You can order print and ebook versions of Think Bayes 2e from Bookshop.org and Amazon.
13. Inference#
Whenever people compare Bayesian inference with conventional approaches, one of the questions that comes up most often is something like, “What about p-values?” And one of the most common examples is the comparison of two groups to see if there is a difference in their means.
In classical statistical inference, the usual tool for this scenario is a Student’s t-test, and the result is a p-value. This process is an example of null hypothesis significance testing.
A Bayesian alternative is to compute the posterior distribution of the difference between the groups. Then we can use that distribution to answer whatever questions we are interested in, including the most likely size of the difference, a credible interval that’s likely to contain the true difference, the probability of superiority, or the probability that the difference exceeds some threshold.
To demonstrate this process, I’ll solve a problem borrowed from a statistical textbook: evaluating the effect of an educational “treatment” compared to a control.
13.1. Improving Reading Ability#
We’ll use data from a Ph.D. dissertation in educational psychology written in 1987, which was used as an example in a statistics textbook from 1989 and published on DASL, a web page that collects data stories.
Here’s the description from DASL:
An educator conducted an experiment to test whether new directed reading activities in the classroom will help elementary school pupils improve some aspects of their reading ability. She arranged for a third grade class of 21 students to follow these activities for an 8-week period. A control classroom of 23 third graders followed the same curriculum without the activities. At the end of the 8 weeks, all students took a Degree of Reading Power (DRP) test, which measures the aspects of reading ability that the treatment is designed to improve.
The dataset is available here.
I’ll use Pandas to load the data into a DataFrame.
import pandas as pd
df = pd.read_csv('drp_scores.csv', skiprows=21, delimiter='\t')
df.head(3)
| Treatment | Response | |
|---|---|---|
| 0 | Treated | 24 |
| 1 | Treated | 43 |
| 2 | Treated | 58 |
The Treatment column indicates whether each student was in the treated or control group.
The Response is their score on the test.
I’ll use groupby to separate the data for the Treated and Control groups:
grouped = df.groupby('Treatment')
responses = {}
for name, group in grouped:
responses[name] = group['Response']
Here are CDFs of the scores for the two groups and summary statistics.
from empiricaldist import Cdf
from utils import decorate
for name, response in responses.items():
cdf = Cdf.from_seq(response)
cdf.plot(label=name)
decorate(xlabel='Score',
ylabel='CDF',
title='Distributions of test scores')
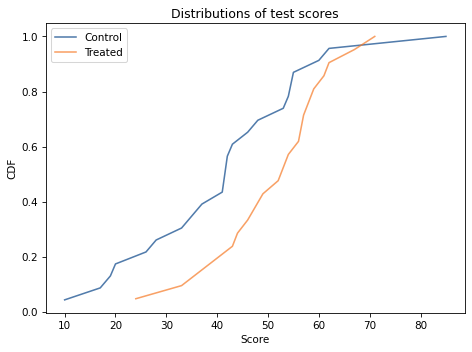
There is overlap between the distributions, but it looks like the scores are higher in the treated group. The distribution of scores is not exactly normal for either group, but it is close enough that the normal model is a reasonable choice.
So I’ll assume that in the entire population of students (not just the ones in the experiment), the distribution of scores is well modeled by a normal distribution with unknown mean and standard deviation.
I’ll use mu and sigma to denote these unknown parameters,
and we’ll do a Bayesian update to estimate what they are.
13.2. Estimating Parameters#
As always, we need a prior distribution for the parameters. Since there are two parameters, it will be a joint distribution. I’ll construct it by choosing marginal distributions for each parameter and computing their outer product.
As a simple starting place, I’ll assume that the prior distributions for mu and sigma are uniform.
The following function makes a Pmf object that represents a uniform distribution.
from empiricaldist import Pmf
def make_uniform(qs, name=None, **options):
"""Make a Pmf that represents a uniform distribution."""
pmf = Pmf(1.0, qs, **options)
pmf.normalize()
if name:
pmf.index.name = name
return pmf
make_uniform takes as parameters
An array of quantities,
qs, andA string,
name, which is assigned to the index so it appears when we display thePmf.
Here’s the prior distribution for mu:
import numpy as np
qs = np.linspace(20, 80, num=101)
prior_mu = make_uniform(qs, name='mean')
I chose the lower and upper bounds by trial and error. I’ll explain how when we look at the posterior distribution.
Here’s the prior distribution for sigma:
qs = np.linspace(5, 30, num=101)
prior_sigma = make_uniform(qs, name='std')
Now we can use make_joint to make the joint prior distribution.
from utils import make_joint
prior = make_joint(prior_mu, prior_sigma)
And we’ll start by working with the data from the control group.
data = responses['Control']
data.shape
(23,)
In the next section we’ll compute the likelihood of this data for each pair of parameters in the prior distribution.
13.3. Likelihood#
We would like to know the probability of each score in the dataset for each hypothetical pair of values, mu and sigma.
I’ll do that by making a 3-dimensional grid with values of mu on the first axis, values of sigma on the second axis, and the scores from the dataset on the third axis.
mu_mesh, sigma_mesh, data_mesh = np.meshgrid(
prior.columns, prior.index, data)
mu_mesh.shape
(101, 101, 23)
Now we can use norm.pdf to compute the probability density of each score for each hypothetical pair of parameters.
from scipy.stats import norm
densities = norm(mu_mesh, sigma_mesh).pdf(data_mesh)
densities.shape
(101, 101, 23)
The result is a 3-D array. To compute likelihoods, I’ll multiply these densities along axis=2, which is the axis of the data:
likelihood = densities.prod(axis=2)
likelihood.shape
(101, 101)
The result is a 2-D array that contains the likelihood of the entire dataset for each hypothetical pair of parameters.
We can use this array to update the prior, like this:
from utils import normalize
posterior = prior * likelihood
normalize(posterior)
posterior.shape
(101, 101)
The result is a DataFrame that represents the joint posterior distribution.
The following function encapsulates these steps.
def update_norm(prior, data):
"""Update the prior based on data."""
mu_mesh, sigma_mesh, data_mesh = np.meshgrid(
prior.columns, prior.index, data)
densities = norm(mu_mesh, sigma_mesh).pdf(data_mesh)
likelihood = densities.prod(axis=2)
posterior = prior * likelihood
normalize(posterior)
return posterior
Here are the updates for the control and treatment groups:
data = responses['Control']
posterior_control = update_norm(prior, data)
data = responses['Treated']
posterior_treated = update_norm(prior, data)
And here’s what they look like:
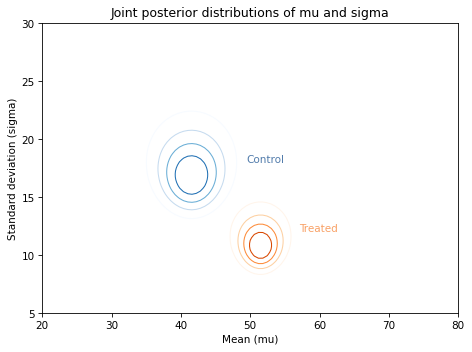
Along the \(x\)-axis, it looks like the mean score for the treated group is higher. Along the \(y\)-axis, it looks like the standard deviation for the treated group is lower.
If we think the treatment causes these differences, the data suggest that the treatment increases the mean of the scores and decreases their spread.
We can see these differences more clearly by looking at the marginal distributions for mu and sigma.
13.4. Posterior Marginal Distributions#
I’ll use marginal, which we saw in <<_MarginalDistributions>>, to extract the posterior marginal distributions for the population means.
from utils import marginal
pmf_mean_control = marginal(posterior_control, 0)
pmf_mean_treated = marginal(posterior_treated, 0)
Here’s what they look like:
pmf_mean_control.plot(label='Control')
pmf_mean_treated.plot(label='Treated')
decorate(xlabel='Population mean (mu)',
ylabel='PDF',
title='Posterior distributions of mu')
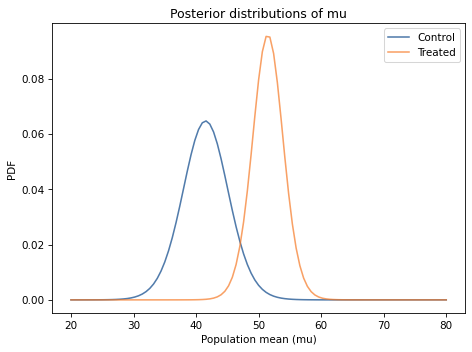
In both cases the posterior probabilities at the ends of the range are near zero, which means that the bounds we chose for the prior distribution are wide enough.
Comparing the marginal distributions for the two groups, it looks like the population mean in the treated group is higher.
We can use prob_gt to compute the probability of superiority:
Pmf.prob_gt(pmf_mean_treated, pmf_mean_control)
0.980479025187326
There is a 98% chance that the mean in the treated group is higher.
13.5. Distribution of Differences#
To quantify the magnitude of the difference between groups, we can use sub_dist to compute the distribution of the difference.
pmf_diff = Pmf.sub_dist(pmf_mean_treated, pmf_mean_control)
There are two things to be careful about when you use methods like sub_dist.
The first is that the result usually contains more elements than the original Pmf.
In this example, the original distributions have the same quantities, so the size increase is moderate.
len(pmf_mean_treated), len(pmf_mean_control), len(pmf_diff)
(101, 101, 879)
In the worst case, the size of the result can be the product of the sizes of the originals.
The other thing to be careful about is plotting the Pmf.
In this example, if we plot the distribution of differences, the result is pretty noisy.
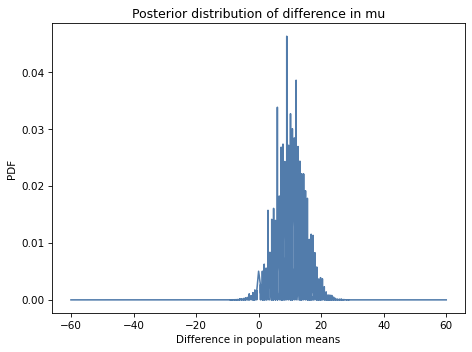
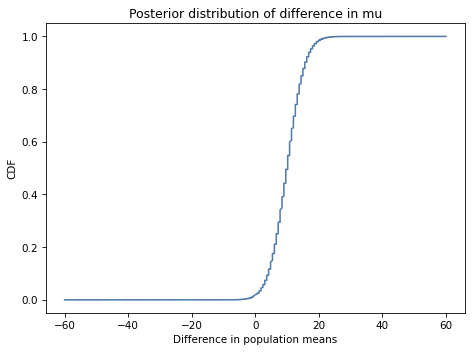
There are two ways to work around that limitation. One is to plot the CDF, which smooths out the noise:
cdf_diff = pmf_diff.make_cdf()
The other option is to use kernel density estimation (KDE) to make a smooth approximation of the PDF on an equally-spaced grid, which is what this function does:
from scipy.stats import gaussian_kde
def kde_from_pmf(pmf, n=101):
"""Make a kernel density estimate for a PMF."""
kde = gaussian_kde(pmf.qs, weights=pmf.ps)
qs = np.linspace(pmf.qs.min(), pmf.qs.max(), n)
ps = kde.evaluate(qs)
pmf = Pmf(ps, qs)
pmf.normalize()
return pmf
kde_from_pmf takes as parameters a Pmf and the number of places to evaluate the KDE.
It uses gaussian_kde, which we saw in <<_KernelDensityEstimation>>, passing the probabilities from the Pmf as weights.
This makes the estimated densities higher where the probabilities in the Pmf are higher.
Here’s what the kernel density estimate looks like for the Pmf of differences between the groups.
kde_diff = kde_from_pmf(pmf_diff)
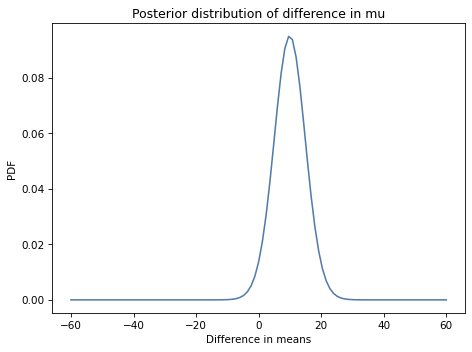
The mean of this distribution is almost 10 points on a test where the mean is around 45, so the effect of the treatment seems to be substantial.
pmf_diff.mean()
9.954413088940848
We can use credible_interval to compute a 90% credible interval.
pmf_diff.credible_interval(0.9)
array([ 2.4, 17.4])
Based on this interval, we are pretty sure the treatment improves test scores by 2 to 17 points.
13.6. Using Summary Statistics#
In this example the dataset is not very big, so it doesn’t take too long to compute the probability of every score under every hypothesis. But the result is a 3-D array; for larger datasets, it might be too big to compute practically.
Also, with larger datasets the likelihoods get very small, sometimes so small that we can’t compute them with floating-point arithmetic. That’s because we are computing the probability of a particular dataset; the number of possible datasets is astronomically big, so the probability of any of them is very small.
An alternative is to compute a summary of the dataset and compute the likelihood of the summary. For example, if we compute the mean and standard deviation of the data, we can compute the likelihood of those summary statistics under each hypothesis.
As an example, suppose we know that the actual mean of the population, \(\mu\), is 42 and the actual standard deviation, \(\sigma\), is 17.
mu = 42
sigma = 17
Now suppose we draw a sample from this distribution with sample size n=20, and compute the mean of the sample, which I’ll call m, and the standard deviation of the sample, which I’ll call s.
And suppose it turns out that:
n = 20
m = 41
s = 18
The summary statistics, m and s, are not too far from the parameters \(\mu\) and \(\sigma\), so it seems like they are not too unlikely.
To compute their likelihood, we will take advantage of three results from mathematical statistics:
Given \(\mu\) and \(\sigma\), the distribution of
mis normal with parameters \(\mu\) and \(\sigma/\sqrt{n}\);The distribution of \(s\) is more complicated, but if we compute the transform \(t = n s^2 / \sigma^2\), the distribution of \(t\) is chi-squared with parameter \(n-1\); and
According to Basu’s theorem,
mandsare independent.
So let’s compute the likelihood of m and s given \(\mu\) and \(\sigma\).
First I’ll create a norm object that represents the distribution of m.
dist_m = norm(mu, sigma/np.sqrt(n))
This is the “sampling distribution of the mean”.
We can use it to compute the likelihood of the observed value of m, which is 41.
like1 = dist_m.pdf(m)
like1
0.10137915138497372
Now let’s compute the likelihood of the observed value of s, which is 18.
First, we compute the transformed value t:
t = n * s**2 / sigma**2
t
22.422145328719722
Then we create a chi2 object to represent the distribution of t:
from scipy.stats import chi2
dist_s = chi2(n-1)
Now we can compute the likelihood of t:
like2 = dist_s.pdf(t)
like2
0.04736427909437004
Finally, because m and s are independent, their joint likelihood is the product of their likelihoods:
like = like1 * like2
like
0.004801750420548287
Now we can compute the likelihood of the data for any values of \(\mu\) and \(\sigma\), which we’ll use in the next section to do the update.
13.7. Update with Summary Statistics#
Now we’re ready to do an update. I’ll compute summary statistics for the two groups.
summary = {}
for name, response in responses.items():
summary[name] = len(response), response.mean(), response.std()
summary
{'Control': (23, 41.52173913043478, 17.148733229699484),
'Treated': (21, 51.476190476190474, 11.00735684721381)}
The result is a dictionary that maps from group name to a tuple that contains the sample size, n, the sample mean, m, and the sample standard deviation s, for each group.
I’ll demonstrate the update with the summary statistics from the control group.
n, m, s = summary['Control']
I’ll make a mesh with hypothetical values of mu on the x axis and values of sigma on the y axis.
mus, sigmas = np.meshgrid(prior.columns, prior.index)
mus.shape
(101, 101)
Now we can compute the likelihood of seeing the sample mean, m, for each pair of parameters.
like1 = norm(mus, sigmas/np.sqrt(n)).pdf(m)
like1.shape
(101, 101)
And we can compute the likelihood of the sample standard deviation, s, for each pair of parameters.
ts = n * s**2 / sigmas**2
like2 = chi2(n-1).pdf(ts)
like2.shape
(101, 101)
Finally, we can do the update with both likelihoods:
posterior_control2 = prior * like1 * like2
normalize(posterior_control2)
To compute the posterior distribution for the treatment group, I’ll put the previous steps in a function:
def update_norm_summary(prior, data):
"""Update a normal distribution using summary statistics."""
n, m, s = data
mu_mesh, sigma_mesh = np.meshgrid(prior.columns, prior.index)
like1 = norm(mu_mesh, sigma_mesh/np.sqrt(n)).pdf(m)
like2 = chi2(n-1).pdf(n * s**2 / sigma_mesh**2)
posterior = prior * like1 * like2
normalize(posterior)
return posterior
Here’s the update for the treatment group:
data = summary['Treated']
posterior_treated2 = update_norm_summary(prior, data)
And here are the results.
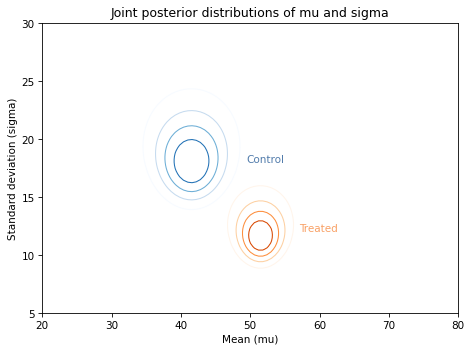
Visually, these posterior joint distributions are similar to the ones we computed using the entire dataset, not just the summary statistics. But they are not exactly the same, as we can see by comparing the marginal distributions.
13.8. Comparing Marginals#
Again, let’s extract the marginal posterior distributions.
from utils import marginal
pmf_mean_control2 = marginal(posterior_control2, 0)
pmf_mean_treated2 = marginal(posterior_treated2, 0)
And compare them to results we got using the entire dataset (the dashed lines).
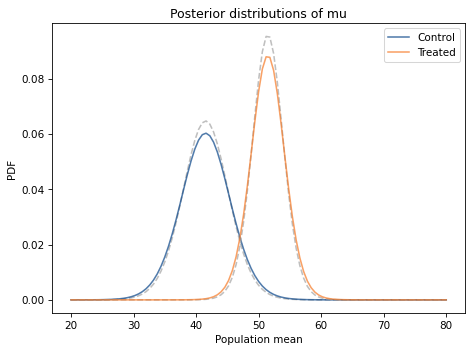
The posterior distributions based on summary statistics are similar to the posteriors we computed using the entire dataset, but in both cases they are shorter and a little wider.
That’s because the update with summary statistics is based on the implicit assumption that the distribution of the data is normal. But it’s not; as a result, when we replace the dataset with the summary statistics, we lose some information about the true distribution of the data. With less information, we are less certain about the parameters.
13.9. Proof By Simulation#
The update with summary statistics is based on theoretical distributions, and it seems to work, but I think it is useful to test theories like this, for a few reasons:
It confirms that our understanding of the theory is correct,
It confirms that the conditions where we apply the theory are conditions where the theory holds,
It confirms that the implementation details are correct. For many distributions, there is more than one way to specify the parameters. If you use the wrong specification, this kind of testing will help you catch the error.
In this section I’ll use simulations to show that the distribution of the sample mean and standard deviation is as I claimed. But if you want to take my word for it, you can skip this section and the next.
Let’s suppose that we know the actual mean and standard deviation of the population:
I’ll create a norm object to represent this distribution.
norm provides rvs, which generates random values from the distribution.
We can use it to simulate 1000 samples, each with sample size n=20.
The result is an array with 1000 rows, each containing a sample or 20 simulated test scores.
If we compute the mean of each row, the result is an array that contains 1000 sample means; that is, each value is the mean of a sample with n=20.
Now, let’s compare the distribution of these means to dist_m.
I’ll use pmf_from_dist to make a discrete approximation of dist_m:
pmf_from_dist takes an object representing a continuous distribution, evaluates its probability density function at equally space points between low and high, and returns a normalized Pmf that approximates the distribution.
I’ll use it to evaluate dist_m over a range of six standard deviations.
Now let’s compare this theoretical distribution to the means of the samples.
I’ll use kde_from_sample to estimate their distribution and evaluate it in the same locations as pmf_m.
The following figure shows the two distributions.
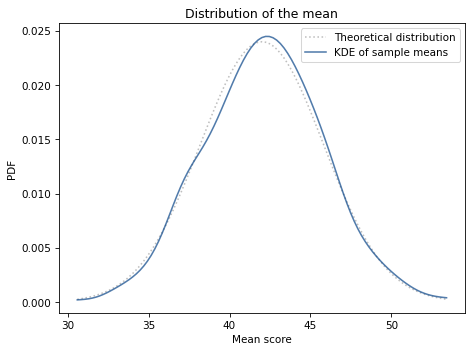
The theoretical distribution and the distribution of sample means are in accord.
13.10. Checking Standard Deviation#
Let’s also check that the standard deviations follow the distribution we expect. First I’ll compute the standard deviation for each of the 1000 samples.
Now we’ll compute the transformed values, \(t = n s^2 / \sigma^2\).
We expect the transformed values to follow a chi-square distribution with parameter \(n-1\).
SciPy provides chi2, which we can use to represent this distribution.
We can use pmf_from_dist again to make a discrete approximation.
And we’ll use kde_from_sample to estimate the distribution of the sample standard deviations.
Now we can compare the theoretical distribution to the distribution of the standard deviations.
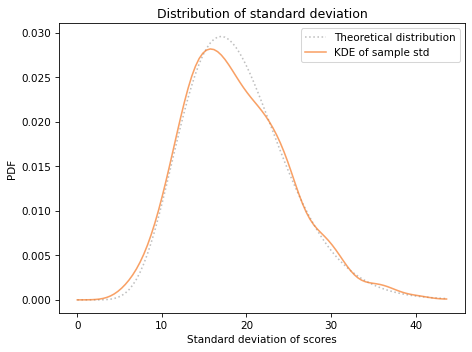
The distribution of transformed standard deviations agrees with the theoretical distribution.
Finally, to confirm that the sample means and standard deviations are independent, I’ll compute their coefficient of correlation:
Their correlation is near zero, which is consistent with their being independent.
So the simulations confirm the theoretical results we used to do the update with summary statistics.
We can also use kdeplot from Seaborn to see what their joint distribution looks like.
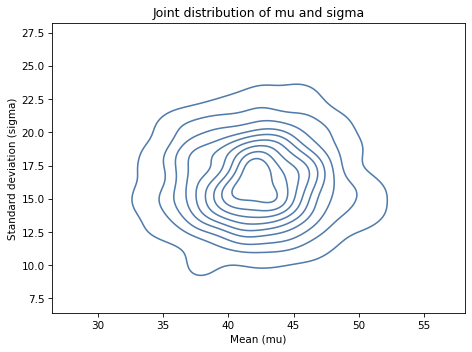
It looks like the axes of the ellipses are aligned with the axes, which indicates that the variables are independent.
13.11. Summary#
In this chapter we used a joint distribution to represent prior probabilities for the parameters of a normal distribution, mu and sigma.
And we updated that distribution two ways: first using the entire dataset and the normal PDF; then using summary statistics, the normal PDF, and the chi-square PDF.
Using summary statistics is computationally more efficient, but it loses some information in the process.
Normal distributions appear in many domains, so the methods in this chapter are broadly applicable. The exercises at the end of the chapter will give you a chance to apply them.
13.12. Exercises#
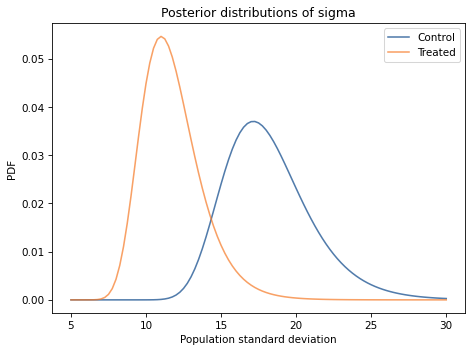
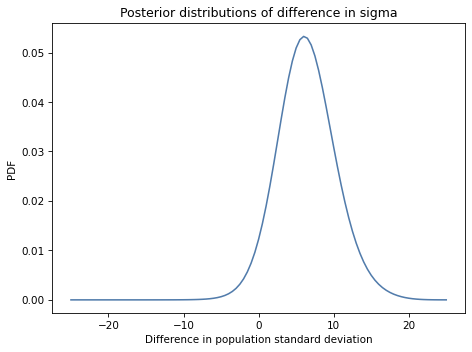
Exercise: Looking again at the posterior joint distribution of mu and sigma, it seems like the standard deviation of the treated group might be lower; if so, that would suggest that the treatment is more effective for students with lower scores.
But before we speculate too much, we should estimate the size of the difference and see whether it might actually be 0.
Extract the marginal posterior distributions of sigma for the two groups.
What is the probability that the standard deviation is higher in the control group?
Compute the distribution of the difference in sigma between the two groups. What is the mean of this difference? What is the 90% credible interval?
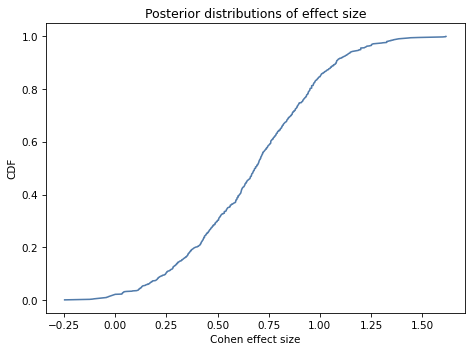
Exercise: An effect size is a statistic intended to quantify the magnitude of a phenomenon. If the phenomenon is a difference in means between two groups, a common way to quantify it is Cohen’s effect size, denoted \(d\).
If the parameters for Group 1 are \((\mu_1, \sigma_1)\), and the parameters for Group 2 are \((\mu_2, \sigma_2)\), Cohen’s effect size is
Use the joint posterior distributions for the two groups to compute the posterior distribution for Cohen’s effect size.
If we try enumerate all pairs from the two distributions, it takes too long so we’ll use random sampling.
The following function takes a joint posterior distribution and returns a sample of pairs. It uses some features we have not seen yet, but you can ignore the details for now.
Here’s how we can use it to sample pairs from the posterior distributions for the two groups.
The result is an array of tuples, where each tuple contains a possible pair of values for \(\mu\) and \(\sigma\). Now you can loop through the samples, compute the Cohen effect size for each, and estimate the distribution of effect sizes.
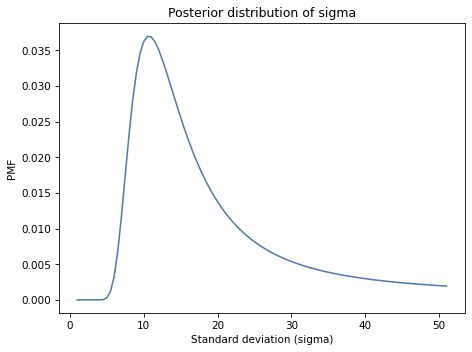
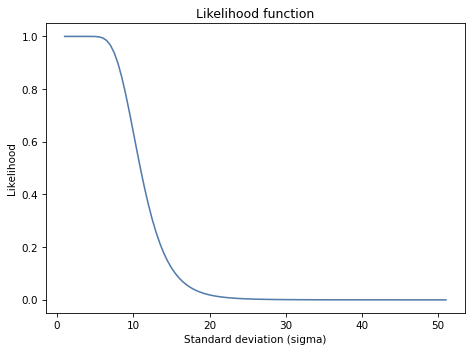
Exercise: This exercise is inspired by a question that appeared on Reddit.
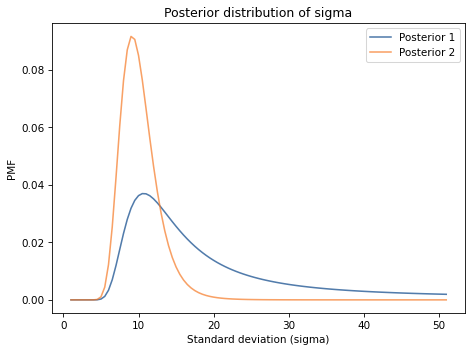
An instructor announces the results of an exam like this, “The average score on this exam was 81. Out of 25 students, 5 got more than 90, and I am happy to report that no one failed (got less than 60).”
Based on this information, what do you think the standard deviation of scores was?
You can assume that the distribution of scores is approximately normal. And let’s assume that the sample mean, 81, is actually the population mean, so we only have to estimate sigma.
Hint: To compute the probability of a score greater than 90, you can use norm.sf, which computes the survival function, also known as the complementary CDF, or 1 - cdf(x).
Exercise: The Variability Hypothesis is the observation that many physical traits are more variable among males than among females, in many species.
It has been a subject of controversy since the early 1800s, which suggests an exercise we can use to practice the methods in this chapter. Let’s look at the distribution of heights for men and women in the U.S. and see who is more variable.
I used 2018 data from the CDC’s Behavioral Risk Factor Surveillance System (BRFSS), which includes self-reported heights from 154 407 men and 254 722 women.
Here’s what I found:
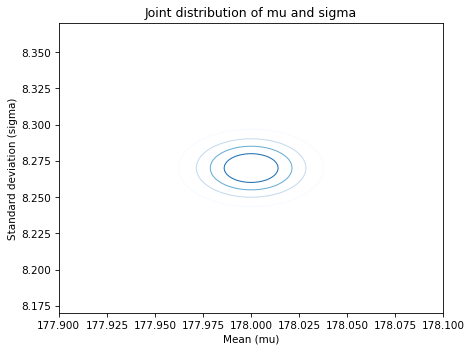
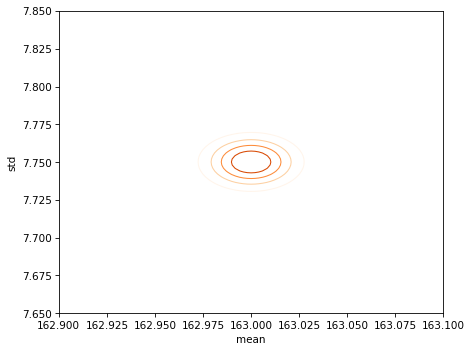
The average height for men is 178 cm; the average height for women is 163 cm. So men are taller on average; no surprise there.
For men the standard deviation is 8.27 cm; for women it is 7.75 cm. So in absolute terms, men’s heights are more variable.
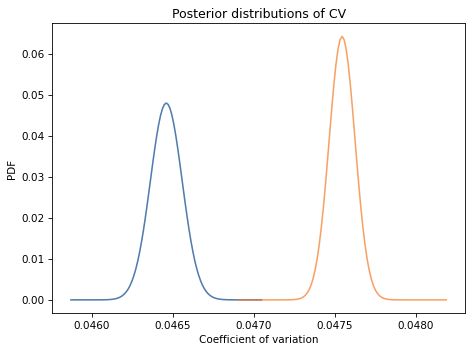
But to compare variability between groups, it is more meaningful to use the coefficient of variation (CV), which is the standard deviation divided by the mean. It is a dimensionless measure of variability relative to scale.
For men CV is 0.0465; for women it is 0.0475. The coefficient of variation is higher for women, so this dataset provides evidence against the Variability Hypothesis. But we can use Bayesian methods to make that conclusion more precise.
Use these summary statistics to compute the posterior distribution of mu and sigma for the distributions of male and female height.
Use Pmf.div_dist to compute posterior distributions of CV.
Based on this dataset and the assumption that the distribution of height is normal, what is the probability that the coefficient of variation is higher for men?
What is the most likely ratio of the CVs and what is the 90% credible interval for that ratio?
Hint: Use different prior distributions for the two groups, and chose them so they cover all parameters with non-negligible probability.
Also, you might find this function helpful:
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)