Defy Tradition, Save the World#
Probably Overthinking It is available from Bookshop.org and Amazon (affiliate links).
Click here to run this notebook on Colab.
Suppose you are the ruler of a small country where the population is growing quickly. Your advisers warn you that unless this growth slows down, the population will exceed the capacity of the farms and the peasants will starve.
The Royal Demographer informs you that the average family size is currently 3; that is, each woman in the kingdom bears three children, on average. He explains that the replacement level is close to 2, so if family sizes decrease by one, the population will level off at a sustainable size.
One of your advisors asks: “What if we make a new law that says every woman has to have fewer children than her mother?”
It sounds promising. As a benevolent despot, you are reluctant to restrict your subjects’ reproductive freedom, but it seems like such a policy could be effective at reducing family size with minimal imposition.
“Make it so,” you say.
Twenty-five years later, you summon the Royal Demographer to find out how things are going.
“Your Highness,” they say, “I have good news and bad news. The good news is that adherence to the new law has been perfect. Since it was put into effect, every woman in the kingdom has had fewer children than her mother.”
“That’s amazing,” you say. “What’s the bad news?”
“The bad news is that the average family size has increased from 3.0 to 3.3, so the population is growing faster than before, and we are running out of food.”
“How is that possible?” you ask. “If every woman has fewer children than her mother, family sizes have to get smaller, and population growth has to slow down.”
Actually, that’s not true.
In 1976, Samuel Preston, a demographer at the University of Washington, published a paper that presents three surprising phenomena.
The first is the relationship between two measurements of family size: what we get if we ask women how many children they have, and what we get if we ask people how many children their mother had. In general, the average family size is smaller if we ask women about their children, and larger if we ask children about their mothers. In this chapter, we’ll see why and by how much.
The second phenomenon is related to changes in American family sizes during the 20th century. Suppose you compare family sizes during the Great Depression (roughly the 1930s) and the Baby Boom (1946-64). If you survey women who bore children during these periods, the average family was bigger during the Baby Boom. But if you ask their children how big their families were, the average was bigger during the Depression. In this chapter, we’ll see how that happened.
The third phenomenon is what we learned in your imaginary kingdom, which I will call Preston’s Paradox: Even if every woman has fewer children than her mother, family sizes can get bigger, on average.
To see how that’s possible, we’ll start with the two measurements of family size.
Family Size#
Families are complicated. A woman might not raise her biological children, and she might raise children she did not bear. Children might not be raised with their biological siblings, and they might be raised with children they are not related to. So the definition of “family size” depends on who’s asked and what they’re asked.
In the context of population growth, we are often interested in lifetime fertility, so Preston defines “family size” to mean “the total number of children ever born to a woman who has completed childbearing.” He suggests that this measure “might more appropriately be termed ‘brood size’,” but I will stick with the less zoological term.
In the context of sociology, we are often interested in the size of the “family of orientation”, which is the family a person grows up in. If we can’t measure families of orientation directly, we can estimate their sizes, at least approximately, if we make the simplifying assumption that most women raise the children they bear. To show how that works, I’ll use data from the U.S. Census Bureau.
Every other year, as part of the Current Population Survey (CPS), the Census Bureau surveys a representative sample of women in the United States and asks, among other things, how many children they have ever borne. To measure completed family sizes, they select women aged 40-44 (of course, some women bear children in their forties, so these estimates might be a little low).
I used their data from 2018 to estimate the current distribution of family sizes. The following figure shows the result.
rename_dict = {
"Unnamed: 0": "Year",
"Unnamed: 1": "Total",
"Unnamed: 11": "Rate per 1000",
}
h2 = pd.read_excel("h2.xlsx", skiprows=6)
del h2["Unnamed: 7"]
h2 = h2.rename(columns=rename_dict)
h2.head()
| Year | Total | Total | None | One | Two | Three | Four | Five and six | Seven or more | Rate per 1000 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | All Marital Statuses | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | .Women 45 to 50 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | .2018 | 12524 | 100 | 15.4 | 19.8 | 35.4 | 17.3 | 7.4 | 3.6 | 1.2 | 1999 |
| 3 | .2016 | 12537 | 100 | 17.1 | 19.7 | 33.6 | 18.2 | 7.7 | 3.4 | 0.5 | 1936 |
| 4 | .2014 | 12760 | 100 | 16.7 | 18.7 | 33.8 | 19.2 | 7.6 | 3.2 | 0.9 | 1981 |
# Select women ages 40-44, and drop a row of missing data
rows = h2.iloc[7:35].drop(32)
rows
| Year | Total | Total | None | One | Two | Three | Four | Five and six | Seven or more | Rate per 1000 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | .2018 | 9896 | 100 | 15 | 18.7 | 34.6 | 18.6 | 8.7 | 3.8 | 0.7 | 2036 |
| 8 | .2016 | 9924 | 100 | 14.4 | 18.3 | 34.9 | 19.6 | 7.9 | 3.9 | 1 | 2068 |
| 9 | .2014 | 10301 | 100 | 15.3 | 18.3 | 34.6 | 20.2 | 7.6 | 3.3 | 0.8 | 2018 |
| 10 | .2012 | 10516 | 100 | 15.1 | 18.9 | 34.9 | 19.9 | 7.2 | 3.4 | 0.7 | 1998 |
| 11 | .2010 | 10374 | 100 | 18.8 | 18.5 | 33.3 | 19.1 | 6.8 | 2.7 | 0.8 | 1907 |
| 12 | .2008 | 10748 | 100 | 17.8 | 18.4 | 36.2 | 17.8 | 6.1 | 3.1 | 0.5 | 1901 |
| 13 | .2006 | 11235 | 100 | 20.4 | 16.9 | 34.4 | 18.5 | 6.4 | 3.1 | 0.5 | 1862 |
| 14 | .2004 | 11535 | 100 | 19.3 | 17.4 | 34.5 | 18.1 | 7.4 | 2.9 | 0.5 | 1895 |
| 15 | .2002 | 11561 | 100 | 17.9 | 17.4 | 35.4 | 18.9 | 6.8 | 2.8 | 0.8 | 1930 |
| 16 | .2000 | 11447 | 100 | 19 | 16.4 | 35 | 19.1 | 7.2 | 2.8 | 0.5 | 1913 |
| 17 | .1998 | 11113 | 100 | 19 | 17.3 | 35.8 | 18.2 | 6.1 | 3 | 0.5 | 1877 |
| 18 | .1995 | 10244 | 100 | 17.5 | 17.6 | 35.2 | 18.5 | 7.4 | 3 | 0.9 | 1961 |
| 19 | .1994 | 9972 | 100 | 17.5 | 17.1 | 35.3 | 18.9 | 7 | 3.3 | 0.8 | 1965 |
| 20 | .1992 | 9416 | 100 | 15.7 | 17.3 | 36.6 | 19 | 7 | 3.6 | 0.8 | 2012 |
| 21 | .1990 | 8905 | 100 | 16 | 16.9 | 35 | 19.4 | 8 | 3.9 | 0.9 | 2045 |
| 22 | .1988 | 8155 | 100 | 14.7 | 14.9 | 35.2 | 20.7 | 8.8 | 4.9 | 0.8 | 2147 |
| 23 | .1987 | 7854 | 100 | 14.2 | 14.9 | 35 | 19.7 | 9.3 | 5.5 | 1.4 | 2218 |
| 24 | .1986 | 7262 | 100 | 13.2 | 14.5 | 33.5 | 20.4 | 10.3 | 6.5 | 1.6 | 2302 |
| 25 | .1985 | 7226 | 100 | 11.4 | 12.6 | 32.9 | 23.1 | 10.9 | 7.1 | 2 | 2447 |
| 26 | .1984 | 6932 | 100 | 11.1 | 12.2 | 30.5 | 23.5 | 12 | 8.2 | 2.6 | 2558 |
| 27 | .1983 | 6657 | 100 | 10.1 | 11.8 | 28.7 | 23.3 | 13.8 | 9.5 | 3 | 2688 |
| 28 | .1982 | 6336 | 100 | 11 | 9.4 | 27.5 | 24.1 | 13.8 | 10.4 | 3.9 | 2783 |
| 29 | .1981 | 6122 | 100 | 9.5 | 10.1 | 27 | 24.6 | 14.1 | 9.9 | 4.9 | 2861 |
| 30 | .1980 | 5983 | 100 | 10.1 | 9.6 | 24.6 | 22.6 | 15.5 | 11.6 | 6 | 2988 |
| 31 | .1979 | 5868 | 100 | 9.8 | 9.9 | 24 | 22.5 | 15.4 | 13 | 5.4 | 2996 |
| 33 | .1977 | 5877 | 100 | 10.9 | 10.3 | 21.7 | 20.3 | 14.2 | 15.2 | 7.3 | 3132 |
| 34 | .1976 | 5684 | 100 | 10.2 | 9.6 | 21.7 | 22.7 | 15.8 | 13.9 | 6.2 | 3091 |
# Convert the index to integers
index = rows["Year"].astype(float) * 10000
rows.index = index.round().astype(int)
One of the challenges of the data in this chapter is that it summarizes the tails. For example, the Census data only go up to “Seven or more”.
But the effect of length-biased sampling depends strongly on the tail, so we have to make some guesses to fill in the values that have been summarized.
To do that, I’ll assume that the distribution of large family sizes is Poisson and fill in the tail accordingly.
I’ll use least_squares to search for parameters of the tail that best match the data.
from scipy.stats import poisson
from empiricaldist import Pmf
def make_poisson(mu, high=13):
"""Make a Poisson distribution.
mu: mean
high: upper bound
returns: Pmf
"""
xs = np.arange(0, high + 1)
pmf = Pmf(poisson.pmf(xs, mu), xs)
pmf.normalize()
return pmf
def make_model(mu, row, high=13):
"""Add a Poisson tail to a row of data.
mu: mean of the Poisson model
row: row of actual data
high: upper bound
returns: Pmf
"""
pmf = make_poisson(mu, high)
pmf[:5] = 0
actual = row.iloc[3:8].astype(float) / 100
pmf.normalize()
pmf *= 1 - actual.sum()
pmf[:5] = actual
return pmf
def error_func(params, row):
"""Error function used to find the mean.
params: list of parameters, in this case just mu
row: the row of actual data
returns: float
"""
mu = params[0]
pmf = make_model(mu, row)
error = pmf.mean() - row["Rate per 1000"] / 1000
return error
params = [2.0]
row = rows.loc[2018]
error_func(params, row)
-0.012207906747516262
from scipy.optimize import least_squares
def fit_row(row, high=13):
"""Find the value of mu that best fits the data.
row: row of actual data
high: upper bound
returns: Pmf
"""
# With a single parameter and a single error, it is
# overkill to use least_squares. But the fitting function
# later in this notebook is more complicated, so I kept them similar.
params = [2.0]
res = least_squares(error_func, x0=params, args=(row,))
mu = res.x[0]
pmf = make_model(mu, row, high)
return pmf
def subset_mean(subset):
"""Compute the mean of an incomplete Pmf.
subset: a conditional part of a Pmf
returns: float
"""
pmf = Pmf(subset, copy=True)
pmf.normalize()
return pmf.mean()
def plot_fit(row):
"""Plot the fitted model along with the original data.
row: actual data
"""
pmf = fit_row(row)
xs = [0, 1, 2, 3, 4, 5.5, 7.5]
xs[5] = subset_mean(pmf[5:7])
xs[6] = subset_mean(pmf[7:])
model = np.append(pmf[[0, 1, 2, 3, 4]], [sum(pmf[5:7]), sum(pmf[7:])])
plt.plot(xs, model)
actual = row.iloc[3:10].astype(float) / 100
plt.plot(xs, actual)
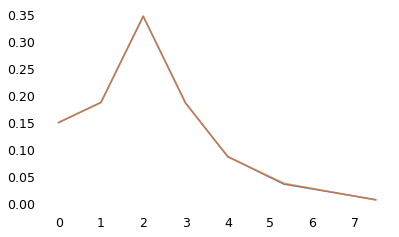
The following figure shows that the model, with a complete tail, yields summarized results like the original.
plot_fit(row)
def bias_pmf(pmf):
"""Compute the length-biased PMF.
pmf: Pmf
returns: Pmf
"""
ps = pmf.ps * pmf.qs
biased = Pmf(ps, pmf.qs)
biased.normalize()
return biased
row = rows.loc[2018]
model = fit_row(row)
model.mean()
2.0360000024952996
biased = bias_pmf(model)
biased.mean()
3.0017397260995224
def plot_percent(series, **options):
"""Plot a PMF as percentages."""
(series * 100).plot(alpha=0.4, **options)
from utils import decorate
plot_percent(model, marker="o", color="C1", label="Census 2018")
plot_percent(
biased, marker="s", color="C0", ls="--", label="Estimated family of orientation"
)
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family sizes",
)
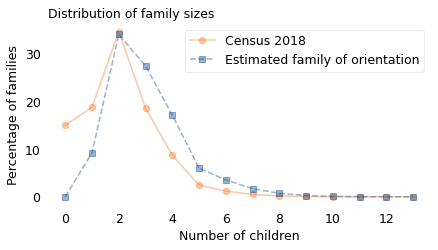
The circles show the percentage of women who bore each number of children. For example, about 15% of the women in the sample had no children; almost 35% of them had two.
Now, what would we see if we surveyed these children and asked them how many children their mothers had? Large families would be oversampled, small families would be undersampled, and families with no children would not appear at all. In general, a family with \(k\) children would appear in the sample \(k\) times.
So, if we take the distribution of family size from a sample of women, multiply each bar by the corresponding value of \(k\), and then divide through by the total, the result is the distribution of family size from a sample of children. In the previous figure, the square markers show this distribution.
As expected, children would report more large families (three or more children), fewer families with one child, and no families with zero children.
In general, the average family size is smaller if we survey women than if we survey their children. In this example, the average reported by women is close to 2; the average reported by their children would be close to 3.
So you might expect that, if family sizes reported by women get bigger, family sizes reported by children would get bigger, too. But that is not always the case, as we’ll see in the next section.
The Depression and the Baby Boom#
Preston used data from the U.S. Census Bureau to compare family sizes at several points between 1890 and 1970. Among the results, he finds:
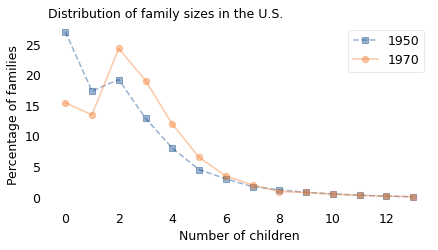
In 1950, the average family size reported by the women in the survey was 2.3. In 1970, it was 2.7. This increase was not surprising because the first group did most of their childbearing during the Great Depression, the second group mostly during the Baby Boom.
However, if we survey the children of these women, and ask about their mothers, the average in the 1950 sample would be 4.9; in the 1970 sample it would be 4.5. This decrease was surprising.
According to the women in the survey, families got bigger between 1950 and 1970, by almost half a child. According to their children, families got smaller during the same interval, by almost half a child.
Preston’s paper presents the distributions in a figure, so I used a graph digitizing tool to extract them numerically. Because this process introduces small errors, I adjusted the results to match the average family sizes Preston computed. The following figure shows these distributions.
# When I made this dataset, I didn't change the default labels for the columns.
family = pd.read_csv("preston_data.csv", skiprows=1)
family
| X | Y | X.1 | Y.1 | |
|---|---|---|---|---|
| 0 | -0.048717 | 0.270525 | -0.025345 | 0.154177 |
| 1 | 0.995326 | 0.173150 | 0.988026 | 0.134487 |
| 2 | 2.000930 | 0.192124 | 1.960587 | 0.242959 |
| 3 | 3.008009 | 0.128759 | 2.980574 | 0.190334 |
| 4 | 3.997074 | 0.080072 | 3.989164 | 0.119451 |
| 5 | 4.998472 | 0.044988 | 4.979379 | 0.065036 |
| 6 | 5.995842 | 0.029952 | 5.979842 | 0.034606 |
| 7 | 6.992782 | 0.017064 | 6.992206 | 0.019928 |
| 8 | 8.003205 | 0.012053 | 7.988714 | 0.009189 |
| 9 | 8.983352 | 0.007757 | 8.998418 | 0.007757 |
| 10 | 9.993272 | 0.005251 | 9.993343 | 0.004893 |
| 11 | 10.988053 | 0.003103 | 10.972987 | 0.003103 |
| 12 | 11.997757 | 0.001671 | 11.982691 | 0.001671 |
| 13 | 12.992323 | 0.000597 | 12.977257 | 0.000597 |
# Y contains the PMF values from 1950
pmf1950 = Pmf(family["Y"]).copy()
pmf1950.sum()
0.967064439140811
# Y.1 contains the PMF values from 1970
pmf1970 = Pmf(family["Y.1"]).copy()
pmf1970.sum()
0.9881861575178994
Here’s what the raw data look like.
plot_percent(pmf1950, label="1950", marker="s", ls="--")
plot_percent(pmf1970, label="1970", marker="o")
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family sizes in the U.S.",
)
The data past x=6 are not very accurate, and the PMFs are not normalized.
However, we also have the means of X and C to help us adjust the PMFs.
The following function takes mu, which is the Poisson parameter of the tail, and scale, which is the normalizing constant for the actual data, and returns a normalized PMF.
def make_model2(mu, scale, pmf):
"""Add a Poisson tail to a given dataset.
mu: mean
scale: multiplier
pmf: given distribution
returns: Pmf
"""
actual = pmf[:8] * scale
model = make_poisson(mu)
model[:8] = 0
model.normalize()
model *= 1 - actual.sum()
model[:8] = actual
return model
Now the job is to estimate the parameters to best fit the data.
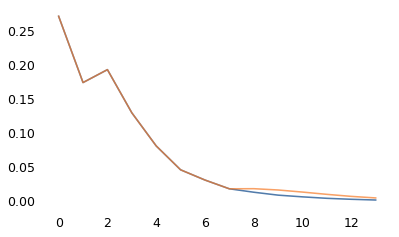
As a starting place, (8, 1) does ok.
model = make_model2(8, 1, pmf1950)
model.sum()
1.0
pmf1950.plot()
model.plot()
<Axes: >
But we can use least_squares to improve it. Here’s the error function.
def error_func2(params, pmf, stats):
"""Error function for fitting a model.
params: mu and scale
pmf: Pmf
stats: the mean of X and C
"""
mu, scale = params
model = make_model2(mu, scale, pmf)
error1 = model.mean() - stats[0]
biased = bias_pmf(model)
error2 = biased.mean() - stats[1]
return error1, error2
Here are the stats from 1950.
params = [8, 1]
stats = 2.292, 4.909
error_func2(params, pmf1950, stats)
(0.11168500538590553, 0.3107205927152643)
The following function finds the best fit and returns a Pmf.
def fit_pmf2(pmf, stats):
"""Find a model that reproduces the published summary stats.
pmf: given data
stats: mean of X and C
returns: Pmf
"""
params = [8, 1]
res = least_squares(error_func2, x0=params, args=(pmf, stats))
mu, scale = res.x
print("best", mu, scale)
model = make_model2(mu, scale, pmf)
return model
model1950 = fit_pmf2(pmf1950, stats)
best 7.918333883292639 1.015117690621446
The means of C and X are just about right.
biased = bias_pmf(model1950)
model1950.mean(), biased.mean(), stats
(2.2919999999999994, 4.909000000000001, (2.292, 4.909))
And the agreement looks good enough.
pmf1950.plot()
model1950.plot()
decorate()
Here’s the model for the 1970 data.
stats = 2.705, 4.461
model1970 = fit_pmf2(pmf1970, stats)
best 6.92744420810399 1.0005469812609125
biased = bias_pmf(model1970)
model1970.mean(), biased.mean(), stats
(2.7050000000000565, 4.460999999999886, (2.705, 4.461))
pmf1970.plot()
model1970.plot()
decorate()
Here are the two models.
plot_percent(model1950, label="Census 1950", marker="s", ls="--")
plot_percent(model1970, label="Census 1970", marker="o")
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family sizes in the U.S.",
)
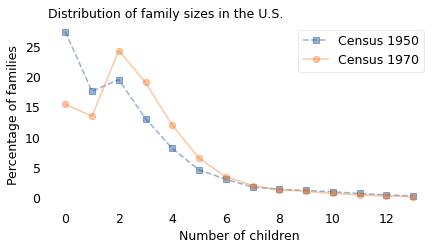
The biggest differences are in the left part of the curve. The women surveyed in 1950 were substantially more likely to have zero children or one, compared to women surveyed in 1970. They were less likely to have 2–5 children, and slightly more likely to have 9 or more.
Looking at it another way, family size was more variable in the 1950 cohort. The standard deviation of the distribution was about 2.4; in the 1970 cohort it was about 2.2. This variability is the reason for the difference between the two ways of measuring family size.
As Preston derived, there is a mathematical relationship between the average family size as reported by women, which he calls \(X\), and the average family size as reported by their children, which he calls \(C\).
\(C = X + V/X\)
where \(V\) is the variance of the distribution (the square of standard deviation).
Compared to 1950, \(X\) was bigger in 1970, but \(V\) was smaller; and as it turns out, \(C\) was smaller, too. That’s how family sizes can be bigger if we survey mothers and smaller if we survey their children.
pmf1950[0], model1950[0]
(0.2705250596658711, 0.27461477382324795)
pmf1970[0], model1970[0]
(0.1541766109785203, 0.15426094269559656)
model1950.std(), model1970.std()
(2.4491149421780922, 2.179444883450747)
X = model1950.mean()
C = X + model1950.var() / X
X, C
(2.2919999999999994, 4.909)
X = model1970.mean()
C = X + model1970.var() / X
X, C
(2.7050000000000565, 4.460999999999887)
More Recently#
With more recent Census data, we can see what has happened to family sizes since 1970.
from utils import make_lowess, plot_series_lowess
The following figure shows the average number of children born to women aged 40-44 when they were surveyed. The first cohort was interviewed in 1976, the last in 2018.
plot_series_lowess(
rows["Rate per 1000"] / 1000, label="Average family size", marker="d"
)
decorate(
ylabel="Number of children", title="Average family size 1976-2018", ylim=[0, 3.3]
)
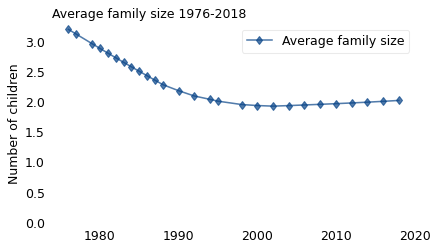
Between 1976 and 1990, average family size fell from more than 3 to less than 2. Since 2010, it has increased a little.
To see where those changes came from, let’s see how each part of the distribution has changed. The following figure shows the percentage of women with 0, 1, or 2 children, plotted over time.
plot_series_lowess(rows["Two"], label="2", marker="x")
plot_series_lowess(rows["One"], label="1", marker="+")
plot_series_lowess(rows["None"], label="0", marker="o")
decorate(
ylabel="Percentage of families",
title="Percentage of families with 0, 1, or 2 children",
ylim=[-3, 39],
loc="lower right",
)
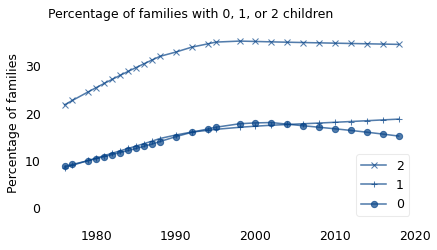
The fraction of small families has increased; most notably, between 1976 and 1990, the percentage of women with two children increased from 22% to 35%. The percentage of women with one child or zero also increased.
The following figure shows how the percentage of large families changed over the same period.
plot_series_lowess(rows["Three"], label="3", marker="^")
plot_series_lowess(rows["Four"], label="4", marker="s")
plot_series_lowess(rows["Five and six"], label="5-6", marker="p")
plot_series_lowess(rows["Seven or more"], label="7+", marker="8")
decorate(
ylabel="Percentage of families",
title="Percentage of families with 3 or more children",
ylim=[-1, 40],
)
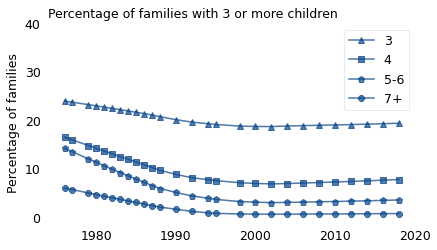
The proportion of large families declined substantially, especially the percentage of families with 5-6 children, which was 14% in 1976 and 4% in 2018. Over the same period, the percentage of families with seven or more children declined from 6% to less than 1%.
We can use this data to see how the two measures of family size have changed over time.
The following figure shows \(X\), which is the average number of children ever born to the women who were surveyed, and \(C\), which is the average we would measure if we surveyed their children.
for year in [1976, 1990, 1998, 2008, 2018]:
row = rows.loc[year]
model = fit_row(row)
biased = bias_pmf(model)
X = model.mean()
C = biased.mean()
print(year, X, C, C - X, row["Rate per 1000"])
1976 3.0910000000007147 4.433126835158552 1.342126835157837 3091
1990 2.045000038403182 3.055184644518847 1.010184606115665 2045
1998 1.8770000809557768 2.8402939128993694 0.9632938319435926 1877
2008 1.9010000215051315 2.8941684703733275 0.993168448868196 1901
2018 2.0360000024952996 3.0017397260995224 0.9657397236042229 2036
x_series = pd.Series(index=rows.index, dtype=float)
c_series = pd.Series(index=rows.index, dtype=float)
for year, row in rows.iterrows():
model = fit_row(row)
biased = bias_pmf(model)
x_series[year] = model.mean()
c_series[year] = biased.mean()
plot_series_lowess(c_series, label="Averaged over children, C", marker="o")
plot_series_lowess(x_series, label="Averaged over women, X", marker="x")
decorate(
ylabel="Average family size",
title="Two measures of average family size",
ylim=[0, 4.9],
)
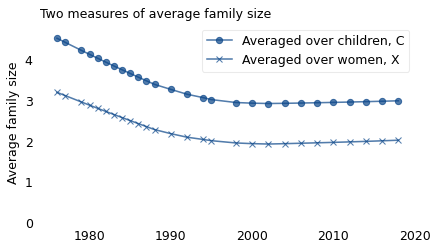
Between 1976 and 1990, the average family size reported by women, \(X\), decreased from 3.1 to 2.0. Over the same period, the average family size reported by children, \(C\), decreased from 4.4 to 2.8. Since 1990, \(X\) has been close to 2 and \(C\) has been close to 3.
Preston’s Paradox#
Now we are ready to explain the surprising result from the imaginary kingdom at the beginning of the chapter. In the scenario, the average family size was 3. Then we enacted a new law requiring every woman to have fewer children than her mother. In perfect compliance with the law, every woman had fewer children than her mother. Nevertheless, 25 years later the average family size was 3.3.
How is that possible?
As it happens, the numbers in the scenario are not contrived; they are based on the actual distribution of family size in the United States in 1979. Among the women who were interviewed that year, the average family size was close to 3.
Of course, nothing like the “fewer than mother” law was implemented in the U.S., and 25 years later the average family size was 1.9, not 3.3. But using the actual distribution as a starting place, we can simulate what would have happened in different scenarios.
First, let’s suppose that every woman has the same number of children as her mother. At first, you might think that the distribution of family size would not change, but that’s not right. In fact, family sizes would increase quickly.
As a small example, suppose there are only two families, one with two children and the other with four, so the average family size is three.
Assuming that half of the children are girls, in the next generation there would be one woman from a two-child family and two from a four-child family.
pmf = Pmf.from_seq([2, 4])
pmf.mean()
3.0
biased = bias_pmf(pmf)
biased.mean()
3.333333333333333
biased2 = bias_pmf(biased)
biased2.mean()
3.6
row = rows.loc[1979 + 25]
model = fit_row(row)
model.mean()
1.8950000219673087
row = rows.loc[1979]
model = fit_row(row)
model.mean()
2.9960000001442606
biased = bias_pmf(model)
biased.mean()
4.25534466920534
If each of these women has the same number of children as her mother, one would have two children and the other two would have four. So the average family size would be 3.33.
In the next generation, there would be one woman with two children, again, but there would be four with four. So the average family size would be 3.6.
In successive generations, the number of four-child families would increase exponentially, and the average family size would quickly approach 4.
We can do the same calculation with a more realistic distribution. In fact, it is the same calculation we used to compute the distribution of family size as reported by children. In the same way large families are overrepresented when we survey children, large families are overrepresented in the next generation if every woman has the same number of children as her mother.
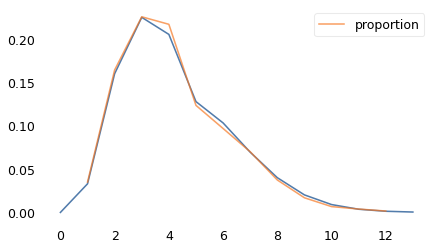
The following figure shows the actual distribution of family sizes from 1979 (solid line) and the result of this calculation, which simulates the “same as mother” scenario (dashed line).
plot_percent(model, label="Actual 1979", marker="o")
plot_percent(biased, label="Same as mother scenario", ls="--", marker="|", color="C4")
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family sizes",
)
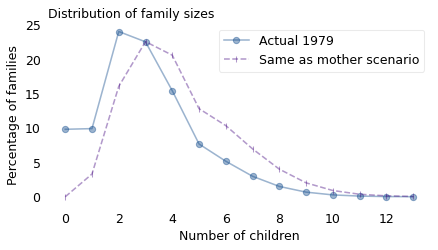
In the next generation, there are fewer small families and more big families, so the distribution is shifted to the right. The mean of the original distribution is 3; the mean of the simulated distribution is 4.3.
If we repeat the process, the average family size would be 5.2 in the next generation, 6.1 in the next, and 6.9 in the next. Eventually, nearly all women would have 13 children, which is the maximum in this dataset.
for i in range(2, 6):
biased = bias_pmf(biased)
print(i, biased.mean())
2 5.205672599164491
3 6.10968948800601
4 6.924225284367675
5 7.637134370388916
Observing this pattern, Preston explains:
The implications for population growth are obvious. Members of each generation must, on average, bear substantially fewer children than were born into their own family of orientation merely to keep population fertility rates constant.
So let’s see what happens if we follow Preston’s advice.
Technical Note#
The following simulations are intended to confirm that the results we just computed are correct.
def simulate(sample, p=0):
"""Simulate the same as mother or one less models.
sample: sample of family sizes
p: probability of having one child less than, or the same as, one's mother
returns: sample of next generation
"""
res = []
for k in sample:
if k == 0:
continue
children = np.random.choice([k - 1, k], size=k, p=[p, 1 - p])
res.extend(children)
# return a random sample of half of the children
index = np.where(np.random.choice(2, size=len(res)))
return np.array(res)[index]
Generate a sample from the model to start.
gen0 = model.sample(10000).astype(int)
gen0.mean()
2.964
Simulate the next generation.
gen1 = simulate(gen0, p=0)
gen1.mean()
4.1827000808407435
Compare the simulation results to the biased model.
biased = bias_pmf(model)
biased.plot()
Pmf.from_seq(gen1).plot()
decorate()
One Child Fewer#
Suppose every woman has precisely one child fewer than her mother. We can simulate this behavior by computing the biased distribution, as in the previous section, and then shifting the result one child to the left.
The following figure shows the actual distribution from 1979 again, along with the result of this simulation.
def shift_pmf(pmf):
"""Shift the values to the left by one.
pmf: Pmf
returns: Pmf
"""
qs = pmf.qs[:-1]
ps = pmf.ps[1:]
return Pmf(ps, qs)
row = rows.loc[1979]
model = fit_row(row)
model.mean()
2.9960000001442606
biased = bias_pmf(model)
biased.mean()
4.25534466920534
shifted = shift_pmf(biased)
shifted.mean()
3.25534466920534
plot_percent(model, label="Actual 1979", marker="o")
plot_percent(shifted, label="One child fewer scenario", ls="--", marker="x", color="C2")
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family sizes",
)
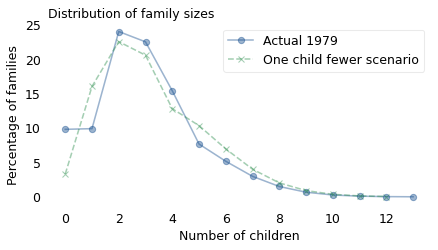
The simulated distribution has been length-biased, which increases the average, and then shifted to the left, which decreases the average. In general, the net effect could be an increase or a decrease; in this example, it’s an increase from 3.0 to 3.3.
In The Long Run#
If we repeat this process and simulate the next generation, the average family size increases again, to 3.5. In the next generation it increases to 3.8.
It might seem like it would increase forever, but if every woman has one child fewer than her mother, in each generation the maximum family size decreases by one. So eventually the average comes down.
The following figure shows the average family size over 10 generations, where Generation 0 follows the actual distribution from 1979.
sizes = pd.Series([], dtype=float)
sizes[0] = model.mean()
shifted = model.copy()
for i in range(1, 10):
shifted = shift_pmf(bias_pmf(shifted))
sizes[i] = shifted.mean()
sizes
0 2.996000
1 3.255345
2 3.497601
3 3.797560
4 3.937929
5 3.910277
6 3.776723
7 3.553760
8 3.220451
9 2.768708
dtype: float64
sizes.plot(label='Family size', marker='s')
decorate(xlabel='Generation number',
ylabel='Average family size',
ylim=[0, 4.8],
title='Average family size over ten generations')
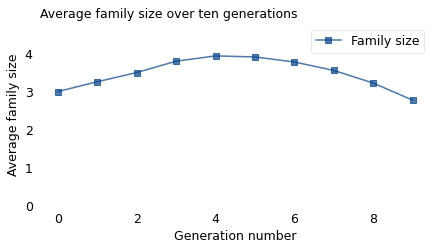
Family size would increase for four generations, peaking at 3.9. Then it would take another five generations to fall below the starting value. At 25 years per generation, that means it would take more than 200 years for the new law to have the desired effect.
In Reality#
Of course, no such law was in effect in the United States between 1979 and 1990. Nevertheless, the average family size fell from close to 3 to close to 2. That’s an enormous change in less than one generation. How is that even possible? We’ve seen that it is not enough if every woman has one child fewer than her mother; the actual difference must have been larger.
In fact, the difference was about 2.3. To see why, remember that the average family size, as seen by the children of the women surveyed in 1979, was 4.3. But when those children grew up and the women among them were surveyed in 1990, they reported an average family size close to 2. So on average, they had 2.3 fewer children than their mothers.
The following function simulates a generation where each woman has 2-3 children fewer than her mother.
def simulate3(sample, p=0):
"""Simulate a scenario where people have 2-3 children less than their mother did.
sample: sample of family sizes
p: probability of having three less than one's mother
returns: sample of next generation
"""
res = []
everybody = []
for k in sample:
if k == 0:
continue
everybody.extend([k] * k)
if k < 3:
children = [0] * k
else:
children = np.random.choice([k - 3, k - 2], size=k, p=[p, 1 - p])
res.extend(children)
everybody = np.array(everybody)
res = np.array(res)
diff = everybody - res
print(everybody.mean(), res.mean(), diff.mean())
# return a randomly-chosen half of the children
index = np.where(np.random.choice(2, size=len(res)))
return res[index]
sample = [0, 1, 2, 3]
simulate3(sample, 0)
2.3333333333333335 0.5 1.8333333333333333
array([0])
row = rows.loc[1979]
model = fit_row(row)
model.mean()
2.9960000001442606
biased = bias_pmf(model)
biased.mean()
4.25534466920534
sample = model.sample(10000).astype(int)
sample.mean()
2.973
By adjusting the parameter p, we can find a simulation that roughly reproduces the changes in fertility between 1979 and 1990.
gen1 = simulate3(sample, p=0.33)
gen1.mean()
4.237672384796502 2.003363605785402 2.2343087790111
2.0061907004912185
In the Present#
The women surveyed in 1990 had 2.3 fewer children than their mothers, on average. If that pattern had continued for another generation, the average family size in 2018 would have been about 0.8.
row = rows.loc[1990]
model = fit_row(row)
model.mean()
2.045000038403182
sample = model.sample(10000).astype(int)
sample.mean()
2.0441
gen1 = simulate3(sample, p=0.6)
gen1.mean()
3.0621300327772616 0.8037767232522871 2.258353309524974
0.8013968129057644
But it wasn’t. In fact, the average family size in 2018 was very close to 2, just as in 1990. So how did that happen?
As it turns out, this is close to what we would expect if every woman had one child fewer than her mother. The following distribution shows the actual distribution in 2018, compared to the result if we start with the 1990 distribution and simulate the “one child fewer” scenario.
row = rows.loc[1990]
model1990 = fit_row(row)
model1990.mean()
2.045000038403182
shifted = shift_pmf(bias_pmf(model1990))
shifted.mean()
2.055184644518847
row = rows.loc[2018]
model2018 = fit_row(row)
model2018.mean()
2.0360000024952996
def make_pmf_from_model(model):
"""Make a Pmf with the same index as the data.
model: Pmf with a complete tail
returns: Pmf
"""
index = [0, 1, 2, 3, 4, "5-6", "7+"]
ps = model[0:7].copy().values
ps[5] += ps[6]
ps[6] = model[7:].sum()
return Pmf(ps, index)
def make_pmf_from_row(row):
"""Make a Pmf from a row of data.
row: Series
returns: Pmf
"""
actual = row.iloc[3:10].astype(float) / 100
index = [0, 1, 2, 3, 4, "5-6", "7+"]
pmf = Pmf(actual.values, index)
return pmf
row = rows.loc[2018]
pmf = make_pmf_from_row(row)
plot_percent(pmf, label="Actual 2018", color="C1", marker="o")
pmf = make_pmf_from_model(shifted)
plot_percent(pmf, label="Predicted from 1990", marker="s", ls="--")
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family size",
)
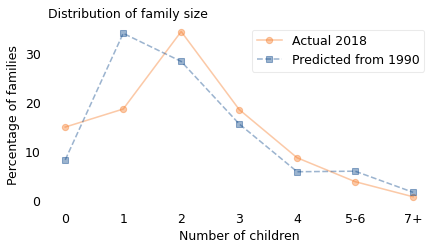
The means of the two distributions are almost the same, but the shapes are different. In reality, there were more zero- and two-child families in 2018 than the simulation predicts, and fewer one-child families. But at least on average, it seems like women in the U.S. have been following the “one child fewer” policy for the last 30 years.
The scenario at the beginning of this chapter is meant to be light-hearted, but in reality governments in many places and times have enacted policies meant to control family sizes and population growth. Most famously, China implemented a one-child policy in 1980 that imposed severe penalties on families with more than one child. Of course, this policy is objectionable to anyone who considers reproductive freedom a fundamental human right. But even as a practical matter, the unintended consequences were profound.
Rather than catalog them, I will mention one that is particularly ironic: while this policy was in effect, economic and social forces reduced the average desired family size so much that, when the policy was relaxed in 2015 and again in 2021, average lifetime fertility increased to only 1.3, far below the level needed to keep the population constant, near 2.1. Since then, China has implemented new policies intended to increase family sizes, but it is not clear whether they will have much effect. Demographers predict that by the time you read this, the population of China will probably be shrinking. The consequences of the one-child policy are widespread and will affect China and the rest of the world for a long time.
Technical Note: The Poisson distribution#
Suppose every year, for 20 years, you roll a 10-sided die, and every year, if you roll a 10, you have a baby. On average, you would have a total of two babies. But as the dice fall, you might have more or fewer. Across the population, what would the distribution of family size look like?
Under these assumptions, it would follow the Poisson distribution, named after French mathematician Siméon Denis Poisson, who wrote about it in 1837, modeling the number of wrongful criminal convictions per year.
The Poisson distribution is relevant to Preston’s Paradox for two reasons:
Since 1990, the distribution of family size in the U.S. has come to resemble a Poisson distribution.
Under the “one child fewer” policy, the Poisson distribution is completely unchanged from one generation to the next.
The following figure demonstrates the first point.
def make_pmf_from_poisson(mu):
"""Make a Poisson distribution and summarize it.
mu: mean of the distribution
returns: Pmf
"""
index = [0, 1, 2, 3, 4, "5-6", "7+"]
ps = poisson.pmf([0, 1, 2, 3, 4, 5, 6], mu)
ps[5] += ps[6]
ps[6] = poisson.sf(6, mu)
return Pmf(ps, index)
for year in rows.index[:15]:
pmf = make_pmf_from_row(rows.loc[year])
label = "Actual 1990 - 2018" if year == 2018 else ""
pmf.plot.bar(label=label, color="C1", alpha=0.02)
pmf = make_pmf_from_poisson(2)
pmf.plot(label="Poisson distribution", marker="s")
decorate(
xlabel="Number of children",
ylabel="Percentage of families",
title="Distribution of family size and Poisson model",
)
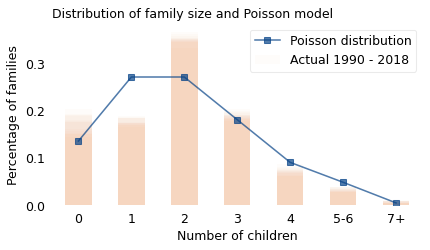
The bars show the actual distributions for selected years from 1990 to 2018, with the shaded areas representing variation from year to year. The line shows a Poisson distribution with an average value of 2, which is close to the actual average during this interval.
In reality, there are more zero- and two-child families than we would expect from a Poisson distribution, and fewer one-child families. But given the complexities of childbearing, it is surprising that the simple dice-rolling model does as well as this.
Now suppose that the family sizes actually follow a Poisson distribution, and let’s see what happens in the “one child fewer” scenario. The following figure shows three distributions:
A Poisson distribution with mean 2, plotted with bars,
The biased distribution of family size we would see if we surveyed children, plotted with a dashed line, and
The distribution of family size those children would have under the “one child fewer” policy, plotted with a dotted line.
model = make_poisson(2)
model.mean()
1.9999996439174659
biased = bias_pmf(model)
biased.mean()
2.999997685463117
shifted = shift_pmf(biased)
shifted.mean()
1.999997685463117
model[:13].plot.bar(label="Poisson distribution", color="C1", alpha=0.5)
biased[1:].plot(label="Biased", ls="--", marker="^")
shifted.plot(label="Biased and shifted", color="C2", ls=":", marker="x")
decorate(xlabel="Number of children", ylabel="Fraction of families", title="")
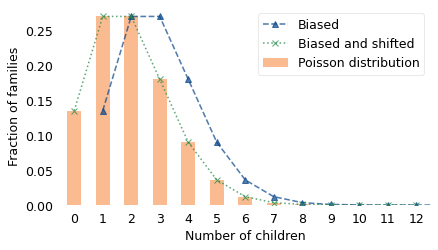
The biased distribution is identical to the original distribution, but shifted to the right by one. When we apply the “one child fewer” policy, it shifts the distribution to the left by one, right back where it started.