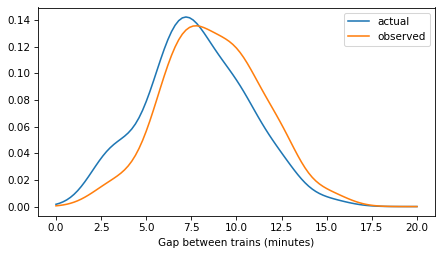
Model 1: KDE prior of gap times#
Since we have a sample from the prior, one option is to use KDE to construct the prior distribution of gap times, as seen by a random arrival.
The following function takes the sample and returns an Interpolated object that represents the prior.
For the sampler to behave well, we need to evaluate the estimated density far enough into the tails to make a smooth transition down to 0.
def make_interpolated(name, sample):
"""Make an Interpolated distribution from a sample.
Uses the sample as weights to simulate length-biased sampling.
sample: array of observed gap times
"""
m = np.mean(sample)
s = np.std(sample)
qs = np.linspace(m - 5*s, m + 5*s, 301)
ps = gaussian_kde(sample, weights=sample)(qs)
return pm.Interpolated(name, qs, ps)
Here’s a model that uses that prior of gap times and a normal model for the arrival rate of passengers. As a starting place, I’ll assume we have a precise estimate of the passenger arrival rate – we’ll relax that assumption later.
with pm.Model() as model:
gap_time = make_interpolated('gap_time', observed_gap_times)
elapsed_time = pm.Uniform('elapsed_time', lower=0, upper=gap_time)
remaining_time = pm.Deterministic('remaining_time', gap_time - elapsed_time)
rate = pm.Normal('rate', 2, sigma=0.1)
mu = elapsed_time * rate
n = pm.Poisson('n', mu=mu, observed=10)
With the following function, we can make different versions of the model with different values of n_obs.
# train gap time: interpolated
# passenger arrival rate: Normal
def make_model1(n_obs=10):
"""Make a model of the red line problem.
n_obs: observed passengers
"""
with pm.Model() as model:
gap_time = make_interpolated('gap_time', observed_gap_times)
elapsed_time = pm.Uniform('elapsed_time', lower=0, upper=gap_time)
remaining_time = pm.Deterministic('remaining_time', gap_time - elapsed_time)
rate = pm.Normal('rate', 2, sigma=0.1)
mu = elapsed_time * rate
n = pm.Poisson('n', mu=mu, observed=n_obs)
return model
Model 2: Normal prior of gap times#
The KDE prior might be most faithful to the data, but it probably includes details of the sample that are not generalizable. It might be just as reasonable to use a normal prior, and it might improve the performance of the sampler.
To see how good the model is, we can use the estimated density to compute a CDF.
from empiricaldist import Pmf
xs = np.linspace(0.01, 25, 101)
ps = kde_prior.evaluate(xs)
pmf_prior = Pmf(ps, xs)
pmf_prior.normalize()
cdf_prior = pmf_prior.make_cdf()
And we can compare it to a normal distribution with the same mean and standard deviation.
m, s = pmf_prior.mean(), pmf_prior.std()
m, s
(8.722148176141644, 2.8567715562910942)
The following figure compares the distributions.
from empiricaldist import Cdf
# generate a 90% CI for cdf_prior
n = len(observed_gap_times)
qs = cdf_prior.qs
resampled = [Cdf.from_seq(kde_prior.resample(n)[0])(qs) for i in range(101)]
resampled = np.array(resampled)
resampled.sort(axis=0)
low = resampled[5]
high = resampled[95]
from scipy.stats import norm
xs = np.linspace(0, 25, 101)
ps = norm.cdf(xs, loc=m, scale=s)
plt.plot(xs, ps, color='gray', label='Normal model')
cdf_prior.plot(label='KDE prior')
plt.fill_between(qs, low, high, color='C0', alpha=0.1, lw=0)
decorate(xlabel='Gap time (minutes)', ylabel='CDF')
plt.savefig('red_line4.png', dpi=300)
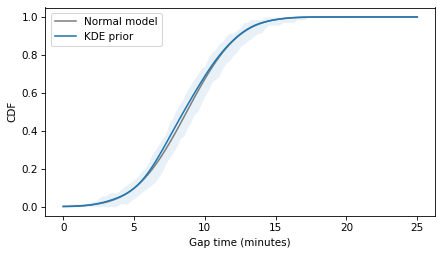
The normal model fits the estimated density well, so it’s probably a good choice to represent the prior distribution of gap times, as in the following model.
# train gap time: Normal
# passenger arrival rate: Normal
def make_model2(n_obs=10):
m, s = pmf_prior.mean(), pmf_prior.std()
with pm.Model() as model:
gap_time = pm.Normal('gap_time', mu=m, sigma=s)
elapsed_time = pm.Uniform('elapsed_time', lower=0, upper=gap_time)
remaining_time = pm.Deterministic('remaining_time', gap_time - elapsed_time)
rate = pm.Normal('rate', 2, sigma=0.1)
mu = elapsed_time * rate
n = pm.Poisson('n', mu=mu, observed=n_obs)
return model
Model 3: Lognormal prior of gap times#
With both of the previous models, we see some divergences in the sampling process, especially when n_obs is small, because that’s when we explore the low end of the range of gap times, which is where the the KDE model and the normal model can be non-physical – specifically, they can generate negative gap times.
To avoid that, we can use a prior distribution on a positive (or non-negative) domain. One natural choice is a lognormal distribution. Many datasets that are well modeled by a normal distribution are also well modeled by a lognormal distribution, but the lognormal has two advantages: it is guaranteed to be positive, and it is usually skewed to the right, allowing the possibility of larger gap times.
To find the lognormal distribution that best fits the data, we’ll use least squares optimization of the CDF.
The following function evaluates the CDF of the lognormal distribution with parameters m and s (which are not the mean and standard deviation of the distribution).
from scipy.stats import lognorm
def lognormal_cdf(xs, m, s):
return lognorm.cdf(xs, s, scale=np.exp(m))
For a given set of parameters, the following function computes the CDF of a lognormal distribution and compares it to the CDF of the estimated densities, returning the differences between the CDFs for a range of quantities.
def residuals(params, cdf_prior):
m, s = params
qs = cdf_prior.qs
ps = lognormal_cdf(qs, m, s)
return ps - cdf_prior.ps
Now we can find the parameters that minimized the area between the CDFs.
from scipy.optimize import least_squares
initial_guess = [2, 0.4]
result1 = least_squares(residuals, initial_guess, args=(cdf_prior,))
assert result1.success == True
m, s = result1.x
m, s
(2.121680868543866, 0.3296983754762425)
The following figure shows the best lognormal model and the CDF of the estimated density.
qs = cdf_prior.qs
ps = lognormal_cdf(qs, m, s)
plt.plot(qs, ps, color='gray', label='Lognormal model')
pmf_prior.make_cdf().plot(label='KDE prior')
plt.fill_between(qs, low, high, color='C0', alpha=0.1, lw=0)
decorate(xlabel='Gap time (minutes)', ylabel='CDF')
plt.savefig('red_line5.png', dpi=300)
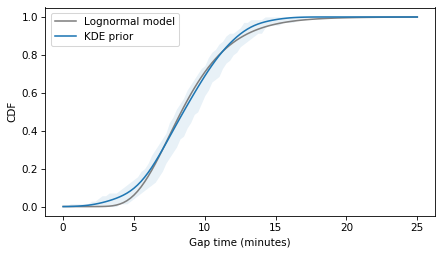
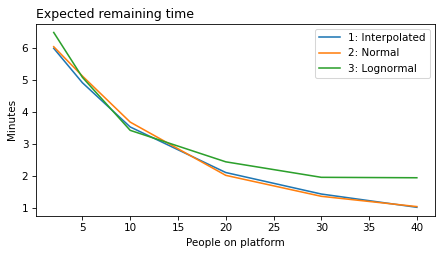
The lognormal model does not fit the estimated densities as well as the normal model, so there is a trade-off between the advantages of the lognormal model and fidelity to the data.
# train gap time: Lognormal
# passenger arrival rate: Normal
def make_model3(n_obs=10):
m, s = result1.x
with pm.Model() as model:
log_time = pm.Normal('log_time', mu=m, sigma=s)
gap_time = pm.Deterministic('gap_time', pm.math.exp(log_time))
elapsed_time = pm.Uniform('elapsed_time', lower=0, upper=gap_time)
remaining_time = pm.Deterministic('remaining_time', gap_time - elapsed_time)
rate = pm.Normal('rate', 2, sigma=0.1)
mu = elapsed_time * rate
n = pm.Poisson('n', mu=mu, observed=n_obs)
return model
Model 4: gamma prior of rates#
For the prior distribution of the arrival rate, we’ve been assuming so far that we have a precise estimate.
As a result, when n_obs is large, the model is compelled to conclude that the elapsed time is longer than usual – it does not have the option to infer that the arrival rate might be larger than usual.
To add this capability to the model, we can increase the standard deviation of the normal model of arrival rates. But if we increase it too much, we run into the same problem we saw with the normal model of gap times – it can go negative.
To avoid that, we can use a gamma distribution, which is guaranteed to be non-negative. For a given mean and standard deviation, we can find the parameters of the gamma distribution.
mu = 2
sigma = 0.5
alpha = (mu/sigma)**2
beta = mu / sigma**2
alpha, beta
(16.0, 8.0)
And confirm that it works.
from scipy.stats import gamma
gamma_dist = gamma(a=alpha, scale=1/beta)
gamma_dist.mean(), gamma_dist.std()
(2.0, 0.5)
Here are the two models compared. The gamma distribution is wider and slightly skewed to the right.
xs = np.linspace(0, 4, 101)
ps = norm.pdf(xs, 2, 0.1)
plt.plot(xs, ps, label='Normal')
ps = gamma_dist.pdf(xs)
plt.plot(xs, ps, label='Gamma')
decorate(xlabel='Arrival rate (per minute)', ylabel='PDF')
plt.savefig('red_line6.png', dpi=300)
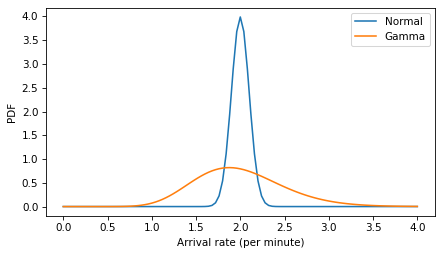
And here’s a version of the model with the gamma distribution of arrival rates (and the lognormal model of gap times).
# train gap time: Lognormal
# passenger arrival rate: Gamma
def make_model4(n_obs=10):
m, s = result1.x
with pm.Model() as model:
log_time = pm.Normal('log_time', mu=m, sigma=s)
gap_time = pm.Deterministic('gap_time', pm.math.exp(log_time))
elapsed_time = pm.Uniform('elapsed_time', lower=0, upper=gap_time)
remaining_time = pm.Deterministic('remaining_time', gap_time - elapsed_time)
rate = pm.Gamma('rate', alpha=alpha, beta=beta)
mu = elapsed_time * rate
n = pm.Poisson('n', mu=mu, observed=n_obs)
return model
Model 5: Log-t prior of gap times#
The normal model of gap times gives very low probabilities to very long gap times – longer than 15 minutes. The lognormal model admits the possibility of somewhat longer gap times, but not by much. In the real world, we know that systems often operate in two modes: an ordinary mode where measurements are never more than a few standard deviations from the mean, and extraordinary modes where measurements might come from a different distribution entirely. In the train scenario, extraordinary modes include many kinds of disruption of service.
We can model these scenarios with multi-modal distributions, or mixtures of distributions – but a versatile alternative is a Student-t distribution, which is similar to a normal distribution for values near the mean, but it can have a much thicker tail, admitting the possibility of extreme values.
A Student-t distribution on a log scale has the added advantage of being positive-valued, so let’s try that.
The tail parameter, nu, determines the thickness of the tails.
When nu is larger than about 30, the Student-t converges to a normal distribution. Values below 10 yield long tails. Values below 5 yield very long tail.
For more on the properties of these distributions, and how they apply to real data, see Chapter 8 of Probably Overthinking It, or this video from SciPy 2023.
To find the best Student-t for the data, we’ll use least_squares again.
nu = 7
from scipy.stats import t as student_t
def log_t_cdf(xs, m, s, nu):
return student_t.cdf(np.log(xs), loc=m, scale=s, df=nu)
def residuals(params, cdf_prior):
m, s = params
qs = cdf_prior.qs
ps = log_t_cdf(qs, m, s, nu=nu)
return ps - cdf_prior.ps
from scipy.optimize import least_squares
initial_guess = [m, s]
result2 = least_squares(residuals, initial_guess, args=(cdf_prior,))
assert result2.success == True
m2, s2 = result2.x
qs = cdf_prior.qs
ps = log_t_cdf(qs, m2, s2, nu=nu)
plt.plot(qs, ps, color='gray', label='log-t model')
cdf_prior.plot(label='KDE prior')
plt.fill_between(qs, low, high, color='C0', alpha=0.1, lw=0)
decorate(xlabel='Gap time (minutes)', ylabel='CDF')
plt.savefig('red_line7.png', dpi=300)
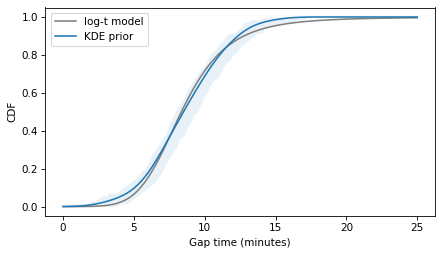
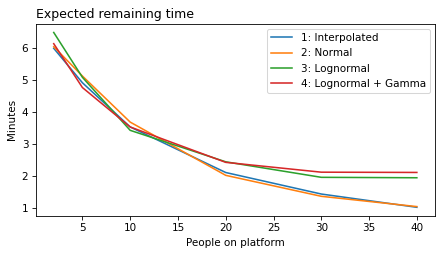
The Student-t model fits the data about as well as the lognormal model, and not as well as the normal model. So again there is a trade-off between the amenable properties of the distributions and fidelity to the data.
# train gap time: StudentT
# passenger arrival rate: Gamma
def make_model5(n_obs=10):
m, s = result2.x
with pm.Model() as model:
log_time = pm.StudentT('log_time', mu=m, sigma=s, nu=nu)
gap_time = pm.Deterministic('gap_time', pm.math.exp(log_time))
elapsed_time = pm.Uniform('elapsed_time', lower=0, upper=gap_time)
remaining_time = pm.Deterministic('remaining_time', gap_time - elapsed_time)
rate = pm.Gamma('rate', alpha=alpha, beta=beta)
mu = elapsed_time * rate
n = pm.Poisson('n', mu=mu, observed=n_obs)
return model
Run the model#
In the following cell, choose the model you want to run.
make_model = make_model1
model_name = make_model.__name__.split('_')[1]
model = make_model(n_obs=10)
pm.model_to_graphviz(model)

graph = pm.model_to_graphviz(model)
graph.render(model_name, format='png')
'model1.png'
First we’ll sample from the prior and prior predictive distributions.
with model:
idata = pm.sample_prior_predictive()
Sampling: [elapsed_time, gap_time, n, rate]
gap_times = idata['prior']['gap_time'].values.flatten()
np.mean(gap_times)
8.812407053329704
kde_gap_time = gaussian_kde(gap_times)
plot_kde(kde_gap_time, label='interpolated', color='gray')
plot_kde(kde_prior, label='observed')
decorate(xlabel='Gap between trains (minutes)')
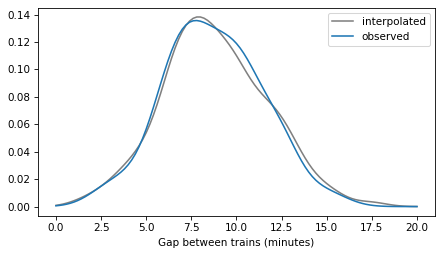
elapsed_times = idata.prior['elapsed_time'].values.flatten()
np.mean(elapsed_times)
4.481724809482283
ns = idata.prior_predictive['n'].values.flatten()
np.mean(ns)
8.934
Now sample from the posterior distribution
with model:
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
import arviz as az
az.summary(idata)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rate | 2.002 | 0.098 | 1.811 | 2.182 | 0.002 | 0.001 | 2816.0 | 2319.0 | 1.0 |
| gap_time | 8.755 | 2.439 | 4.667 | 13.424 | 0.052 | 0.038 | 2235.0 | 1516.0 | 1.0 |
| elapsed_time | 5.121 | 1.493 | 2.474 | 7.908 | 0.022 | 0.017 | 4501.0 | 3362.0 | 1.0 |
| remaining_time | 3.634 | 2.455 | 0.001 | 7.858 | 0.055 | 0.039 | 1842.0 | 1519.0 | 1.0 |
var_names=['gap_time', 'elapsed_time', 'remaining_time']
az.plot_trace(idata, var_names=var_names)
plt.tight_layout()
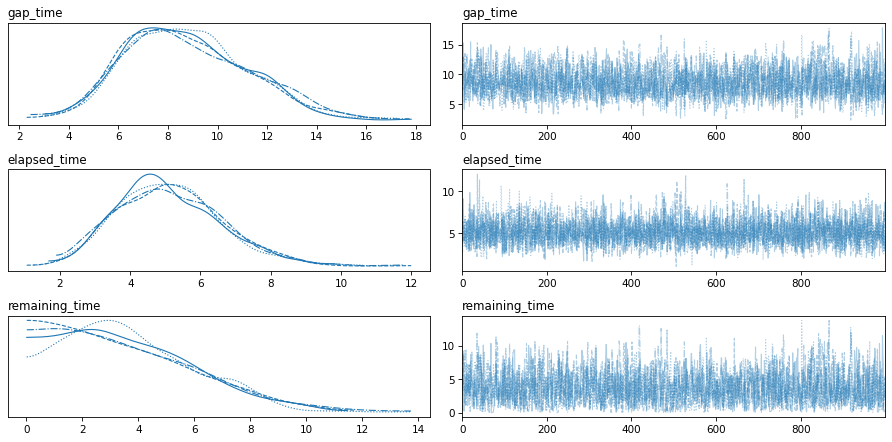
Here are the posterior distributions for the key parameters.
az.plot_posterior(idata, var_names=['remaining_time'])
plt.tight_layout()
plt.savefig('red_line9.png', dpi=300)
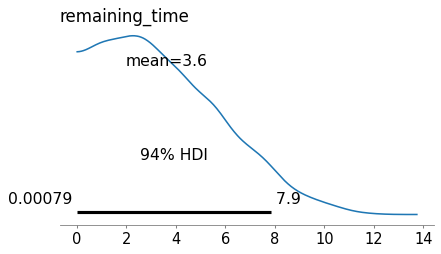
To compute the posterior distribution of the remaining time – which is what we are primarily interested in – we have to extract the samples of gap_time and elapsed_time and subtract them elementwise.
def get_sample(idata, var_name):
"""Extract a posterior sample from idata
idata: InferenceData object
var_name: string
returns: NumPy array
"""
return idata.posterior[var_name].values.flatten()
gap_times = get_sample(idata, 'gap_time')
np.mean(gap_times)
8.754988603964444
elapsed_times = get_sample(idata, 'elapsed_time')
np.mean(elapsed_times)
5.121400416305409
remaining_times = get_sample(idata, 'remaining_time')
np.mean(remaining_times)
3.633588187659036
Here’s what the posterior distributions look like.
import seaborn as sns
sns.kdeplot(gap_times, label='gap')
sns.kdeplot(elapsed_times, label='elapsed')
sns.kdeplot(remaining_times, label='remaining', cut=0)
decorate(xlabel='Gap between trains (minutes)')
plt.savefig('red_line3.png', dpi=300)
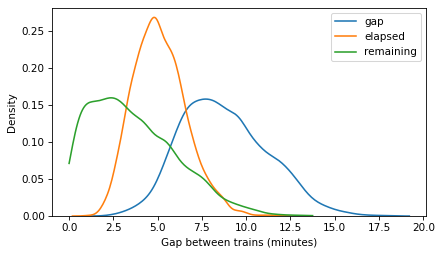
Correlations#
It is common practice to look at posterior marginal distributions, but often there are non-negligible correlations among the sampled values. For example, in models 4 and 5, we are uncertain about the rate of passenger arrivals, which means that there are two possible explanations if we see more passengers than usual: maybe it’s been a while since the last train, or maybe passengers have arrived faster than expects. So in these models, we expect to see a negative correlation between these parameters.
To find out, let’s run model4 with n=40.
make_model = make_model4
model_name = make_model.__name__.split('_')[1]
model = make_model(n_obs=40)
with model:
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
And extract the posterior samples.
gap_times = get_sample(idata, 'gap_time')
np.mean(gap_times)
15.452587782018568
elapsed_times = get_sample(idata, 'elapsed_time')
np.mean(elapsed_times)
13.398551865339813
remaining_times = get_sample(idata, 'remaining_time')
np.mean(remaining_times)
2.0540359166787554
rates = get_sample(idata, 'rate')
np.mean(rates)
2.657591840877828
Here are the correlations.
np.corrcoef([gap_times, elapsed_times, remaining_times, rates])
array([[ 1. , 0.81251204, 0.55163458, -0.55434647],
[ 0.81251204, 1. , -0.03801598, -0.67941241],
[ 0.55163458, -0.03801598, 1. , 0.02185898],
[-0.55434647, -0.67941241, 0.02185898, 1. ]])
To show the relationship between elapsed time and arrival rate, let’s make a contour plot of their joint distribution.
def joint_contour(x, y):
data = np.vstack([x, y])
kde = gaussian_kde(data)
xs = np.linspace(x.min(), x.max(), 101)
ys = np.linspace(y.min(), y.max(), 101)
X, Y = np.meshgrid(xs, ys, indexing='ij')
positions = np.vstack([X.ravel(), Y.ravel()])
kde_values = kde(positions).reshape(X.shape)
plt.contour(X, Y, kde_values, cmap='Blues')
joint_contour(elapsed_times, rates)
decorate(xlabel='Elapsed time (minutes)', ylabel='Arrival rate (per minute)')
plt.savefig('redline8.png', dpi=300)
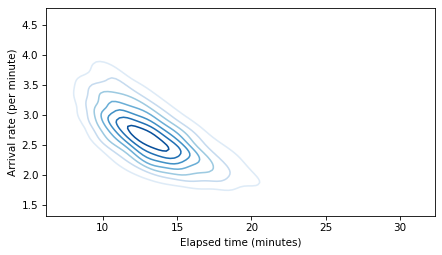
The result is a shape I call the banana of ignorance: because there are two possible explanations for the data, the joint distribution of the two parameters makes a hyperbola that looks a little like a banana.
Run with a range of n#
The following function runs the model with a range of values for n_obs and writes the results as DataFrames in an HDF file.
def run_model(make_model_func):
"""Run the model and save results
make_model_func: function that makes the model
"""
gap_df = pd.DataFrame(dtype='float')
elapsed_df = pd.DataFrame(dtype='float')
remaining_df = pd.DataFrame(dtype='float')
rate_df = pd.DataFrame(dtype='float')
# run the model with a range of n_obs
for n_obs in [2, 5, 10, 20, 30, 40]:
print(n_obs)
model = make_model_func(n_obs)
with model:
idata = pm.sample(500, tune=500)
gap_times = get_sample(idata, 'gap_time')
gap_df[n_obs] = gap_times
elapsed_times = get_sample(idata, 'elapsed_time')
elapsed_df[n_obs] = elapsed_times
remaining_df[n_obs] = gap_times - elapsed_times
rate_df[n_obs] = get_sample(idata, 'rate')
# save the results in an HDF file
model_name = make_model_func.__name__.split('_')[1]
varnames = ['gap', 'elapsed', 'remaining', 'rate']
dataframes = [gap_df, elapsed_df, remaining_df, rate_df]
for varname, df in zip(varnames, dataframes):
key = f'{model_name}_{varname}'
df.to_hdf('redline.hdf', key=key)
Run all of the models.
make_model_funcs = [make_model1, make_model2, make_model3, make_model4, make_model5]
for make_model_func in make_model_funcs:
run_model(make_model_func)
2
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
There were 37 divergences after tuning. Increase `target_accept` or reparameterize.
5
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
There were 4 divergences after tuning. Increase `target_accept` or reparameterize.
10
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
20
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
30
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
40
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
2
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
There were 70 divergences after tuning. Increase `target_accept` or reparameterize.
5
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
There were 6 divergences after tuning. Increase `target_accept` or reparameterize.
10
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
20
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
30
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
40
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [gap_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
2
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
5
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
10
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
20
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
30
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
40
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
2
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
5
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
10
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
20
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 2 seconds.
30
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
40
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
2
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
5
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
10
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
20
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
30
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
40
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [log_time, elapsed_time, rate]
Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 1 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
The following function reads a result back from the HDF file.
def get_result(model_name, varname):
"""Read a result from the HDF file
model_name: string like 'model1'
varname: string, one of 'gap', 'elapsed', 'remaining', or 'rate'
"""
key = f'{model_name}_{varname}'
return pd.read_hdf('redline.hdf', key=key)
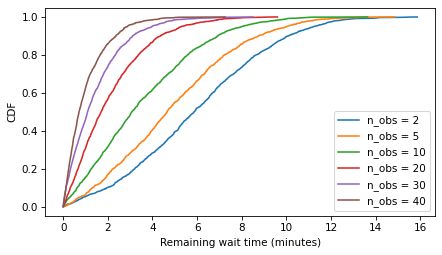
Here are the distributions of remaining time for model1 with a range of n_obs.
from empiricaldist import Cdf
def plot_cdfs(model_name, varname):
df = get_result(model_name, varname)
for n_obs, sample in df.items():
cdf = Cdf.from_seq(sample)
cdf.plot(label=f'n_obs = {n_obs}')
decorate(ylabel='CDF')
plot_cdfs('model1', 'remaining')
decorate(xlabel='Remaining wait time (minutes)')
Plot results#
Now, to summarize the results, the following function computes the mean of the given variable over a range of n_obs, for a given model.
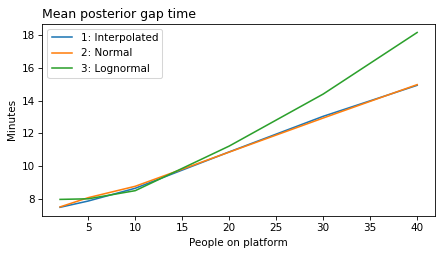
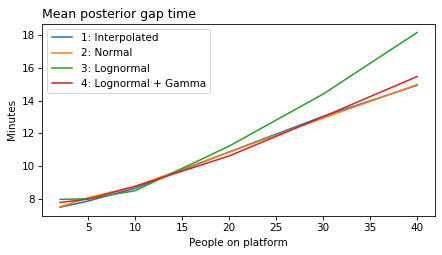
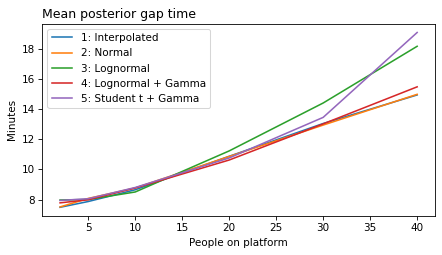
label_dict = {
'model1': '1: Interpolated',
'model2': '2: Normal',
'model3': '3: Lognormal',
'model4': '4: Lognormal + Gamma',
'model5': '5: Student t + Gamma',
}
def plot_model_results(models, varname):
"""Plot a metric over `n_obs`
models: list of model numbers
varname: string, one of 'gap', 'elapsed', 'remaining', or 'rate'
"""
for i in models:
model_name = f'model{i}'
df = get_result(model_name, varname)
df.mean().plot(label=label_dict[model_name])
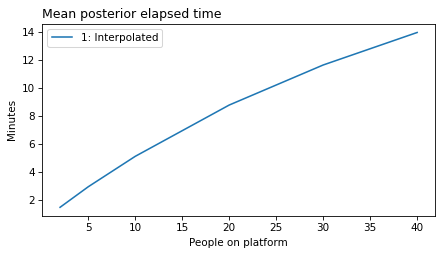
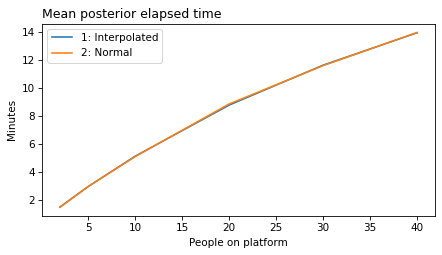
plot_model_results([1], 'elapsed')
decorate(xlabel='People on platform',
ylabel='Mean posterior elapsed time')
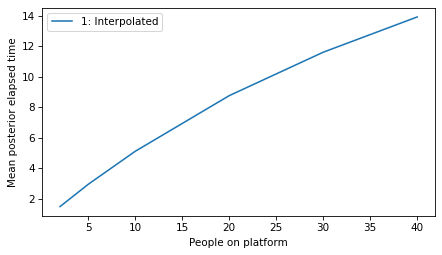
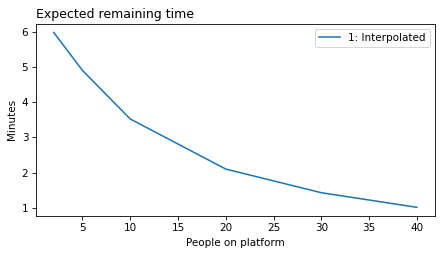
plot_model_results([1], 'remaining')
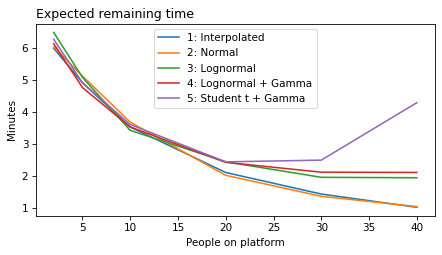
decorate(xlabel='People on platform', ylabel='Expected remaining time')
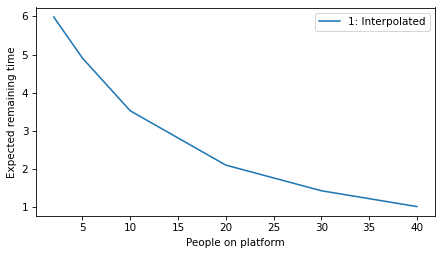
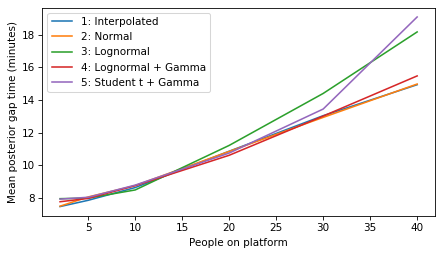
All models#
all_models = range(1, 6)
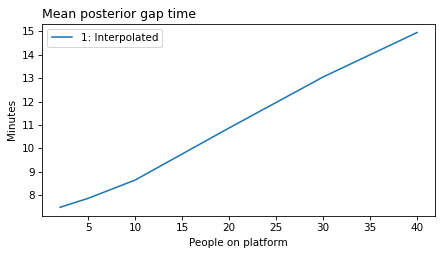
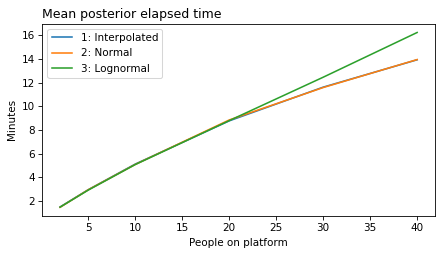
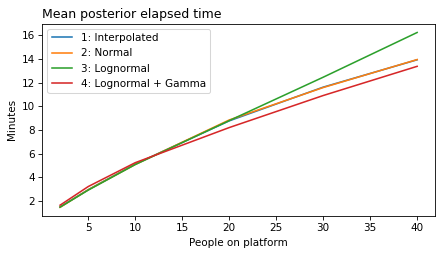
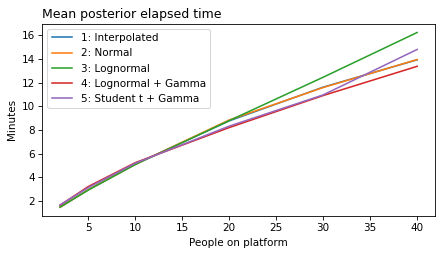
plot_model_results(all_models, 'gap')
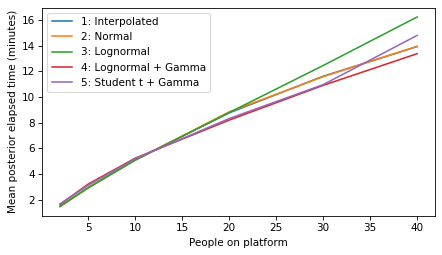
decorate(xlabel='People on platform', ylabel='Mean posterior gap time (minutes)')
plot_model_results(all_models, 'elapsed')
decorate(xlabel='People on platform', ylabel='Mean posterior elapsed time (minutes)')
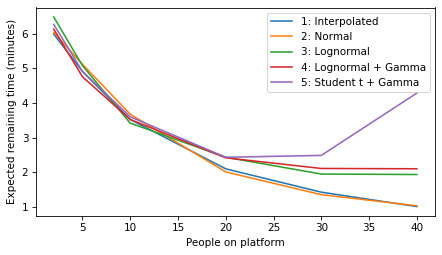
plot_model_results(all_models, 'remaining')
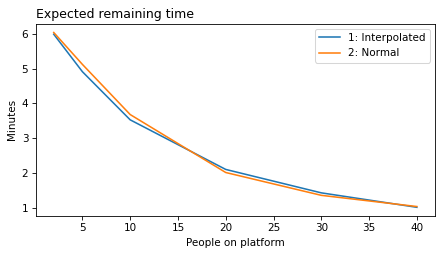
decorate(xlabel='People on platform', ylabel='Expected remaining time (minutes)')
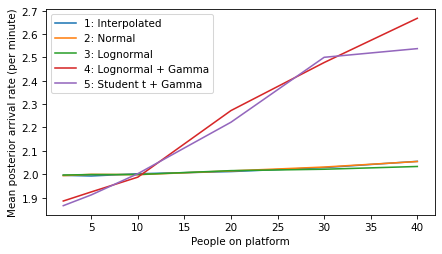
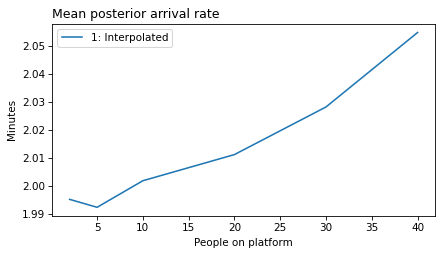
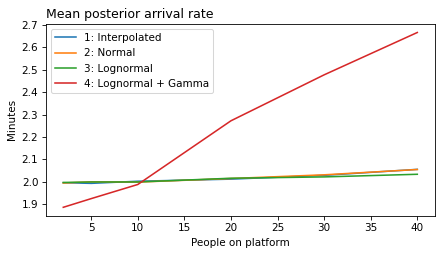
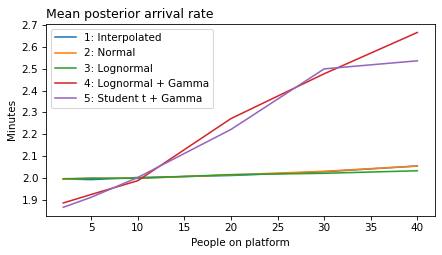
plot_model_results(all_models, 'rate')
decorate(xlabel='People on platform', ylabel='Mean posterior arrival rate (per minute)')
Make figures for the talk#
title_dict = {
'gap': 'Mean posterior gap time',
'elapsed': 'Mean posterior elapsed time',
'remaining': 'Expected remaining time',
'rate': 'Mean posterior arrival rate',
}
unit_dict = {
'rate': 'Per minute',
}
def make_figures(varname):
ylabel = unit_dict.get(varname, 'Minutes')
for i in range(1, 6):
models = range(1, i+1)
plt.figure()
plot_model_results(models, varname)
decorate(xlabel='People on platform',
ylabel='Minutes',
title=title_dict[varname])
filename = f'red_line_{varname}_{i}.png'
# print(filename)
plt.savefig(filename, dpi=300)
make_figures('gap')
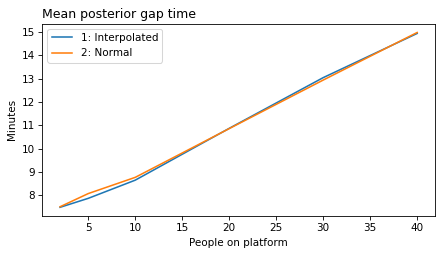
make_figures('elapsed')
make_figures('remaining')
make_figures('rate')
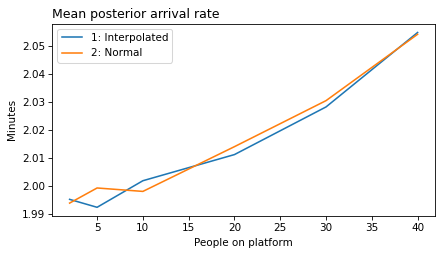
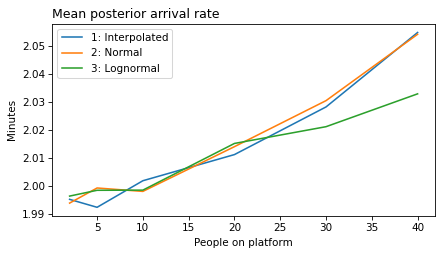
Think Bayes, Second Edition
Copyright 2024 Allen B. Downey
License: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)