You can order print and ebook versions of Think Bayes 2e from Bookshop.org and Amazon.
16. Logistic Regression#
This chapter introduces two related topics: log odds and logistic regression.
In <<_BayessRule>>, we rewrote Bayes’s Theorem in terms of odds and derived Bayes’s Rule, which can be a convenient way to do a Bayesian update on paper or in your head. In this chapter, we’ll look at Bayes’s Rule on a logarithmic scale, which provides insight into how we accumulate evidence through successive updates.
That leads directly to logistic regression, which is based on a linear model of the relationship between evidence and the log odds of a hypothesis. As an example, we’ll use data from the Space Shuttle to explore the relationship between temperature and the probability of damage to the O-rings.
As an exercise, you’ll have a chance to model the relationship between a child’s age when they start school and their probability of being diagnosed with Attention Deficit Hyperactivity Disorder (ADHD).
16.1. Log Odds#
When I was in grad school, I signed up for a class on the Theory of Computation. On the first day of class, I was the first to arrive. A few minutes later, another student arrived.
At the time, about 83% of the students in the computer science program were male, so I was mildly surprised to note that the other student was female.
When another female student arrived a few minutes later, I started to think I was in the wrong room. When third female student arrived, I was confident I was in the wrong room. And as it turned out, I was.
I’ll use this anecdote to demonstrate Bayes’s Rule on a logarithmic scale and show how it relates to logistic regression.
Using \(H\) to represent the hypothesis that I was in the right room, and \(F\) to represent the observation that the first other student was female, we can write Bayes’s Rule like this:
Before I saw the other students, I was confident I was in the right room, so I might assign prior odds of 10:1 in favor:
If I was in the right room, the likelihood of the first female student was about 17%. If I was not in the right room, the likelihood of the first female student was more like 50%,
So the likelihood ratio is close to 1/3. Applying Bayes’s Rule, the posterior odds were
After two students, the posterior odds were
And after three students:
At that point, I was right to suspect I was in the wrong room.
The following table shows the odds after each update, the corresponding probabilities, and the change in probability after each step, expressed in percentage points.
| odds | prob | prob diff | |
|---|---|---|---|
| prior | 10.000000 | 0.909091 | -- |
| 1 student | 3.333333 | 0.769231 | -13.986014 |
| 2 students | 1.111111 | 0.526316 | -24.291498 |
| 3 students | 0.370370 | 0.270270 | -25.604552 |
Each update uses the same likelihood, but the changes in probability are not the same. The first update decreases the probability by about 14 percentage points, the second by 24, and the third by 26. That’s normal for this kind of update, and in fact it’s necessary; if the changes were the same size, we would quickly get into negative probabilities.
The odds follow a more obvious pattern. Because each update multiplies the odds by the same likelihood ratio, the odds form a geometric sequence. And that brings us to consider another way to represent uncertainty: log odds, which is the logarithm of odds, usually expressed using the natural log (base \(e\)).
Adding log odds to the table:
| odds | prob | prob diff | log odds | log odds diff | |
|---|---|---|---|---|---|
| prior | 10.000000 | 0.909091 | -- | 2.302585 | -- |
| 1 student | 3.333333 | 0.769231 | -13.986014 | 1.203973 | -1.098612 |
| 2 students | 1.111111 | 0.526316 | -24.291498 | 0.105361 | -1.098612 |
| 3 students | 0.370370 | 0.270270 | -25.604552 | -0.993252 | -1.098612 |
You might notice:
When probability is greater than 0.5, odds are greater than 1, and log odds are positive.
When probability is less than 0.5, odds are less than 1, and log odds are negative.
You might also notice that the log odds are equally spaced. The change in log odds after each update is the logarithm of the likelihood ratio.
np.log(1/3)
-1.0986122886681098
That’s true in this example, and we can show that it’s true in general by taking the log of both sides of Bayes’s Rule.
On a log odds scale, a Bayesian update is additive. So if \(F^x\) means that \(x\) female students arrive while I am waiting, the posterior log odds that I am in the right room are:
This equation represents a linear relationship between the log likelihood ratio and the posterior log odds.
In this example the linear equation is exact, but even when it’s not, it is common to use a linear function to model the relationship between an explanatory variable, \(x\), and a dependent variable expressed in log odds, like this:
where \(\beta_0\) and \(\beta_1\) are unknown parameters:
The intercept, \(\beta_0\), is the log odds of the hypothesis when \(x\) is 0.
The slope, \(\beta_1\), is the log of the likelihood ratio.
This equation is the basis of logistic regression.
16.2. The Space Shuttle Problem#
As an example of logistic regression, I’ll solve a problem from Cameron Davidson-Pilon’s book, Bayesian Methods for Hackers. He writes:
“On January 28, 1986, the twenty-fifth flight of the U.S. space shuttle program ended in disaster when one of the rocket boosters of the Shuttle Challenger exploded shortly after lift-off, killing all seven crew members. The presidential commission on the accident concluded that it was caused by the failure of an O-ring in a field joint on the rocket booster, and that this failure was due to a faulty design that made the O-ring unacceptably sensitive to a number of factors including outside temperature. Of the previous 24 flights, data were available on failures of O-rings on 23 (one was lost at sea), and these data were discussed on the evening preceding the Challenger launch, but unfortunately only the data corresponding to the 7 flights on which there was a damage incident were considered important and these were thought to show no obvious trend.”
The dataset is originally from this paper, but also available from Davidson-Pilon.
I’ll read the data and do some cleaning.
Here are the first few rows:
| Date | Temperature | Damage | |
|---|---|---|---|
| 0 | 04/12/1981 | 66 | 0 |
| 1 | 11/12/1981 | 70 | 1 |
| 2 | 3/22/82 | 69 | 0 |
| 4 | 01/11/1982 | 68 | 0 |
| 5 | 04/04/1983 | 67 | 0 |
The columns are:
Date: The date of launch,Temperature: Outside temperature in Fahrenheit, andDamage:1if there was a damage incident and0otherwise.
There are 23 launches in the dataset, 7 with damage incidents.
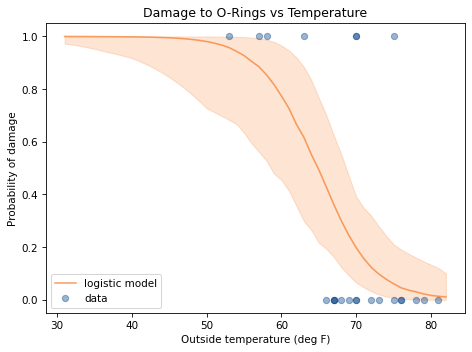
The following figure shows the relationship between damage and temperature.
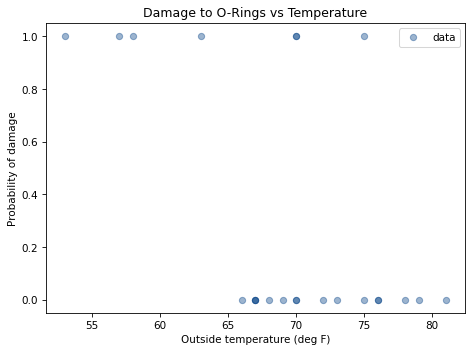
When the outside temperature was below 65 degrees, there was always damage to the O-rings. When the temperature was above 65 degrees, there was usually no damage.
Based on this figure, it seems plausible that the probability of damage is related to temperature. If we assume this probability follows a logistic model, we can write:
where \(H\) is the hypothesis that the O-rings will be damaged, \(x\) is temperature, and \(\beta_0\) and \(\beta_1\) are the parameters we will estimate. For reasons I’ll explain soon, I’ll define \(x\) to be temperature shifted by an offset so its mean is 0.
offset = data['Temperature'].mean().round()
data['x'] = data['Temperature'] - offset
offset
70.0
And for consistency I’ll create a copy of the Damage columns called y.
data['y'] = data['Damage']
Before doing a Bayesian update, I’ll use statsmodels to run a conventional (non-Bayesian) logistic regression.
import statsmodels.formula.api as smf
formula = 'y ~ x'
results = smf.logit(formula, data=data).fit(disp=False)
results.params
Intercept -1.208490
x -0.232163
dtype: float64
results contains a “point estimate” for each parameter, that is, a single value rather than a posterior distribution.
The intercept is about -1.2, and the estimated slope is about -0.23. To see what these parameters mean, I’ll use them to compute probabilities for a range of temperatures. Here’s the range:
inter = results.params['Intercept']
slope = results.params['x']
xs = np.arange(53, 83) - offset
We can use the logistic regression equation to compute log odds:
log_odds = inter + slope * xs
And then convert to probabilities.
odds = np.exp(log_odds)
ps = odds / (odds + 1)
Converting log odds to probabilities is a common enough operation that it has a name, expit, and SciPy provides a function that computes it.
from scipy.special import expit
ps = expit(inter + slope * xs)
Here’s what the logistic model looks like with these estimated parameters.
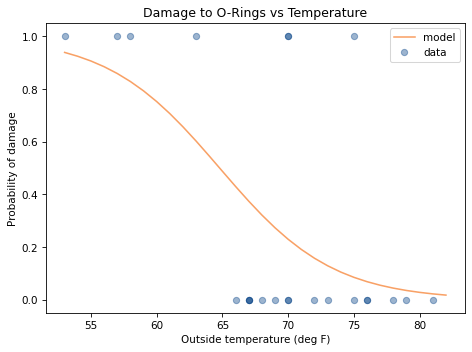
At low temperatures, the probability of damage is high; at high temperatures, it drops off to near 0.
But that’s based on conventional logistic regression. Now we’ll do the Bayesian version.
16.3. Prior Distribution#
I’ll use uniform distributions for both parameters, using the point estimates from the previous section to help me choose the upper and lower bounds.
from utils import make_uniform
qs = np.linspace(-5, 1, num=101)
prior_inter = make_uniform(qs, 'Intercept')
qs = np.linspace(-0.8, 0.1, num=101)
prior_slope = make_uniform(qs, 'Slope')
We can use make_joint to construct the joint prior distribution.
from utils import make_joint
joint = make_joint(prior_inter, prior_slope)
The values of intercept run across the columns, the values of slope run down the rows.
For this problem, it will be convenient to “stack” the prior so the parameters are levels in a MultiIndex, and put the result in a Pmf.
from empiricaldist import Pmf
joint_pmf = Pmf(joint.stack())
joint_pmf.head()
| probs | ||
|---|---|---|
| Slope | Intercept | |
| -0.8 | -5.00 | 0.000098 |
| -4.94 | 0.000098 | |
| -4.88 | 0.000098 |
joint_pmf is a Pmf with two levels in the index, one for each parameter. That makes it easy to loop through possible pairs of parameters, as we’ll see in the next section.
16.4. Likelihood#
To do the update, we have to compute the likelihood of the data for each possible pair of parameters.
To make that easier, I’m going to group the data by temperature, x, and count the number of launches and damage incidents at each temperature.
grouped = data.groupby('x')['y'].agg(['count', 'sum'])
grouped.head()
| count | sum | |
|---|---|---|
| x | ||
| -17.0 | 1 | 1 |
| -13.0 | 1 | 1 |
| -12.0 | 1 | 1 |
| -7.0 | 1 | 1 |
| -4.0 | 1 | 0 |
The result is a DataFrame with two columns: count is the number of launches at each temperature; sum is the number of damage incidents.
To be consistent with the parameters of the binomial distributions, I’ll assign them to variables named ns and ks.
ns = grouped['count']
ks = grouped['sum']
To compute the likelihood of the data, let’s assume temporarily that the parameters we just estimated, slope and inter, are correct.
We can use them to compute the probability of damage at each launch temperature, like this:
xs = grouped.index
ps = expit(inter + slope * xs)
ps contains the probability of damage for each launch temperature, according to the model.
Now, for each temperature we have ns, ps, and ks;
we can use the binomial distribution to compute the likelihood of the data.
from scipy.stats import binom
likes = binom.pmf(ks, ns, ps)
likes
array([0.93924781, 0.85931657, 0.82884484, 0.60268105, 0.56950687,
0.24446388, 0.67790595, 0.72637895, 0.18815003, 0.8419509 ,
0.87045398, 0.15645171, 0.86667894, 0.95545945, 0.96435859,
0.97729671])
Each element of likes is the probability of seeing k damage incidents in n launches if the probability of damage is p.
The likelihood of the whole dataset is the product of this array.
likes.prod()
0.0004653644508250075
That’s how we compute the likelihood of the data for a particular pair of parameters. Now we can compute the likelihood of the data for all possible pairs:
likelihood = joint_pmf.copy()
for slope, inter in joint_pmf.index:
ps = expit(inter + slope * xs)
likes = binom.pmf(ks, ns, ps)
likelihood[slope, inter] = likes.prod()
To initialize likelihood, we make a copy of joint_pmf, which is a convenient way to make sure that likelihood has the same type, index, and data type as joint_pmf.
The loop iterates through the parameters. For each possible pair, it uses the logistic model to compute ps, computes the likelihood of the data, and assigns the result to a row in likelihood.
16.5. The Update#
Now we can compute the posterior distribution in the usual way.
posterior_pmf = joint_pmf * likelihood
posterior_pmf.normalize()
Because we used a uniform prior, the parameter pair with the highest likelihood is also the pair with maximum posterior probability:
So we can confirm that the results of the Bayesian update are consistent with the maximum likelihood estimate computed by StatsModels:
They are approximately the same, within the precision of the grid we’re using.
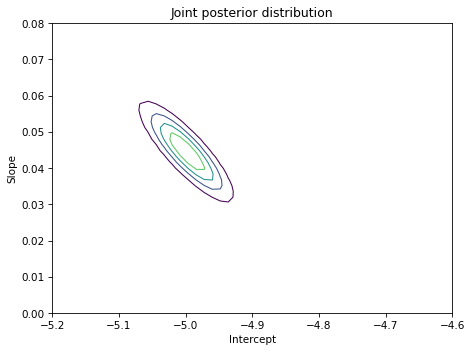
If we unstack the posterior Pmf we can make a contour plot of the joint posterior distribution.
from utils import plot_contour
joint_posterior = posterior_pmf.unstack()
plot_contour(joint_posterior)
decorate(title='Joint posterior distribution')
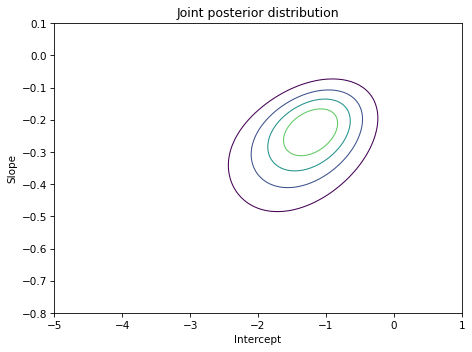
The ovals in the contour plot are aligned along a diagonal, which indicates that there is some correlation between slope and inter in the posterior distribution.
But the correlation is weak, which is one of the reasons we subtracted off the mean launch temperature when we computed x; centering the data minimizes the correlation between the parameters.
Exercise: To see why this matters, go back and set offset=60 and run the analysis again.
The slope should be the same, but the intercept will be different. And if you plot the joint distribution, the contours you get will be elongated, indicating stronger correlation between the estimated parameters.
In theory, this correlation is not a problem, but in practice it is. With uncentered data, the posterior distribution is more spread out, so it’s harder to cover with the joint prior distribution. Centering the data maximizes the precision of the estimates; with uncentered data, we have to do more computation to get the same precision.
16.6. Marginal Distributions#
Finally, we can extract the marginal distributions.
from utils import marginal
marginal_inter = marginal(joint_posterior, 0)
marginal_slope = marginal(joint_posterior, 1)
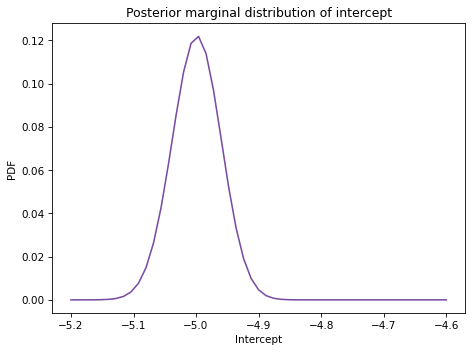
Here’s the posterior distribution of inter.
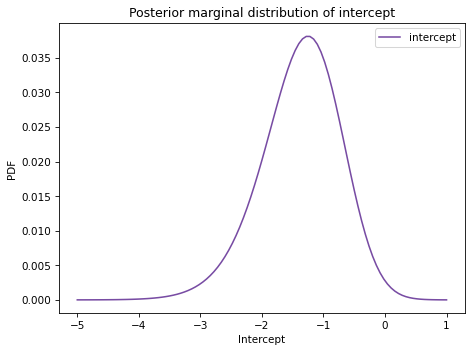
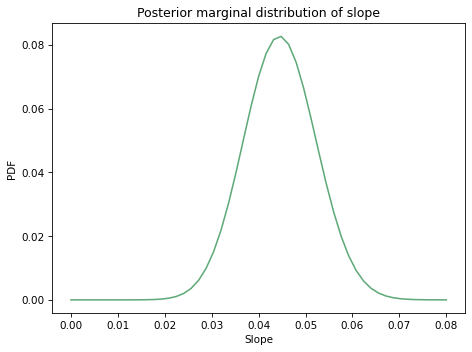
And here’s the posterior distribution of slope.
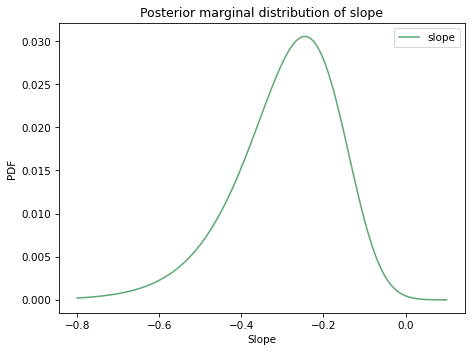
Here are the posterior means.
Both marginal distributions are moderately skewed, so the posterior means are somewhat different from the point estimates.
16.7. Transforming Distributions#
Let’s interpret these parameters. Recall that the intercept is the log odds of the hypothesis when \(x\) is 0, which is when temperature is about 70 degrees F (the value of offset).
So we can interpret the quantities in marginal_inter as log odds.
To convert them to probabilities, I’ll use the following function, which transforms the quantities in a Pmf by applying a given function:
def transform(pmf, func):
"""Transform the quantities in a Pmf."""
ps = pmf.ps
qs = func(pmf.qs)
return Pmf(ps, qs, copy=True)
If we call transform and pass expit as a parameter, it transforms the log odds in marginal_inter into probabilities and returns the posterior distribution of inter expressed in terms of probabilities.
marginal_probs = transform(marginal_inter, expit)
Pmf provides a transform method that does the same thing.
marginal_probs = marginal_inter.transform(expit)
Here’s the posterior distribution for the probability of damage at 70 degrees F.
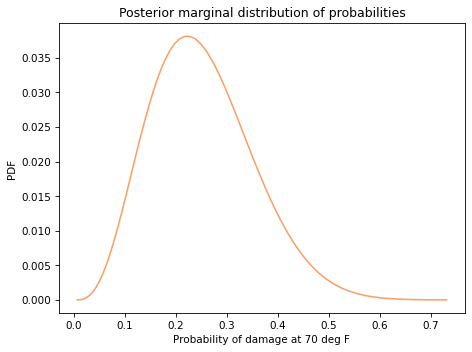
The mean of this distribution is about 22%, which is the probability of damage at 70 degrees F, according to the model.
This result shows the second reason I defined x to be zero when temperature is 70 degrees F; this way, the intercept corresponds to the probability of damage at a relevant temperature, rather than 0 degrees F.
Now let’s look more closely at the estimated slope. In the logistic model, the parameter \(\beta_1\) is the log of the likelihood ratio.
So we can interpret the quantities in marginal_slope as log likelihood ratios, and we can use exp to transform them to likelihood ratios (also known as Bayes factors).
marginal_lr = marginal_slope.transform(np.exp)
The result is the posterior distribution of likelihood ratios; here’s what it looks like.
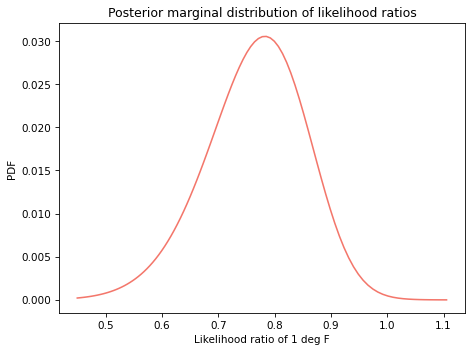
The mean of this distribution is about 0.75, which means that each additional degree Fahrenheit provides evidence against the possibility of damage, with a likelihood ratio (Bayes factor) of 0.75.
Notice:
I computed the posterior mean of the probability of damage at 70 deg F by transforming the marginal distribution of the intercept to the marginal distribution of probability, and then computing the mean.
I computed the posterior mean of the likelihood ratio by transforming the marginal distribution of slope to the marginal distribution of likelihood ratios, and then computing the mean.
This is the correct order of operations, as opposed to computing the posterior means first and then transforming them.
To see the difference, let’s compute both values the other way around.
Here’s the posterior mean of marginal_inter, transformed to a probability, compared to the mean of marginal_probs.
And here’s the posterior mean of marginal_slope, transformed to a likelihood ratio, compared to the mean marginal_lr.
In this example, the differences are not huge, but they can be. As a general rule, transform first, then compute summary statistics.
16.8. Predictive Distributions#
In the logistic model, the parameters are interpretable, at least after transformation. But often what we care about are predictions, not parameters. In the Space Shuttle problem, the most important prediction is, “What is the probability of O-ring damage if the outside temperature is 31 degrees F?”
To make that prediction, I’ll draw a sample of parameter pairs from the posterior distribution.
sample = posterior_pmf.choice(101)
The result is an array of 101 tuples, each representing a possible pair of parameters. I chose this sample size to make the computation fast. Increasing it would not change the results much, but they would be a little more precise.
To generate predictions, I’ll use a range of temperatures from 31 degrees F (the temperature when the Challenger launched) to 82 degrees F (the highest observed temperature).
temps = np.arange(31, 83)
xs = temps - offset
The following loop uses xs and the sample of parameters to construct an array of predicted probabilities.
pred = np.empty((len(sample), len(xs)))
for i, (slope, inter) in enumerate(sample):
pred[i] = expit(inter + slope * xs)
The result has one column for each value in xs and one row for each element of sample.
To get a quick sense of what the predictions look like, we can loop through the rows and plot them.
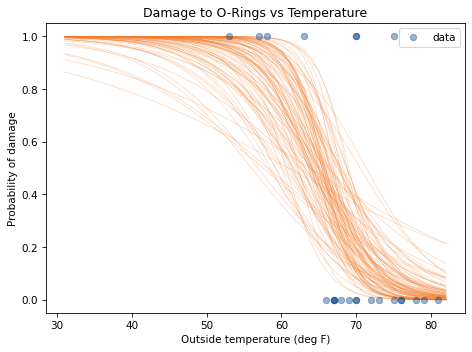
The overlapping lines in this figure give a sense of the most likely value at each temperature and the degree of uncertainty.
In each column, I’ll compute the median to quantify the central tendency and a 90% credible interval to quantify the uncertainty.
np.percentile computes the given percentiles; with the argument axis=0, it computes them for each column.
low, median, high = np.percentile(pred, [5, 50, 95], axis=0)
The results are arrays containing predicted probabilities for the lower bound of the 90% CI, the median, and the upper bound of the CI.
Here’s what they look like:
According to these results, the probability of damage to the O-rings at 80 degrees F is near 2%, but there is some uncertainty about that prediction; the upper bound of the CI is around 10%.
At 60 degrees, the probability of damage is near 80%, but the CI is even wider, from 48% to 97%.
But the primary goal of the model is to predict the probability of damage at 31 degrees F, and the answer is at least 97%, and more likely to be more than 99.9%.
One conclusion we might draw is this: If the people responsible for the Challenger launch had taken into account all of the data, and not just the seven damage incidents, they could have predicted that the probability of damage at 31 degrees F was nearly certain. If they had, it seems likely they would have postponed the launch.
At the same time, if they considered the previous figure, they might have realized that the model makes predictions that extend far beyond the data. When we extrapolate like that, we have to remember not just the uncertainty quantified by the model, which we expressed as a credible interval; we also have to consider the possibility that the model itself is unreliable.
This example is based on a logistic model, which assumes that each additional degree of temperature contributes the same amount of evidence in favor of (or against) the possibility of damage. Within a narrow range of temperatures, that might be a reasonable assumption, especially if it is supported by data. But over a wider range, and beyond the bounds of the data, reality has no obligation to stick to the model.
16.9. Empirical Bayes#
In this chapter I used StatsModels to compute the parameters that maximize the probability of the data, and then used those estimates to choose the bounds of the uniform prior distributions. It might have occurred to you that this process uses the data twice, once to choose the priors and again to do the update. If that bothers you, you are not alone. The process I used is an example of what’s called the Empirical Bayes method, although I don’t think that’s a particularly good name for it.
Although it might seem problematic to use the data twice, in these examples, it is not. To see why, consider an alternative: instead of using the estimated parameters to choose the bounds of the prior distribution, I could have used uniform distributions with much wider ranges. In that case, the results would be the same; the only difference is that I would spend more time computing likelihoods for parameters where the posterior probabilities are negligibly small.
So you can think of this version of Empirical Bayes as an optimization that minimizes computation by putting the prior distributions where the likelihood of the data is worth computing. This optimization doesn’t affect the results, so it doesn’t “double-count” the data.
16.10. Summary#
So far we have seen three ways to represent degrees of confidence in a hypothesis: probability, odds, and log odds. When we write Bayes’s Rule in terms of log odds, a Bayesian update is the sum of the prior and the likelihood; in this sense, Bayesian statistics is the arithmetic of hypotheses and evidence.
This form of Bayes’s Theorem is also the foundation of logistic regression, which we used to infer parameters and make predictions. In the Space Shuttle problem, we modeled the relationship between temperature and the probability of damage, and showed that the Challenger disaster might have been predictable. But this example is also a warning about the hazards of using a model to extrapolate far beyond the data.
In the exercises below you’ll have a chance to practice the material in this chapter, using log odds to evaluate a political pundit and using logistic regression to model diagnosis rates for Attention Deficit Hyperactivity Disorder (ADHD).
In the next chapter we’ll move from logistic regression to linear regression, which we will use to model changes over time in temperature, snowfall, and the marathon world record.
16.11. Exercises#
Exercise: Suppose a political pundit claims to be able to predict the outcome of elections, but instead of picking a winner, they give each candidate a probability of winning. With that kind of prediction, it can be hard to say whether it is right or wrong.
For example, suppose the pundit says that Alice has a 70% chance of beating Bob, and then Bob wins the election. Does that mean the pundit was wrong?
One way to answer this question is to consider two hypotheses:
H: The pundit’s algorithm is legitimate; the probabilities it produces are correct in the sense that they accurately reflect the candidates’ probabilities of winning.not H: The pundit’s algorithm is bogus; the probabilities it produces are random values with a mean of 50%.
If the pundit says Alice has a 70% chance of winning, and she does, that provides evidence in favor of H with likelihood ratio 70/50.
If the pundit says Alice has a 70% chance of winning, and she loses, that’s evidence against H with a likelihood ratio of 50/30.
Suppose we start with some confidence in the algorithm, so the prior odds are 4 to 1. And suppose the pundit generates predictions for three elections:
In the first election, the pundit says Alice has a 70% chance of winning and she does.
In the second election, the pundit says Bob has a 30% chance of winning and he does.
In the third election, the pundit says Carol has an 90% chance of winning and she does.
What is the log likelihood ratio for each of these outcomes? Use the log-odds form of Bayes’s Rule to compute the posterior log odds for H after these outcomes. In total, do these outcomes increase or decrease your confidence in the pundit?
If you are interested in this topic, you can read more about it in this blog post.
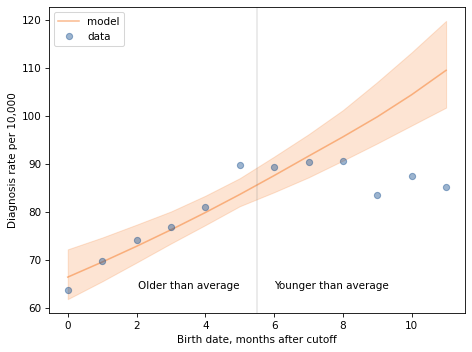
Exercise: An article in the New England Journal of Medicine reports results from a study that looked at the diagnosis rate of Attention Deficit Hyperactivity Disorder (ADHD) as a function of birth month: “Attention Deficit–Hyperactivity Disorder and Month of School Enrollment”.
They found that children born in June, July, and August were substantially more likely to be diagnosed with ADHD, compared to children born in September, but only in states that use a September cutoff for children to enter kindergarten. In these states, children born in August start school almost a year younger than children born in September. The authors of the study suggest that the cause is “age-based variation in behavior that may be attributed to ADHD rather than to the younger age of the children”.
Use the methods in this chapter to estimate the probability of diagnosis as a function of birth month. The notebook for this chapter provides the data and some suggestions for getting started.
The paper includes this figure:

In my opinion, this representation of the data does not show the effect as clearly as it could.
But the figure includes the raw data, so we can analyze it ourselves.
Note: there is an error in the figure, confirmed by personal correspondence:
The May and June [diagnoses] are reversed. May should be 317 (not 287) and June should be 287 (not 317).
So here is the corrected data, where n is the number of children born in each month, starting with January, and k is the number of children diagnosed with ADHD.
First, I’m going to “roll” the data so it starts in September rather than January.
And I’ll put it in a DataFrame with one row for each month and the diagnosis rate per 10,000.
Here’s what the diagnosis rates look like.
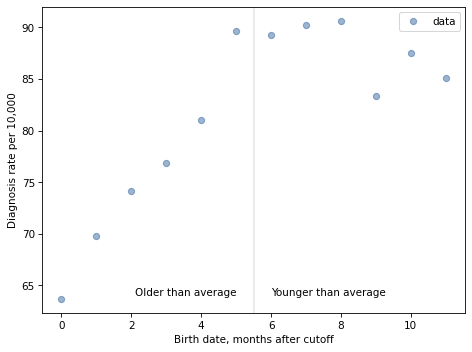
For the first 9 months, from September to May, we see what we would expect if some of the excess diagnoses are due to “age-based variation in behavior”. For each month of difference in age, we see an increase in the number of diagnoses.
This pattern breaks down for the last three months, June, July, and August. This might be explained by random variation, but it also might be due to parental manipulation; if some parents hold back children born near the deadline, the observations for these month would include a mixture of children who are relatively old for their grade and therefore less likely to be diagnosed.
Unfortunately, the dataset includes only month of birth, not year, so we don’t know the actual ages of these students when they started school. However, we can use the first nine months to estimate the effect of age on diagnosis rate; then we can think about what to do with the other three months.
Use the methods in this chapter to estimate the probability of diagnosis as a function of birth month. Start with the following prior distributions.
Make a joint prior distribution and update it using the data for the first nine months.
Then draw a sample from the posterior distribution and use it to compute the median probability of diagnosis for each month and a 90% credible interval.
As a bonus exercise, do a second update using the data from the last three months, but treating the observed number of diagnoses as a lower bound on the number of diagnoses there would be if no children were kept back.
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)