You can order print and ebook versions of Think Bayes 2e from Bookshop.org and Amazon.
17. Regression#
In the previous chapter we saw several examples of logistic regression, which is based on the assumption that the likelihood of an outcome, expressed in the form of log odds, is a linear function of some quantity (continuous or discrete).
In this chapter we’ll work on examples of simple linear regression, which models the relationship between two quantities. Specifically, we’ll look at changes over time in snowfall and the marathon world record.
The models we’ll use have three parameters, so you might want to review the tools we used for the three-parameter model in <<_MarkandRecapture>>.
17.1. More Snow?#
I am under the impression that we don’t get as much snow around here as we used to. By “around here” I mean Norfolk County, Massachusetts, where I was born, grew up, and currently live. And by “used to” I mean compared to when I was young, like in 1978 when we got 27 inches of snow and I didn’t have to go to school for a couple of weeks.
Fortunately, we can test my conjecture with data. Norfolk County happens to be the location of the Blue Hill Meteorological Observatory, which keeps the oldest continuous weather record in North America.
Data from this and many other weather stations is available from the National Oceanic and Atmospheric Administration (NOAA). I collected data from the Blue Hill Observatory from May 11, 1967 to May 11, 2020.
The following cell downloads the data as a CSV file.
We can use Pandas to read the data into DataFrame:
import pandas as pd
df = pd.read_csv('2239075.csv', parse_dates=[2])
Here’s what the last few rows look like.
The columns we’ll use are:
DATE, which is the date of each observation,SNOW, which is the total snowfall in inches.
I’ll add a column that contains just the year part of the dates.
df['YEAR'] = df['DATE'].dt.year
And use groupby to add up the total snowfall in each year.
snow = df.groupby('YEAR')['SNOW'].sum()
The first and last years are not complete, so I’ll drop them.
The following figure shows total snowfall during each of the complete years in my lifetime.
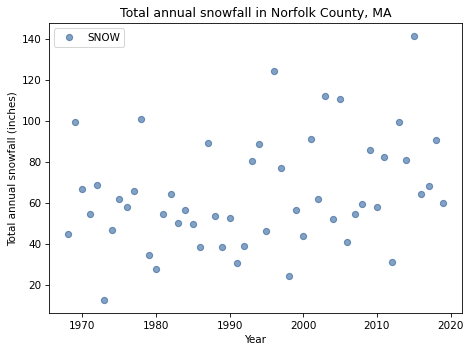
Looking at this plot, it’s hard to say whether snowfall is increasing, decreasing, or unchanged. In the last decade, we’ve had several years with more snow than 1978, including 2015, which was the snowiest winter in the Boston area in modern history, with a total of 141 inches.
This kind of question – looking at noisy data and wondering whether it is going up or down – is precisely the question we can answer with Bayesian regression.
17.2. Regression Model#
The foundation of regression (Bayesian or not) is the assumption that a time series like this is the sum of two parts:
A linear function of time, and
A series of random values drawn from a distribution that is not changing over time.
Mathematically, the regression model is
where \(y\) is the series of measurements (snowfall in this example), \(x\) is the series of times (years) and \(\epsilon\) is the series of random values.
\(a\) and \(b\) are the slope and intercept of the line through the data. They are unknown parameters, so we will use the data to estimate them.
We don’t know the distribution of \(\epsilon\), so we’ll make the additional assumption that it is a normal distribution with mean 0 and unknown standard deviation, \(\sigma\).
To see whether this assumption is reasonable, I’ll plot the distribution of total snowfall and a normal model with the same mean and standard deviation.
Here’s a Pmf object that represents the distribution of snowfall.
from empiricaldist import Pmf
pmf_snowfall = Pmf.from_seq(snow)
And here are the mean and standard deviation of the data.
mean, std = pmf_snowfall.mean(), pmf_snowfall.std()
mean, std
(64.19038461538462, 26.28802198439569)
I’ll use the norm object from SciPy to compute the CDF of a normal distribution with the same mean and standard deviation.
from scipy.stats import norm
dist = norm(mean, std)
qs = pmf_snowfall.qs
ps = dist.cdf(qs)
Here’s what the distribution of the data looks like compared to the normal model.
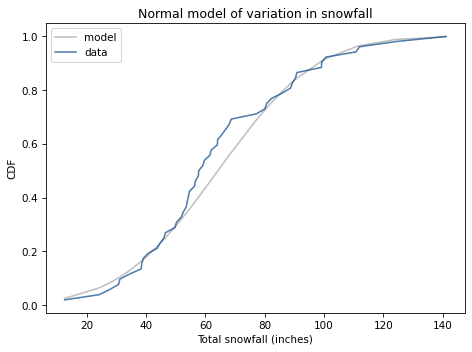
We’ve had more winters below the mean than expected, but overall this looks like a reasonable model.
17.3. Least Squares Regression#
Our regression model has three parameters: slope, intercept, and standard deviation of \(\epsilon\). Before we can estimate them, we have to choose priors. To help with that, I’ll use StatsModel to fit a line to the data by least squares regression.
First, I’ll use reset_index to convert snow, which is a Series, to a DataFrame.
data = snow.reset_index()
data.head(3)
| YEAR | SNOW | |
|---|---|---|
| 0 | 1968 | 44.7 |
| 1 | 1969 | 99.2 |
| 2 | 1970 | 66.8 |
The result is a DataFrame with two columns, YEAR and SNOW, in a format we can use with StatsModels.
As we did in the previous chapter, I’ll center the data by subtracting off the mean.
offset = round(data['YEAR'].mean())
data['x'] = data['YEAR'] - offset
offset
1994
And I’ll add a column to data so the dependent variable has a standard name.
data['y'] = data['SNOW']
Now, we can use StatsModels to compute the least squares fit to the data and estimate slope and intercept.
import statsmodels.formula.api as smf
formula = 'y ~ x'
results = smf.ols(formula, data=data).fit()
results.params
Intercept 64.446325
x 0.511880
dtype: float64
The intercept, about 64 inches, is the expected snowfall when x=0, which is the beginning of 1994.
The estimated slope indicates that total snowfall is increasing at a rate of about 0.5 inches per year.
results also provides resid, which is an array of residuals, that is, the differences between the data and the fitted line.
The standard deviation of the residuals is an estimate of sigma.
results.resid.std()
25.385680731210623
We’ll use these estimates to choose prior distributions for the parameters.
17.4. Priors#
I’ll use uniform distributions for all three parameters.
import numpy as np
from utils import make_uniform
qs = np.linspace(-0.5, 1.5, 51)
prior_slope = make_uniform(qs, 'Slope')
qs = np.linspace(54, 75, 41)
prior_inter = make_uniform(qs, 'Intercept')
qs = np.linspace(20, 35, 31)
prior_sigma = make_uniform(qs, 'Sigma')
I made the prior distributions different lengths for two reasons. First, if we make a mistake and use the wrong distribution, it will be easier to catch the error if they are all different lengths.
Second, it provides more precision for the most important parameter, slope, and spends less computational effort on the least important, sigma.
In <<_ThreeParameterModel>> we made a joint distribution with three parameters. I’ll wrap that process in a function:
from utils import make_joint
def make_joint3(pmf1, pmf2, pmf3):
"""Make a joint distribution with three parameters."""
joint2 = make_joint(pmf2, pmf1).stack()
joint3 = make_joint(pmf3, joint2).stack()
return Pmf(joint3)
And use it to make a Pmf that represents the joint distribution of the three parameters.
prior = make_joint3(prior_slope, prior_inter, prior_sigma)
prior.head(3)
| probs | |||
|---|---|---|---|
| Slope | Intercept | Sigma | |
| -0.5 | 54.0 | 20.0 | 0.000015 |
| 20.5 | 0.000015 | ||
| 21.0 | 0.000015 |
The index of Pmf has three columns, containing values of slope, inter, and sigma, in that order.
With three parameters, the size of the joint distribution starts to get big. Specifically, it is the product of the lengths of the prior distributions. In this example, the prior distributions have 51, 41, and 31 values, so the length of the joint prior is 64,821.
17.5. Likelihood#
Now we’ll compute the likelihood of the data. To demonstrate the process, let’s assume temporarily that the parameters are known.
inter = 64
slope = 0.51
sigma = 25
I’ll extract the xs and ys from data as Series objects:
xs = data['x']
ys = data['y']
And compute the “residuals”, which are the differences between the actual values, ys, and the values we expect based on slope and inter.
expected = slope * xs + inter
resid = ys - expected
According to the model, the residuals should follow a normal distribution with mean 0 and standard deviation sigma. So we can compute the likelihood of each residual value using norm from SciPy.
densities = norm(0, sigma).pdf(resid)
The result is an array of probability densities, one for each element of the dataset; their product is the likelihood of the data.
likelihood = densities.prod()
likelihood
1.3551948769060997e-105
As we saw in the previous chapter, the likelihood of any particular dataset tends to be small. If it’s too small, we might exceed the limits of floating-point arithmetic. When that happens, we can avoid the problem by computing likelihoods under a log transform. But in this example that’s not necessary.
17.6. The Update#
Now we’re ready to do the update. First, we need to compute the likelihood of the data for each possible set of parameters.
likelihood = prior.copy()
for slope, inter, sigma in prior.index:
expected = slope * xs + inter
resid = ys - expected
densities = norm.pdf(resid, 0, sigma)
likelihood[slope, inter, sigma] = densities.prod()
This computation takes longer than many of the previous examples. We are approaching the limit of what we can do with grid approximations.
Nevertheless, we can do the update in the usual way:
posterior = prior * likelihood
posterior.normalize()
The result is a Pmf with a three-level index containing values of slope, inter, and sigma.
To get the marginal distributions from the joint posterior, we can use Pmf.marginal, which we saw in <<_ThreeParameterModel>>.
posterior_slope = posterior.marginal(0)
posterior_inter = posterior.marginal(1)
posterior_sigma = posterior.marginal(2)
Here’s the posterior distribution for sigma:
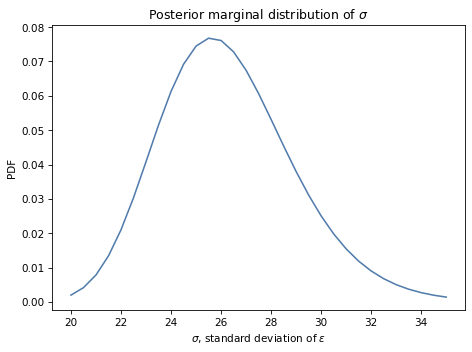
The most likely values for sigma are near 26 inches, which is consistent with our estimate based on the standard deviation of the data.
However, to say whether snowfall is increasing or decreasing, we don’t really care about sigma. It is a “nuisance parameter”, so-called because we have to estimate it as part of the model, but we don’t need it to answer the questions we are interested in.
Nevertheless, it is good to check the marginal distributions to make sure
The location is consistent with our expectations, and
The posterior probabilities are near 0 at the extremes of the range, which indicates that the prior distribution covers all parameters with non-negligible probability.
In this example, the posterior distribution of sigma looks fine.
Here’s the posterior distribution of inter:
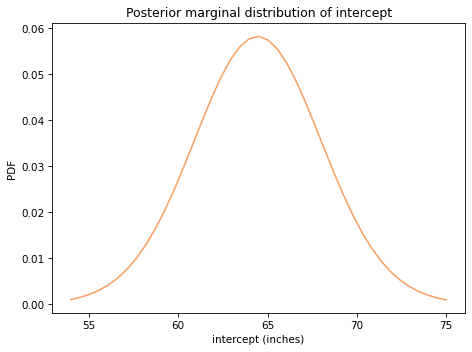
The posterior mean is about 64 inches, which is the expected amount of snow during the year at the midpoint of the range, 1994.
And finally, here’s the posterior distribution of slope:
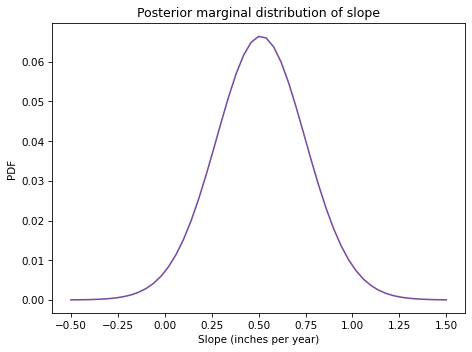
The posterior mean is about 0.51 inches, which is consistent with the estimate we got from least squared regression.
The 90% credible interval is from 0.1 to 0.9, which indicates that our uncertainty about this estimate is pretty high. In fact, there is still a small posterior probability (about 2%) that the slope is negative.
However, it is more likely that my conjecture was wrong: we are actually getting more snow around here than we used to, increasing at a rate of about a half-inch per year, which is substantial. On average, we get an additional 25 inches of snow per year than we did when I was young.
This example shows that with slow-moving trends and noisy data, your instincts can be misleading.
Now, you might suspect that I overestimate the amount of snow when I was young because I enjoyed it, and underestimate it now because I don’t. But you would be mistaken.
During the Blizzard of 1978, we did not have a snowblower and my brother and I had to shovel. My sister got a pass for no good reason. Our driveway was about 60 feet long and three cars wide near the garage. And we had to shovel Mr. Crocker’s driveway, too, for which we were not allowed to accept payment. Furthermore, as I recall it was during this excavation that I accidentally hit my brother with a shovel on the head, and it bled a lot because, you know, scalp wounds.
Anyway, the point is that I don’t think I overestimate the amount of snow when I was young because I have fond memories of it.
17.7. Optimization#
The way we computed the likelihood in the previous section was pretty slow. The problem is that we looped through every possible set of parameters in the prior distribution, and there were more than 60,000 of them.
If we can do more work per iteration, and run the loop fewer times, we expect it to go faster.
In order to do that, I’ll unstack the prior distribution:
The result is a DataFrame with slope and intercept down the rows and sigmas across the columns.
The following is a version of likelihood_regression that takes the joint prior distribution in this form and returns the posterior distribution in the same form.
This version loops through all possible pairs of slope and inter, so the loop runs about 2000 times.
Each time through the loop, it uses a grid mesh to compute the likelihood of the data for all values of sigma. The result is an array with one column for each data point and one row for each value of sigma. Taking the product across the columns (axis=1) yields the probability of the data for each value of sigma, which we assign as a row in likelihood.
We get the same result either way.
But this version is about 25 times faster than the previous version.
This optimization works because many functions in NumPy and SciPy are written in C, so they run fast compared to Python. If you can do more work each time you call these functions, and less time running the loop in Python, your code will often run substantially faster.
In this version of the posterior distribution, slope and inter run down the rows and sigma runs across the columns. So we can use marginal to get the posterior joint distribution of slope and intercept.
The result is a Pmf with two columns in the index.
To plot it, we have to unstack it.
Here’s what it looks like.
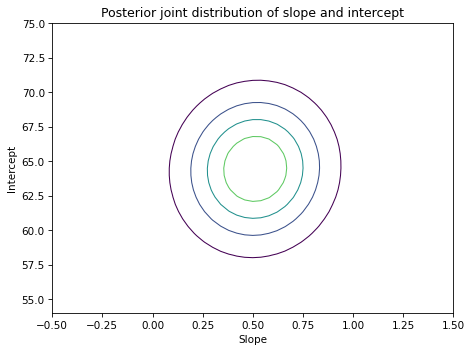
The ovals in the contour plot are aligned with the axes, which indicates that there is no correlation between slope and inter in the posterior distribution, which is what we expect since we centered the values.
In this example, the motivating question is about the slope of the line, so we answered it by looking at the posterior distribution of slope.
In the next example, the motivating question is about prediction, so we’ll use the joint posterior distribution to generate predictive distributions.
17.8. Marathon World Record#
For many running events, if you plot the world record pace over time, the result is a remarkably straight line. People, including me, have speculated about possible reasons for this phenomenon.
People have also speculated about when, if ever, the world record time for the marathon will be less than two hours. (Note: In 2019 Eliud Kipchoge ran the marathon distance in under two hours, which is an astonishing achievement that I fully appreciate, but for several reasons it did not count as a world record).
So, as a second example of Bayesian regression, we’ll consider the world record progression for the marathon (for male runners), estimate the parameters of a linear model, and use the model to predict when a runner will break the two-hour barrier.
The following cell downloads a web page from Wikipedia that includes a table of marathon world records, and uses Pandas to put the data in a DataFrame.
url = "https://github.com/AllenDowney/ThinkBayes2/raw/master/data/Marathon_world_record_progression.html"
The first table is the one we want.
We can use Pandas to parse the dates.
A few of them include notes that cause parsing problems, but the argument errors='coerce' tells Pandas to fill invalid dates with NaT, which is a version of NaN that represents “not a time”.
We can also use Pandas to parse the record times.
And convert the times to paces in miles per hour.
The following function plots the results.
Here’s what the results look like. The dashed line shows the speed required for a two-hour marathon, 13.1 miles per hour.
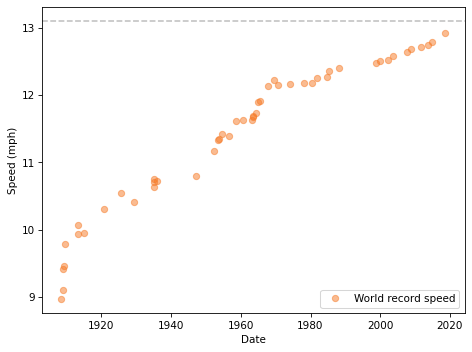
It’s not a perfectly straight line. In the early years of the marathon, the record speed increased quickly; since about 1970, it has been increasing more slowly.
For our analysis, let’s focus on the recent progression, starting in 1970.
In the notebook for this chapter, you can see how I loaded and cleaned the data. The result is a DataFrame that contains the following columns (and additional information we won’t use):
date, which is a PandasTimestamprepresenting the date when the world record was broken, andspeed, which records the record-breaking pace in mph.
Here’s what the results look like, starting in 1970:
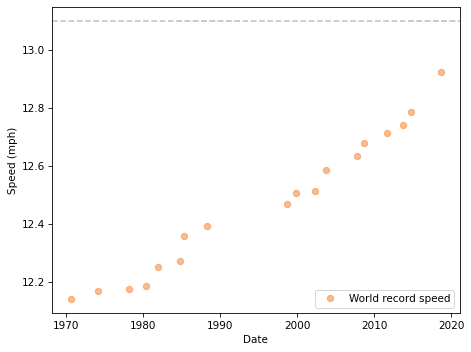
The data points fall approximately on a line, although it’s possible that the slope is increasing.
To prepare the data for regression, I’ll subtract away the approximate midpoint of the time interval, 1995.
offset = pd.to_datetime('1995')
timedelta = table['date'] - offset
When we subtract two Timestamp objects, the result is a “time delta”, which we can convert to seconds and then to years.
data['x'] = timedelta.dt.total_seconds() / 3600 / 24 / 365.24
As in the previous example, I’ll use least squares regression to compute point estimates for the parameters, which will help with choosing priors.
import statsmodels.formula.api as smf
formula = 'y ~ x'
results = smf.ols(formula, data=data).fit()
results.params
Intercept 12.460507
x 0.015464
dtype: float64
The estimated intercept is about 12.5 mph, which is the interpolated world record pace for 1995. The estimated slope is about 0.015 mph per year, which is the rate the world record pace is increasing, according to the model.
Again, we can use the standard deviation of the residuals as a point estimate for sigma.
results.resid.std()
0.041399612201932
These parameters give us a good idea where we should put the prior distributions.
17.9. The Priors#
Here are the prior distributions I chose for slope, intercept, and sigma.
qs = np.linspace(0.012, 0.018, 51)
prior_slope = make_uniform(qs, 'Slope')
qs = np.linspace(12.4, 12.5, 41)
prior_inter = make_uniform(qs, 'Intercept')
qs = np.linspace(0.01, 0.21, 31)
prior_sigma = make_uniform(qs, 'Sigma')
And here’s the joint prior distribution.
prior = make_joint3(prior_slope, prior_inter, prior_sigma)
prior.head()
| probs | |||
|---|---|---|---|
| Slope | Intercept | Sigma | |
| 0.012 | 12.4 | 0.010000 | 0.000015 |
| 0.016667 | 0.000015 | ||
| 0.023333 | 0.000015 |
Now we can compute likelihoods as in the previous example:
xs = data['x']
ys = data['y']
likelihood = prior.copy()
for slope, inter, sigma in prior.index:
expected = slope * xs + inter
resid = ys - expected
densities = norm.pdf(resid, 0, sigma)
likelihood[slope, inter, sigma] = densities.prod()
Now we can do the update in the usual way.
posterior = prior * likelihood
posterior.normalize()
And unpack the marginals:
posterior_slope = posterior.marginal(0)
posterior_inter = posterior.marginal(1)
posterior_sigma = posterior.marginal(2)
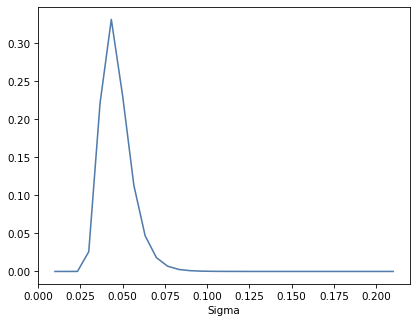
Here’s the posterior distribution of inter:
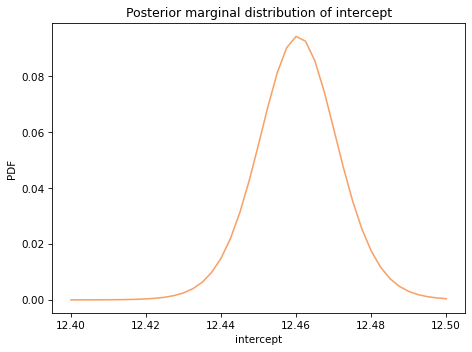
The posterior mean is about 12.5 mph, which is the world record marathon pace the model predicts for the midpoint of the date range, 1994.
And here’s the posterior distribution of slope.
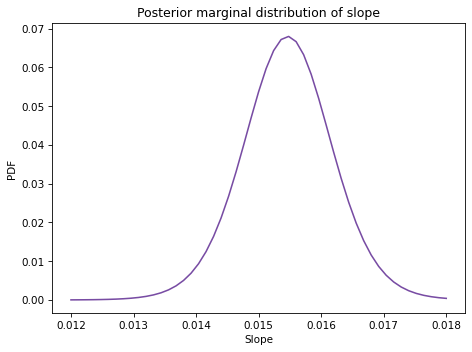
The posterior mean is about 0.015 mph per year, or 0.15 mph per decade.
That’s interesting, but it doesn’t answer the question we’re interested in: When will there be a two-hour marathon? To answer that, we have to make predictions.
17.10. Prediction#
To generate predictions, I’ll draw a sample from the posterior distribution of parameters, then use the regression equation to combine the parameters with the data.
Pmf provides choice, which we can use to draw a random sample with replacement, using the posterior probabilities as weights.
sample = posterior.choice(101)
The result is an array of tuples. Looping through the sample, we can use the regression equation to generate predictions for a range of xs.
xs = np.arange(-25, 50, 2)
pred = np.empty((len(sample), len(xs)))
for i, (slope, inter, sigma) in enumerate(sample):
epsilon = norm(0, sigma).rvs(len(xs))
pred[i] = inter + slope * xs + epsilon
Each prediction is an array with the same length as xs, which I store as a row in pred. So the result has one row for each sample and one column for each value of x.
We can use percentile to compute the 5th, 50th, and 95th percentiles in each column.
low, median, high = np.percentile(pred, [5, 50, 95], axis=0)
To show the results, I’ll plot the median of the predictions as a line and the 90% credible interval as a shaded area.
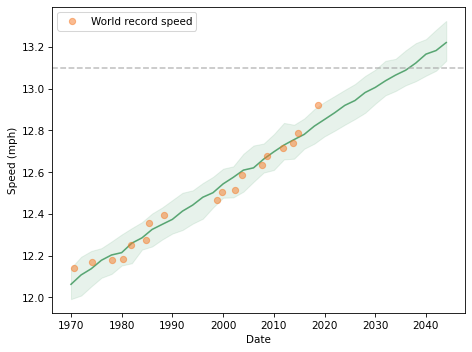
The dashed line shows the two-hour marathon pace, which is 13.1 miles per hour. Visually we can estimate that the prediction line hits the target pace between 2030 and 2040.
To make this more precise, we can use interpolation to see when the predictions cross the finish line. SciPy provides interp1d, which does linear interpolation by default.
from scipy.interpolate import interp1d
future = np.array([interp1d(high, xs)(13.1),
interp1d(median, xs)(13.1),
interp1d(low, xs)(13.1)])
The median prediction is 2036, with a 90% credible interval from 2032 to 2043. So there is about a 5% chance we’ll see a two-hour marathon before 2032.
17.11. Summary#
This chapter introduces Bayesian regression, which is based on the same model as least squares regression; the difference is that it produces a posterior distribution for the parameters rather than point estimates.
In the first example, we looked at changes in snowfall in Norfolk County, Massachusetts, and concluded that we get more snowfall now than when I was young, contrary to my expectation.
In the second example, we looked at the progression of world record pace for the men’s marathon, computed the joint posterior distribution of the regression parameters, and used it to generate predictions for the next 20 years.
These examples have three parameters, so it takes a little longer to compute the likelihood of the data. With more than three parameters, it becomes impractical to use grid algorithms.
In the next few chapters, we’ll explore other algorithms that reduce the amount of computation we need to do a Bayesian update, which makes it possible to use models with more parameters.
But first, you might want to work on these exercises.
17.12. Exercises#
Exercise: I am under the impression that it is warmer around here than it used to be. In this exercise, you can put my conjecture to the test.
We’ll use the same dataset we used to model snowfall; it also includes daily low and high temperatures in Norfolk County, Massachusetts during my lifetime.
Here’s the data.
Again, I’ll create a column that contains the year part of the dates.
This dataset includes TMIN and TMAX, which are the daily low and high temperatures in degrees F.
I’ll create a new column with the daily midpoint of the low and high temperatures.
Now we can group by year and compute the mean of these daily temperatures.
Again, I’ll drop the first and last years, which are incomplete.
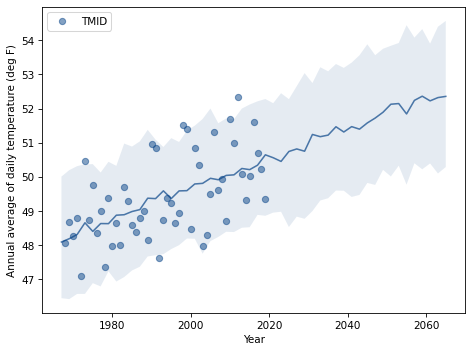
Here’s what the time series looks like.

As we did with the snow data, I’ll convert the Series to a DataFrame to prepare it for regression.
Now we can use StatsModels to estimate the parameters.
And compute the standard deviation of the parameters.
According to the least squares regression model, annual average temperature is increasing by about 0.044 degrees F per year.
To quantify the uncertainty of these parameters and generate predictions for the future, we can use Bayesian regression.
Use StatsModels to generate point estimates for the regression parameters.
Choose priors for
slope,intercept, andsigmabased on these estimates, and usemake_joint3to make a joint prior distribution.Compute the likelihood of the data and compute the posterior distribution of the parameters.
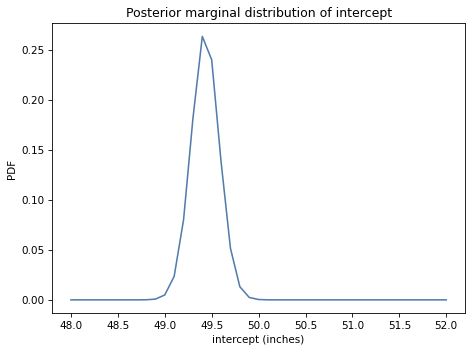
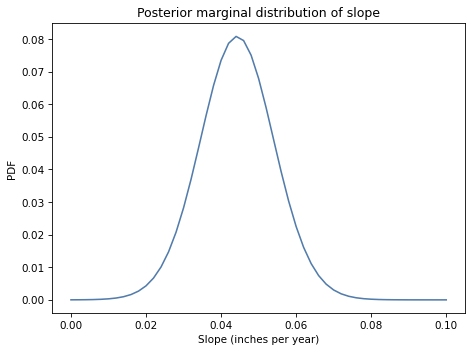
Extract the posterior distribution of
slope. How confident are we that temperature is increasing?Draw a sample of parameters from the posterior distribution and use it to generate predictions up to 2067.
Plot the median of the predictions and a 90% credible interval along with the observed data.
Does the model fit the data well? How much do we expect annual average temperatures to increase over my (expected) lifetime?
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)