The second edition of Think DSP is not for sale yet, but if you would like to support this project, you can buy me a coffee.
Pink Noise#
Click here to run this notebook on Colab.
import numpy as np
import matplotlib.pyplot as plt
from thinkdsp import decorate
def correlated_standard_normal(rho):
"""Generates standard normal variates with correlation.
rho: target coefficient of correlation
returns: iterable
"""
x = np.random.normal(0, 1)
yield x
sigma = np.sqrt(1 - rho**2)
while True:
x = np.random.normal(x * rho, sigma)
yield x
it = correlated_standard_normal(0.5)
xs = [next(it) for i in range(1000)]
plt.plot(xs)
[<matplotlib.lines.Line2D at 0x7f280e74d880>]
def serial_corr(xs):
"""Computes the serial correlation of a sequence."""
return np.corrcoef(xs[:-1], xs[1:])
serial_corr(xs)
array([[1. , 0.485144],
[0.485144, 1. ]])
def correlated_normal(mu, sigma, rho, n):
"""Generates normal variates with correlation.
mu: mean of variate
sigma: standard deviation of variate
rho: target coefficient of correlation
Returns: iterable
"""
it = correlated_standard_normal(rho)
xs = [next(it) for i in range(n)]
return np.array(xs) * sigma + mu
xs = correlated_normal(10, 1, 0.5, 2048 * 100)
xs.mean(), xs.std(), serial_corr(xs)
(9.99732427526079,
1.001225417192759,
array([[1. , 0.501498],
[0.501498, 1. ]]))
from scipy.signal import welch
nperseg = 2048
freqs, spectrum = welch(xs, nperseg=nperseg, fs=nperseg)
plt.plot(freqs, spectrum)
plt.xscale('log')
plt.yscale('log')
import numpy as np
from scipy.stats import geom
n = 100 + 2048 * 1024
a = np.zeros(n)
p = 0.5
lag = geom(p).rvs(n)
np.max(lag)
23
rho = 0.5
sigma = np.sqrt(1 - rho)
for i in range(100, n):
x = a[i-lag[i]]
a[i] = np.random.normal(x, sigma)
xs = a[100:]
np.log2(len(xs))
21.0
plt.plot(a[100:])
[<matplotlib.lines.Line2D at 0x7f27e98d5d90>]
nperseg = 4096
freqs, spectrum = welch(xs, nperseg=nperseg, fs=nperseg)
plt.plot(freqs, spectrum)
plt.xscale('log')
plt.yscale('log')
freqs[400]
400.0
from scipy.stats import linregress
def log_dropna(xs):
return np.drop
linregress(np.log(freqs[1:400]), np.log(spectrum[1:400]))
LinregressResult(slope=-1.8589617850261244, intercept=3.4602295935778464, rvalue=-0.9977382507406116, pvalue=0.0, stderr=0.006285648733561966, intercept_stderr=0.03200726199763073)
Generating pink noise#
The Voss algorithm is described in this paper:
Voss, R. F., & Clarke, J. (1978). “1/f noise” in music: Music from 1/f noise”. Journal of the Acoustical Society of America 63: 258–263. Bibcode:1978ASAJ…63…258V. doi:10.1121/1.381721.
And presented by Martin Gardner in this Scientific American article:
Gardner, M. (1978). “Mathematical Games—White and brown music, fractal curves and one-over-f fluctuations”. Scientific American 238: 16–32.
McCartney suggested an improvement here:
http://www.firstpr.com.au/dsp/pink-noise/
And Trammell proposed a stochastic version here:
http://home.earthlink.net/~ltrammell/tech/pinkalg.htm
The fundamental idea of this algorithm is to add up several sequences of random numbers that get updated at different rates. The first source should get updated at every time step; the second source every other time step, the third source ever fourth step, and so on.
In the original algorithm, the updates are evenly spaced. In the stochastic version, they are randomly spaced.
My implementation starts with an array with one row per timestep and one column for each of the white noise sources. Initially, the first row and the first column are random and the rest of the array is Nan.
nrows = 100
ncols = 5
array = np.full((nrows, ncols), np.nan)
array[0, :] = np.random.random(ncols)
array[:, 0] = np.random.random(nrows)
array[0:6]
array([[0.731878, 0.619976, 0.070233, 0.447082, 0.444923],
[0.552258, nan, nan, nan, nan],
[0.612811, nan, nan, nan, nan],
[0.445931, nan, nan, nan, nan],
[0.817505, nan, nan, nan, nan],
[0.818265, nan, nan, nan, nan]])
The next step is to choose the locations where the random sources change. If the number of rows is \(n\), the number of changes in the first column is \(n\), the number in the second column is \(n/2\) on average, the number in the third column is \(n/4\) on average, etc.
So the total number of changes in the matrix is \(2n\) on average; since \(n\) of those are in the first column, the other \(n\) are in the rest of the matrix.
To place the remaining \(n\) changes, we generate random columns from a geometric distribution with \(p=0.5\). If we generate a value out of bounds, we set it to 0 (so the first column gets the extras).
p = 0.5
n = nrows
cols = np.random.geometric(p, n)
cols[cols >= ncols] = 0
cols
array([1, 0, 3, 2, 2, 2, 1, 2, 3, 1, 2, 1, 1, 1, 1, 3, 1, 4, 1, 2, 4, 1,
1, 1, 3, 2, 1, 1, 2, 2, 2, 2, 1, 2, 2, 1, 2, 1, 1, 3, 1, 1, 3, 1,
1, 1, 1, 2, 0, 0, 3, 2, 1, 1, 2, 0, 2, 1, 1, 3, 1, 1, 4, 1, 4, 3,
0, 1, 1, 2, 1, 1, 2, 4, 1, 0, 1, 1, 1, 1, 2, 2, 2, 3, 2, 1, 0, 2,
4, 1, 4, 1, 1, 1, 2, 3, 2, 3, 3, 1])
Within each column, we choose a random row from a uniform distribution. Ideally we would choose without replacement, but it is faster and easier to choose with replacement, and I doubt it matters.
rows = np.random.randint(nrows, size=n)
rows
array([99, 10, 20, 89, 58, 17, 86, 24, 85, 77, 84, 64, 16, 75, 90, 97, 72,
3, 85, 74, 37, 0, 72, 31, 19, 84, 77, 72, 88, 21, 61, 80, 90, 65,
34, 4, 53, 3, 35, 86, 93, 58, 54, 93, 4, 45, 42, 60, 31, 32, 5,
29, 20, 53, 12, 43, 66, 0, 95, 17, 78, 55, 43, 55, 88, 25, 18, 87,
1, 78, 86, 63, 9, 51, 37, 60, 94, 12, 46, 54, 3, 61, 55, 38, 28,
57, 19, 14, 11, 47, 16, 88, 39, 61, 40, 64, 35, 11, 98, 73])
Now we can put random values at rach of the change points.
array[rows, cols] = np.random.random(n)
array[0:6]
array([[0.731878, 0.267177, 0.070233, 0.447082, 0.444923],
[0.552258, 0.090448, nan, nan, nan],
[0.612811, nan, nan, nan, nan],
[0.445931, 0.80424 , 0.298983, nan, 0.663056],
[0.817505, 0.449897, nan, nan, nan],
[0.818265, nan, nan, 0.079613, nan]])
Next we want to do a zero-order hold to fill in the NaNs. NumPy doesn’t do that, but Pandas does. So I’ll create a DataFrame:
import pandas as pd
df = pd.DataFrame(array)
df.head()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.731878 | 0.267177 | 0.070233 | 0.447082 | 0.444923 |
| 1 | 0.552258 | 0.090448 | NaN | NaN | NaN |
| 2 | 0.612811 | NaN | NaN | NaN | NaN |
| 3 | 0.445931 | 0.804240 | 0.298983 | NaN | 0.663056 |
| 4 | 0.817505 | 0.449897 | NaN | NaN | NaN |
And then use fillna along the columns.
filled = df.ffill(axis=0)
filled.head()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.731878 | 0.267177 | 0.070233 | 0.447082 | 0.444923 |
| 1 | 0.552258 | 0.090448 | 0.070233 | 0.447082 | 0.444923 |
| 2 | 0.612811 | 0.090448 | 0.070233 | 0.447082 | 0.444923 |
| 3 | 0.445931 | 0.804240 | 0.298983 | 0.447082 | 0.663056 |
| 4 | 0.817505 | 0.449897 | 0.298983 | 0.447082 | 0.663056 |
Finally we add up the rows.
total = filled.sum(axis=1)
total.head()
0 1.961293
1 1.604944
2 1.665497
3 2.659291
4 2.676523
dtype: float64
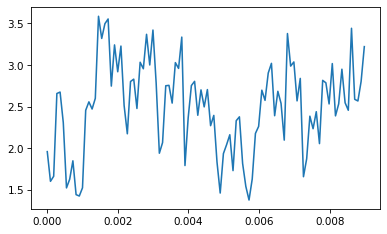
If we put the results into a Wave, here’s what it looks like:
from thinkdsp import Wave
wave = Wave(total)
wave.plot()
Here’s the whole process in a function:
def voss(nrows, ncols=16):
"""Generates pink noise using the Voss-McCartney algorithm.
nrows: number of values to generate
rcols: number of random sources to add
returns: NumPy array
"""
array = np.full((nrows, ncols), np.nan)
array[0, :] = np.random.random(ncols)
array[:, 0] = np.random.random(nrows)
# the total number of changes is nrows
n = nrows
cols = np.random.geometric(0.5, n)
cols[cols >= ncols] = 0
rows = np.random.randint(nrows, size=n)
array[rows, cols] = np.random.random(n)
df = pd.DataFrame(array)
df.ffill(axis=0, inplace=True)
total = df.sum(axis=1)
return total.values
To test it I’ll generate 11025 values:
ys = voss(11025)
ys
array([7.649219, 7.629732, 7.32242 , ..., 9.444684, 9.730514, 9.647188])
And make them into a Wave:
wave = Wave(ys)
wave.unbias()
wave.normalize()
Here’s what it looks like:
wave.plot()
decorate(xlabel='Time')
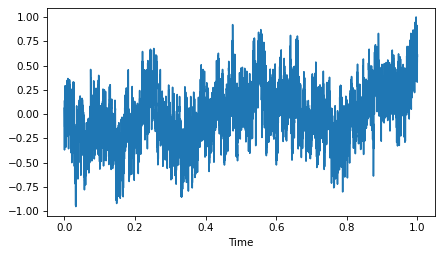
As expected, it is more random-walk-like than white noise, but more random looking than red noise.
Here’s what it sounds like:
wave.make_audio()
And here’s the power spectrum:
spectrum = wave.make_spectrum()
spectrum.hs[0] = 0
spectrum.plot_power()
decorate(xlabel='Frequency (Hz)',
xscale='log',
yscale='log')
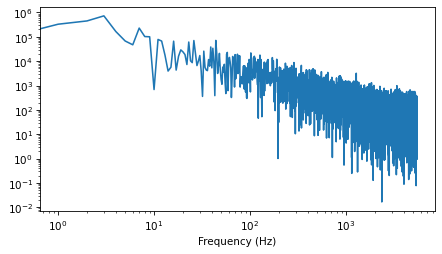
The estimated slope is close to -1.
spectrum.estimate_slope().slope
-1.0241990494162052
We can get a better sense of the average power spectrum by generating a longer sample:
seg_length = 64 * 1024
iters = 100
wave = Wave(voss(seg_length * iters))
len(wave)
6553600
And using Barlett’s method to compute the average.
from thinkdsp import Spectrum
def bartlett_method(wave, seg_length=512, win_flag=True):
"""Estimates the power spectrum of a noise wave.
wave: Wave
seg_length: segment length
"""
# make a spectrogram and extract the spectrums
spectro = wave.make_spectrogram(seg_length, win_flag)
spectrums = spectro.spec_map.values()
# extract the power array from each spectrum
psds = [spectrum.power for spectrum in spectrums]
# compute the root mean power (which is like an amplitude)
hs = np.sqrt(sum(psds) / len(psds))
fs = next(iter(spectrums)).fs
# make a Spectrum with the mean amplitudes
spectrum = Spectrum(hs, fs, wave.framerate)
return spectrum
spectrum = bartlett_method(wave, seg_length=seg_length, win_flag=False)
spectrum.hs[0] = 0
len(spectrum)
32769
It’s pretty close to a straight line, with some curvature at the highest frequencies.
spectrum.plot_power()
decorate(xlabel='Frequency (Hz)',
xscale='log',
yscale='log')
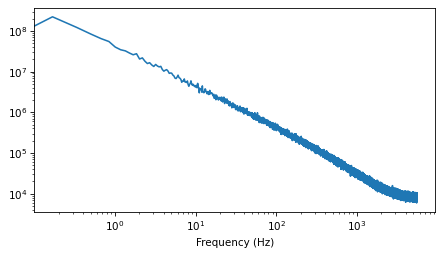
And the slope is close to -1.
spectrum.estimate_slope().slope
-1.0022780778827378
Think DSP: Digital Signal Processing in Python, 2nd Edition
Copyright 2024 Allen B. Downey
License: Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International