The Principal Components of Anthropometry#
In a previous post I explored the correlations between measurements in the ANSUR-II dataset, which includes 93 measurements from a sample of U.S. military personnel. I found that measurements of the head were weakly correlated with measurements from other parts of the body – and in particular the protrusion of the ears is almost entirely uncorrelated with anything else.
A friend of mine, and co-developer of the Modeling and Simulation class I taught at Olin, asked whether I had tried running principal component analysis (PCA). I had not, but now I have. Let’s look at the results.
Click here to run this notebook on Colab.
The data#
Here’s the ANSUR data, originally downloaded from The OPEN Design Lab.
download("https://github.com/AllenDowney/ProbablyOverthinkingIt/raw/book/data/ANSURIIFEMALEPublic.csv")
download("https://github.com/AllenDowney/ProbablyOverthinkingIt/raw/book/data/ANSURIIMALEPublic.csv")
Since heights are in mm, I converted to cm.
def add_earratio(df):
df['earratio'] = df['earprotrusion'] / df['earbreadth']
ansur_male[measurements]
| abdominalextensiondepthsitting | acromialheight | acromionradialelength | anklecircumference | axillaheight | balloffootcircumference | balloffootlength | biacromialbreadth | bicepscircumferenceflexed | bicristalbreadth | ... | verticaltrunkcircumferenceusa | waistbacklength | waistbreadth | waistcircumference | waistdepth | waistfrontlengthsitting | waistheightomphalion | weightkg | wristcircumference | wristheight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 266 | 1467 | 337 | 222 | 1347 | 253 | 202 | 401 | 369 | 274 | ... | 1700 | 501 | 329 | 933 | 240 | 440 | 1054 | 815 | 175 | 853 |
| 1 | 233 | 1395 | 326 | 220 | 1293 | 245 | 193 | 394 | 338 | 257 | ... | 1627 | 432 | 316 | 870 | 225 | 371 | 1054 | 726 | 167 | 815 |
| 2 | 287 | 1430 | 341 | 230 | 1327 | 256 | 196 | 427 | 408 | 261 | ... | 1678 | 472 | 329 | 964 | 255 | 411 | 1041 | 929 | 180 | 831 |
| 3 | 234 | 1347 | 310 | 230 | 1239 | 262 | 199 | 401 | 359 | 262 | ... | 1625 | 461 | 315 | 857 | 205 | 399 | 968 | 794 | 176 | 793 |
| 4 | 250 | 1585 | 372 | 247 | 1478 | 267 | 224 | 435 | 356 | 263 | ... | 1679 | 467 | 303 | 868 | 214 | 379 | 1245 | 946 | 188 | 954 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4077 | 235 | 1353 | 312 | 216 | 1263 | 228 | 193 | 384 | 318 | 241 | ... | 1557 | 442 | 279 | 816 | 210 | 347 | 1016 | 675 | 163 | 778 |
| 4078 | 247 | 1473 | 336 | 234 | 1346 | 253 | 196 | 428 | 374 | 284 | ... | 1715 | 475 | 351 | 978 | 235 | 385 | 1082 | 896 | 178 | 873 |
| 4079 | 264 | 1394 | 313 | 227 | 1280 | 245 | 193 | 407 | 367 | 271 | ... | 1682 | 483 | 333 | 991 | 258 | 353 | 1011 | 832 | 178 | 822 |
| 4080 | 203 | 1417 | 327 | 223 | 1314 | 250 | 196 | 419 | 365 | 271 | ... | 1589 | 430 | 293 | 783 | 192 | 350 | 1062 | 731 | 172 | 837 |
| 4081 | 327 | 1523 | 358 | 226 | 1408 | 269 | 225 | 442 | 379 | 275 | ... | 1764 | 511 | 354 | 1080 | 294 | 389 | 1119 | 985 | 182 | 894 |
4082 rows × 93 columns
df = ansur_male[measurements]
Principle Component Analysis#
As you might guess from the comments below, I used ChatGPT to generate a lot of the code. It took some revision to get it working, but the head start definitely saved me some time.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# In this example, we will first standardize the data and then perform PCA.
# Step 3.1: Create a StandardScaler step
scaler = StandardScaler()
# Step 3.2: Create a PCA step
pca = PCA(n_components=10)
# Step 4: Create the pipeline
steps = [
('scaler', scaler), # Standardize the data
('pca', pca) # Perform PCA
]
pipeline = Pipeline(steps)
# Fit the pipeline to your data
pipeline.fit(df)
# Now, you can access the transformed data and principal components if needed.
transformed_data = pipeline.transform(df) # Transformed data after PCA
principal_components = pca.components_ # Principal components (eigenvectors)
# You can also access the explained variance ratio to see how much variance is explained by each component.
explained_variance_ratio = pca.explained_variance_ratio_
explained_variance_ratio
array([0.44234507, 0.1749688 , 0.04206542, 0.03248163, 0.0228476 ,
0.02117352, 0.01887385, 0.01486304, 0.01423664, 0.01332959])
Here’s a visualization of explained variance versus number of components. I lifted this from The Python Data Science Handbook.
ys = np.cumsum(pca.explained_variance_ratio_)
xs = np.arange(len(ys)) + 1
ys
array([0.44234507, 0.61731386, 0.65937928, 0.69186091, 0.71470851,
0.73588203, 0.75475588, 0.76961892, 0.78385556, 0.79718515])
plt.bar(xs, ys)
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance')
plt.savefig('ansur_pca1.png', dpi=300)
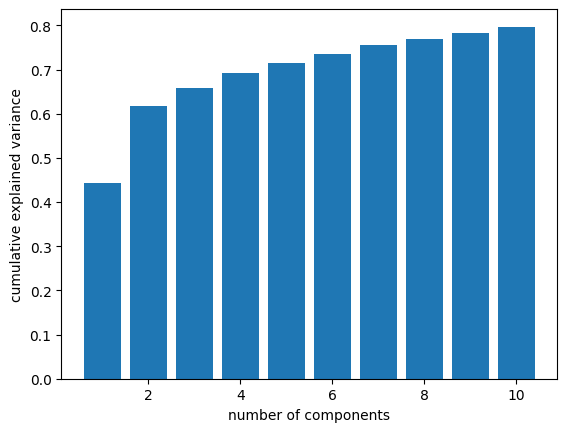
With one component, we can capture 44% of the variation in the measurements. With two components, we’re up to 62%. After that, the gains are smaller (as we expect), but with 10 measurements, we get up to 78%.
Loadings#
Looking at the loadings, we can see which measurements contribute the most to each of the components, so we can get a sense of which characteristics each component captures.
loadings = pca.components_ # Get the loadings (eigenvectors)
# Create a DataFrame to store the loadings with feature names as columns
loadings_df = pd.DataFrame(loadings, columns=measurements)
loadings_df
| abdominalextensiondepthsitting | acromialheight | acromionradialelength | anklecircumference | axillaheight | balloffootcircumference | balloffootlength | biacromialbreadth | bicepscircumferenceflexed | bicristalbreadth | ... | verticaltrunkcircumferenceusa | waistbacklength | waistbreadth | waistcircumference | waistdepth | waistfrontlengthsitting | waistheightomphalion | weightkg | wristcircumference | wristheight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.085451 | -0.134108 | -0.116021 | -0.100365 | -0.127055 | -0.105897 | -0.112045 | -0.108305 | -0.092030 | -0.103360 | ... | -0.124746 | -0.094822 | -0.097267 | -0.095846 | -0.087184 | -0.082944 | -0.114016 | -0.131211 | -0.115607 | -0.120198 |
| 1 | -0.162882 | 0.099494 | 0.106095 | -0.092119 | 0.123047 | -0.037801 | 0.064844 | -0.017398 | -0.141551 | -0.055853 | ... | -0.096331 | -0.038278 | -0.157748 | -0.165992 | -0.161084 | -0.061621 | 0.150431 | -0.126668 | -0.062109 | 0.048192 |
| 2 | -0.014402 | -0.122855 | 0.012458 | 0.022607 | -0.112586 | 0.073197 | 0.118906 | 0.059999 | 0.103362 | -0.135291 | ... | -0.167968 | -0.179771 | -0.081043 | -0.045145 | -0.021008 | -0.228018 | -0.030051 | -0.003646 | 0.042591 | -0.216040 |
| 3 | 0.173902 | 0.015067 | 0.085738 | -0.166805 | 0.009402 | -0.247006 | -0.099514 | -0.044511 | 0.032614 | 0.021519 | ... | -0.000912 | 0.023724 | 0.131986 | 0.161486 | 0.181409 | -0.043193 | 0.010563 | 0.055897 | -0.153280 | -0.019526 |
| 4 | 0.067083 | 0.015880 | -0.052733 | 0.179441 | 0.008818 | 0.148798 | 0.102851 | -0.291578 | 0.025634 | 0.022352 | ... | 0.014742 | 0.006071 | 0.053438 | 0.058207 | 0.067641 | -0.048584 | -0.011554 | 0.043999 | 0.064798 | 0.057537 |
| 5 | 0.068603 | 0.045339 | 0.009396 | -0.080556 | 0.034854 | -0.067952 | -0.008425 | -0.210178 | -0.060257 | 0.028790 | ... | 0.014812 | 0.083023 | 0.029290 | 0.050304 | 0.071416 | 0.007212 | -0.017477 | 0.003683 | -0.105896 | 0.075637 |
| 6 | 0.093660 | 0.012428 | 0.032023 | -0.109354 | -0.004740 | 0.024016 | 0.038469 | -0.041117 | -0.045251 | 0.026545 | ... | 0.018426 | 0.284304 | 0.027542 | 0.069994 | 0.116852 | 0.202127 | -0.123815 | -0.022750 | 0.095576 | 0.009357 |
| 7 | -0.050239 | 0.062544 | -0.112495 | -0.012928 | 0.049113 | -0.001771 | 0.077509 | -0.010888 | 0.096296 | 0.019468 | ... | -0.008819 | 0.041587 | -0.065475 | -0.050950 | -0.027480 | -0.143207 | 0.059189 | 0.006680 | 0.022722 | 0.201584 |
| 8 | -0.003643 | -0.040762 | 0.010628 | 0.126513 | -0.037450 | 0.077418 | 0.139245 | 0.112175 | -0.130013 | 0.253391 | ... | -0.067305 | 0.181409 | 0.108766 | 0.052406 | 0.018824 | -0.061912 | -0.047037 | 0.006009 | -0.103649 | -0.046352 |
| 9 | 0.087035 | -0.013592 | 0.074065 | -0.045918 | -0.003512 | -0.102444 | 0.027862 | 0.003437 | -0.009817 | -0.076497 | ... | 0.053154 | 0.227852 | 0.021863 | 0.073011 | 0.097022 | 0.269341 | -0.128553 | 0.027776 | -0.010761 | -0.086203 |
10 rows × 93 columns
loadings_transposed = loadings_df.transpose()
loadings_transposed
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| abdominalextensiondepthsitting | -0.085451 | -0.162882 | -0.014402 | 0.173902 | 0.067083 | 0.068603 | 0.093660 | -0.050239 | -0.003643 | 0.087035 |
| acromialheight | -0.134108 | 0.099494 | -0.122855 | 0.015067 | 0.015880 | 0.045339 | 0.012428 | 0.062544 | -0.040762 | -0.013592 |
| acromionradialelength | -0.116021 | 0.106095 | 0.012458 | 0.085738 | -0.052733 | 0.009396 | 0.032023 | -0.112495 | 0.010628 | 0.074065 |
| anklecircumference | -0.100365 | -0.092119 | 0.022607 | -0.166805 | 0.179441 | -0.080556 | -0.109354 | -0.012928 | 0.126513 | -0.045918 |
| axillaheight | -0.127055 | 0.123047 | -0.112586 | 0.009402 | 0.008818 | 0.034854 | -0.004740 | 0.049113 | -0.037450 | -0.003512 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| waistfrontlengthsitting | -0.082944 | -0.061621 | -0.228018 | -0.043193 | -0.048584 | 0.007212 | 0.202127 | -0.143207 | -0.061912 | 0.269341 |
| waistheightomphalion | -0.114016 | 0.150431 | -0.030051 | 0.010563 | -0.011554 | -0.017477 | -0.123815 | 0.059189 | -0.047037 | -0.128553 |
| weightkg | -0.131211 | -0.126668 | -0.003646 | 0.055897 | 0.043999 | 0.003683 | -0.022750 | 0.006680 | 0.006009 | 0.027776 |
| wristcircumference | -0.115607 | -0.062109 | 0.042591 | -0.153280 | 0.064798 | -0.105896 | 0.095576 | 0.022722 | -0.103649 | -0.010761 |
| wristheight | -0.120198 | 0.048192 | -0.216040 | -0.019526 | 0.057537 | 0.075637 | 0.009357 | 0.201584 | -0.046352 | -0.086203 |
93 rows × 10 columns
num_top_features = 5
# Iterate through each principal component
for i, col in loadings_transposed.items():
print(f"Principal Component {i+1}:")
# Sort the features by absolute loading values for the current principal component
sorted_features = col.sort_values(key=abs, ascending=False)
# Select the top N features with the highest absolute loadings
top_features = sorted_features[:num_top_features].round(3)
# Print the top correlated factors for the current principal component
for name, val in top_features.items():
print(-val, '\t', name)
print()
Principal Component 1:
0.135 suprasternaleheight
0.134 cervicaleheight
0.134 buttockkneelength
0.134 acromialheight
0.133 kneeheightsitting
Principal Component 2:
0.166 waistcircumference
-0.163 poplitealheight
0.163 abdominalextensiondepthsitting
0.161 waistdepth
0.159 buttockdepth
Principal Component 3:
0.338 elbowrestheight
0.31 eyeheightsitting
0.307 sittingheight
0.228 waistfrontlengthsitting
-0.225 heelbreadth
Principal Component 4:
0.247 balloffootcircumference
0.232 bimalleolarbreadth
0.22 footbreadthhorizontal
0.218 handbreadth
0.212 sittingheight
Principal Component 5:
0.319 interscyeii
0.292 biacromialbreadth
0.275 shoulderlength
0.273 interscyei
0.184 shouldercircumference
Principal Component 6:
-0.34 headcircumference
-0.321 headbreadth
0.316 shoulderlength
-0.277 tragiontopofhead
-0.262 interpupillarybreadth
Principal Component 7:
0.374 crotchlengthposterioromphalion
-0.321 earbreadth
-0.298 earlength
-0.284 waistbacklength
0.253 crotchlengthomphalion
Principal Component 8:
0.472 earprotrusion
0.346 earlength
0.215 crotchlengthposterioromphalion
-0.202 wristheight
0.195 overheadfingertipreachsitting
Principal Component 9:
-0.299 tragiontopofhead
0.294 crotchlengthposterioromphalion
-0.253 bicristalbreadth
-0.228 shoulderlength
0.189 neckcircumferencebase
Principal Component 10:
0.406 earbreadth
0.356 earprotrusion
-0.269 waistfrontlengthsitting
0.239 earlength
-0.228 waistbacklength
I won’t explain all of the measurements, but if there are any you are curious about, you can look them up in The Measurer’s Handbook which includes details on “sampling strategy and measuring techniques” as well as descriptions and diagrams of the landmarks and measurements between them.
Not surprisingly, the first component is loaded with measurements of height. If you want to predict someone’s measurements, and can only use one number, choose height.
The second component is loaded with measurements of girth. Again, no surprises so far.
The third component seems to capture torso length. And that makes sense, too. One you know how tall someone is, it helps to know how that height is split between torso and legs.
The fourth component seems to capture hand and foot size (with sitting height thrown in just to remind us that PCA is not obligated to find components that align perfectly with the axes we expect).
Component 5 is all about the shoulders.
Component 6 is all about the head.
After that, things are not so neat. But two things are worth noting:
Component 7 is mostly related to the dimensions of the pelvis, but…
Components 7, 8, and 10 are surprisingly loaded up with ear measurements.
As we saw in the previous article, there seems to be something special about ears. Once you have exhausted the information carried by the most obvious measurements, the dimensions of the ear seem to be strangely salient.
Using the pca module#
I found this module and decided to experiment with it.
try:
from pca import pca
except ImportError:
!pip install pca
from pca import pca
model = pca(normalize=True, n_components=10)
model.fit_transform(df);
[pca] >Extracting column labels from dataframe.
[pca] >Extracting row labels from dataframe.
[pca] >Normalizing input data per feature (zero mean and unit variance)..
[pca] >The PCA reduction is performed on the [93] columns of the input dataframe.
[pca] >Fit using PCA.
[pca] >Compute loadings and PCs.
[pca] >Compute explained variance.
[pca] >Outlier detection using Hotelling T2 test with alpha=[0.05] and n_components=[10]
[pca] >Multiple test correction applied for Hotelling T2 test: [fdr_bh]
[pca] >Outlier detection using SPE/DmodX with n_std=[3]
model.plot();
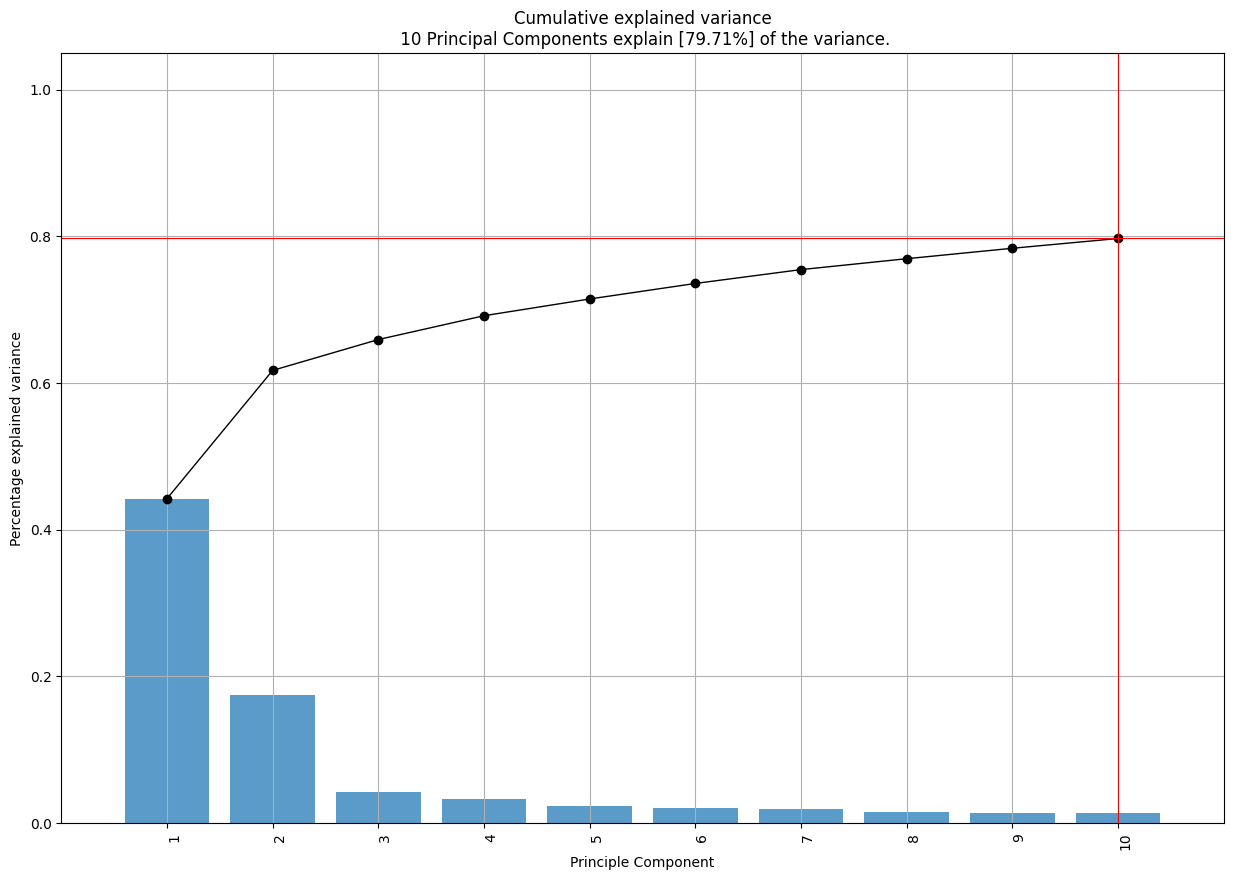
Unfortunately, the most interesting plots don’t seem to work well with the number of dimensions in this dataset. I’d be curious to know if they can be tuned to work better.
model.biplot3d();
[scatterd] >INFO> Create scatterplot
[pca] >Plot PC1 vs PC2 vs PC3 with loadings.
Copyright 2023 Allen Downey
The code in this notebook and utils.py is under the MIT license.