Printed copies of Elements of Data Science are available now, with a full color interior, from Lulu.com.
10. Regression#
Click here to run this notebook on Colab.
In the previous chapter we used simple linear regression to quantify the relationship between two variables. In this chapter we’ll get farther into regression, including multiple regression and one of my all-time favorite tools, logistic regression. These tools will allow us to explore relationships among sets of variables. As an example, we will use data from the General Social Survey (GSS) to explore the relationship between education, sex, age, and income.
The GSS dataset contains hundreds of columns. We’ll work with an extract that contains just the columns we need, as we did in Chapter 8. Instructions for downloading the extract are in the notebook for this chapter.
We can read the DataFrame like this and display the first few rows.
import pandas as pd
gss = pd.read_hdf('gss_extract_2022.hdf', 'gss')
gss.head()
| year | id | age | educ | degree | sex | gunlaw | grass | realinc | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1972 | 1 | 23.0 | 16.0 | 3.0 | 2.0 | 1.0 | NaN | 18951.0 |
| 1 | 1972 | 2 | 70.0 | 10.0 | 0.0 | 1.0 | 1.0 | NaN | 24366.0 |
| 2 | 1972 | 3 | 48.0 | 12.0 | 1.0 | 2.0 | 1.0 | NaN | 24366.0 |
| 3 | 1972 | 4 | 27.0 | 17.0 | 3.0 | 2.0 | 1.0 | NaN | 30458.0 |
| 4 | 1972 | 5 | 61.0 | 12.0 | 1.0 | 2.0 | 1.0 | NaN | 50763.0 |
We’ll start with a simple regression, estimating the parameters of real income as a function of years of education. First we’ll select the subset of the data where both variables are valid.
data = gss.dropna(subset=['realinc', 'educ'])
xs = data['educ']
ys = data['realinc']
Now we can use linregress to fit a line to the data.
from scipy.stats import linregress
res = linregress(xs, ys)
res._asdict()
{'slope': 3631.0761003894995,
'intercept': -15007.453640508655,
'rvalue': 0.37169252259280877,
'pvalue': 0.0,
'stderr': 35.625290800764,
'intercept_stderr': 480.07467595184363}
The estimated slope is about 3450, which means that each additional year of education is associated with an additional $3450 of income.
10.1. Regression with StatsModels#
SciPy doesn’t do multiple regression, so we’ll switch to a new library, StatsModels. Here’s the import statement.
import statsmodels.formula.api as smf
To fit a regression model, we’ll use ols, which stands for “ordinary least squares”, another name for regression.
results = smf.ols('realinc ~ educ', data=data).fit()
The first argument is a formula string that specifies that we want to regress income as a function of education.
The second argument is the DataFrame containing the subset of valid data.
The names in the formula string correspond to columns in the DataFrame.
The result from ols is an object that represents the model – it provides a function called fit that does the actual computation.
The result is a RegressionResultsWrapper, which contains a Series called params, which contains the estimated intercept and the slope associated with educ.
results.params
Intercept -15007.453641
educ 3631.076100
dtype: float64
The results from Statsmodels are the same as the results we got from SciPy, so that’s good!
Exercise: Let’s run another regression using SciPy and StatsModels, and confirm we get the same results.
Compute the regression of realinc as a function of age using SciPy’s linregress and then using StatsModels’ ols.
Confirm that the intercept and slope are the same.
Remember to use dropna to select the rows with valid data in both columns.
10.2. Multiple Regression#
In the previous section, we saw that income depends on education, and in the exercise we saw that it also depends on age.
Now let’s put them together in a single model.
results = smf.ols('realinc ~ educ + age', data=gss).fit()
results.params
Intercept -17999.726908
educ 3665.108238
age 55.071802
dtype: float64
In this model, realinc is the variable we are trying to explain or predict, which is called the dependent variable because it depends on the the other variables – or at least we expect it to.
The other variables, educ and age, are called independent variables or sometimes “predictors”.
The + sign indicates that we expect the contributions of the independent variables to be additive.
The result contains an intercept and two slopes, which estimate the average contribution of each predictor with the other predictor held constant.
The estimated slope for
educis about 3665 – so if we compare two people with the same age, and one has an additional year of education, we expect their income to be higher by $3514.The estimated slope for
ageis about 55 – so if we compare two people with the same education, and one is a year older, we expect their income to be higher by $55.
In this model, the contribution of age is quite small, but as we’ll see in the next section that might be misleading.
10.3. Grouping by Age#
Let’s look more closely at the relationship between income and age.
We’ll use a Pandas method we have not seen before, called groupby, to divide the DataFrame into age groups.
grouped = gss.groupby('age')
type(grouped)
pandas.core.groupby.generic.DataFrameGroupBy
The result is a GroupBy object that contains one group for each value of age.
The GroupBy object behaves like a DataFrame in many ways.
You can use brackets to select a column, like realinc in this example, and then invoke a method like mean.
mean_income_by_age = grouped['realinc'].mean()
The result is a Pandas Series that contains the mean income for each age group, which we can plot like this.
import matplotlib.pyplot as plt
plt.plot(mean_income_by_age, 'o', alpha=0.5)
plt.xlabel('Age (years)')
plt.ylabel('Income (1986 $)')
plt.title('Average income, grouped by age');
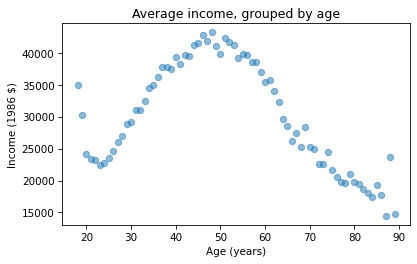
Average income increases from age 20 to age 50, then starts to fall.
And that explains why the estimated slope is so small, because the relationship is non-linear.
To describe a non-linear relationship, we’ll create a new variable called age2 that equals age squared – so it is called a quadratic term.
gss['age2'] = gss['age']**2
Now we can run a regression with both age and age2 on the right side.
model = smf.ols('realinc ~ educ + age + age2', data=gss)
results = model.fit()
results.params
Intercept -52599.674844
educ 3464.870685
age 1779.196367
age2 -17.445272
dtype: float64
In this model, the slope associated with age is substantial, about $1779 per year.
The slope associated with age2 is about -$17.
It might be unexpected that it is negative – we’ll see why in the next section.
But first, here are two exercises where you can practice using groupby and ols.
Exercise: Let’s explore the relationship between income and education.
First, group gss by educ.
From the resulting GroupBy object, extract realinc and compute the mean.
Then plot mean income in each education group.
What can you say about the relationship between these variables?
Does it look like a linear relationship?
Exercise: The graph in the previous exercise suggests that the relationship between income and education is non-linear. So let’s try fitting a non-linear model.
Add a column named
educ2to thegssDataFrame – it should contain the values fromeducsquared.Run a regression that uses
educ,educ2,age, andage2to predictrealinc.
10.4. Visualizing regression results#
In the previous section we ran a multiple regression model to characterize the relationships between income, age, and education.
Because the model includes quadratic terms, the parameters are hard to interpret.
For example, you might notice that the parameter for educ is negative, and that might be a surprise, because it suggests that higher education is associated with lower income.
But the parameter for educ2 is positive, and that makes a big difference.
In this section we’ll see a way to interpret the model visually and validate it against data.
Here’s the model from the previous exercise.
gss['educ2'] = gss['educ']**2
model = smf.ols('realinc ~ educ + educ2 + age + age2', data=gss)
results = model.fit()
results.params
Intercept -26336.766346
educ -706.074107
educ2 165.962552
age 1728.454811
age2 -17.207513
dtype: float64
The results object provides a method called predict that uses the estimated parameters to generate predictions.
It takes a DataFrame as a parameter and returns a Series with a prediction for each row in the DataFrame.
To use it, we’ll create a new DataFrame with age running from 18 to 89, and age2 set to age squared.
import numpy as np
df = pd.DataFrame()
df['age'] = np.linspace(18, 89)
df['age2'] = df['age']**2
Next, we’ll pick a level for educ, like 12 years, which is the most common value.
When you assign a single value to a column in a DataFrame, Pandas makes a copy for each row.
df['educ'] = 12
df['educ2'] = df['educ']**2
Then we can use results to predict the average income for each age group, holding education constant.
pred12 = results.predict(df)
The result from predict is a Series with one prediction for each row.
So we can plot it with age on the x-axis and the predicted income for each age group on the y-axis.
And we’ll plot the data for comparison.
plt.plot(mean_income_by_age, 'o', alpha=0.5)
plt.plot(df['age'], pred12, label='High school', color='C4')
plt.xlabel('Age (years)')
plt.ylabel('Income (1986 $)')
plt.title('Income versus age, grouped by education level')
plt.legend();
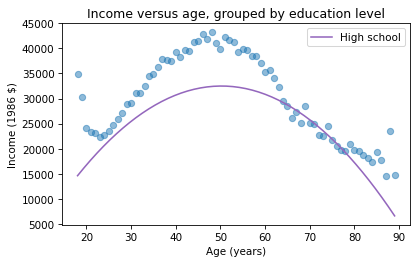
The dots show the average income in each age group. The line shows the predictions generated by the model, holding education constant. This plot shows the shape of the model, a downward-facing parabola.
We can do the same thing with other levels of education, like 14 years, which is the nominal time to earn an Associate’s degree, and 16 years, which is the nominal time to earn a Bachelor’s degree.
df['educ'] = 16
df['educ2'] = df['educ']**2
pred16 = results.predict(df)
df['educ'] = 14
df['educ2'] = df['educ']**2
pred14 = results.predict(df)
plt.plot(mean_income_by_age, 'o', alpha=0.5)
plt.plot(df['age'], pred16, ':', label='Bachelor')
plt.plot(df['age'], pred14, '--', label='Associate')
plt.plot(df['age'], pred12, label='High school', color='C4')
plt.xlabel('Age (years)')
plt.ylabel('Income (1986 $)')
plt.title('Income versus age, grouped by education level')
plt.legend();
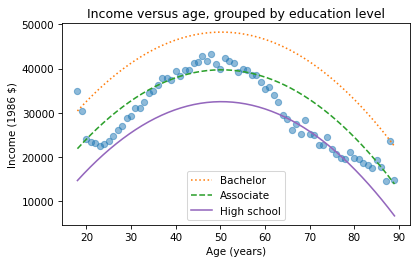
The lines show expected income as a function of age for three levels of education. This visualization helps validate the model, since we can compare the predictions with the data. And it helps us interpret the model since we can see the separate contributions of age and education.
Sometimes we can understand a model by looking at its parameters, but often it is better to look at its predictions. In the exercises, you’ll have a chance to run a multiple regression, generate predictions, and visualize the results.
Exercise: At this point, we have a model that predicts income using age and education, and we’ve plotted predictions for different age groups, holding education constant. Now let’s see what it predicts for different levels of education, holding age constant.
Create an empty
DataFramenameddf.Using
np.linspace(), add a column namedeductodfwith a range of values from0to20.Add a column named
educ2with the values fromeducsquared.Add a column named
agewith the constant value30.Add a column named
age2with the values fromagesquared.Use the
resultsobject anddfto generate expected income as a function of education.
Exercise: Now let’s visualize the results from the previous exercise.
Group the GSS data by
educand compute the mean income in each education group.Plot mean income for each education group as a scatter plot.
Plot the predictions from the previous exercise.
How do the predictions compare with the data?
10.5. Categorical Variables#
Most of the variables we have used so far – like income, age, and education – are numerical. But variables like sex and race are categorical – that is, each respondent belongs to one of a specified set of categories. If there are only two categories, the variable is binary.
With StatsModels, it is easy to include a categorical variable as part of a regression model. Here’s an example:
formula = 'realinc ~ educ + educ2 + age + age2 + C(sex)'
results = smf.ols(formula, data=gss).fit()
results.params
Intercept -24635.767539
C(sex)[T.2.0] -4891.439306
educ -496.623120
educ2 156.898221
age 1720.274097
age2 -17.097853
dtype: float64
In the formula string, the letter C indicates that sex is a categorical variable.
The regression treats the value sex=1, which is male, as the reference group, and reports the difference associated with the value sex=2, which is female.
So the results indicate that income for women is about $4156 less than for men, after controlling for age and education.
However, note that realinc represents household income.
If the respondent is married, it includes both their own income and their spouse’s.
So we cannot interpret this result as an estimate of a gender gap in income.
10.6. Logistic Regression#
In the previous section, we added a categorical variable on the right side of a regression formula – that is, we used it as a predictive variable.
But what if the categorical variable is on the left side of the regression formula – that is, it’s the value we are trying to predict? In that case, we can use logistic regression.
As an example, one of the GSS questions asks “Would you favor or oppose a law which would require a person to obtain a police permit before he or she could buy a gun?”
The responses are in a column called gunlaw – here are the values.
gss['gunlaw'].value_counts()
gunlaw
1.0 36367
2.0 11940
Name: count, dtype: int64
1 means yes and 2 means no, so most respondents are in favor.
Before we can use this variable in a logistic regression, we have to recode it so 1 means “yes” and 0 means “no”.
We can do that by replacing 2 with 0.
gss['gunlaw'] = gss['gunlaw'].replace([2], [0])
To run logistic regression, we’ll use logit, which is named for the logit function, which is related to logistic regression.
formula = 'gunlaw ~ age + age2 + educ + educ2 + C(sex)'
results = smf.logit(formula, data=gss).fit()
Optimization terminated successfully.
Current function value: 0.544026
Iterations 5
Estimating the parameters for the logistic model is an iterative process, so the output contains information about the number of iterations. Other than that, everything is the same as what we have seen before. Here are the estimated parameters.
results.params
Intercept 1.483746
C(sex)[T.2.0] 0.740717
age -0.021274
age2 0.000216
educ -0.098093
educ2 0.005557
dtype: float64
The parameters are in the form of log odds – I won’t explain them in detail here, except to say that positive values make the outcome more likely and negative values make the outcome less likely.
For example, the parameter associated with sex=2 is 0.74, which indicates that women are more likely to support this form of gun control.
To see how much more likely, we can generate predictions, as we did with linear regression.
As an example, we’ll generate predictions for different ages and sexes, with education held constant.
First we need a DataFrame with a range of values for age and a fixed value of educ.
df = pd.DataFrame()
df['age'] = np.linspace(18, 89)
df['educ'] = 12
Then we can compute age2 and educ2.
df['age2'] = df['age']**2
df['educ2'] = df['educ']**2
We can generate predictions for men like this.
df['sex'] = 1
pred_male = results.predict(df)
And for women like this.
df['sex'] = 2
pred_female = results.predict(df)
Now, to visualize the results, we’ll start by plotting the data. As we’ve done before, we’ll divide the respondents into age groups and compute the mean in each group. The mean of a binary variable is the fraction of people in favor. Then we can plot the predictions.
grouped = gss.groupby('age')
favor_by_age = grouped['gunlaw'].mean()
plt.plot(favor_by_age, 'o', alpha=0.5)
plt.plot(df['age'], pred_female, label='Female')
plt.plot(df['age'], pred_male, '--', label='Male')
plt.xlabel('Age')
plt.ylabel('Probability of favoring gun law')
plt.title('Support for gun law versus age, grouped by sex')
plt.legend();
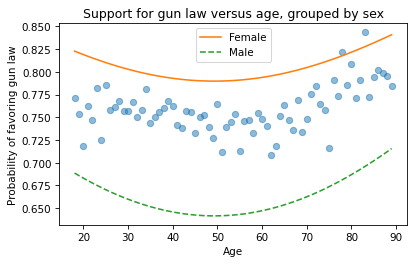
According to the model, people near age 50 are least likely to support gun control (at least as this question was posed). And women are more likely to support it than men, by about 15 percentage points.
Logistic regression is a powerful tool for exploring relationships between a binary variable and the factors that predict it. In the exercises, you’ll explore the factors that predict support for legalizing marijuana.
Exercise: In the GSS dataset, the variable grass records responses to the question “Do you think the use of marijuana should be made legal or not?”
Let’s use logistic regression to explore relationships between this variable and age, sex, and education level.
First, use
replaceto recode thegrasscolumn so that1means yes and0means no. Usevalue_countsto check.Next, use the StatsModels function
logitto predictgrassusing the variablesage,age2,educ, andeduc2, along withsexas a categorical variable. Display the parameters. Are men or women more likely to support legalization?To generate predictions, start with an empty DataFrame. Add a column called
agethat contains a sequence of values from 18 to 89. Add a column callededucand set it to 12 years. Then compute a column,age2, which is the square ofage, and a column,educ2, which is the square ofeduc.Use
predictto generate predictions for men (sex=1) and women (sex=2).Generate a plot that shows (a) the average level of support for legalizing marijuana in each age group, (b) the level of support the model predicts for men as a function of age, and (c) the level of support predicted for women as a function of age.
10.7. Summary#
At this point, I’d like to summarize the topics we’ve covered so far, and make some connections that might clarify the big picture. A central theme of this book is exploratory data analysis, which is a process and set of tools for exploring a dataset, visualizing distributions, and discovering relationships between variables. The last four chapters demonstrate the steps of this process:
Chapter 7 is about importing and cleaning data, and checking for errors and other special conditions. This might not be the most exciting part of the process, but time spent understanding data can save you from embarrassing errors.
Chapter 8 is about exploring variables one at a time, visualizing distributions using PMFs, CDFs, and KDE, and choosing appropriate summary statistics.
In Chapter 9 we explored relationships between variables two at a time, using scatter plots and other visualizations; and we quantified those relationships using correlation and simple regression.
Finally, in this chapter, we explored multivariate relationships using multiple regression and logistic regression.
We moved through a lot of material quickly, but if you practice and apply these methods to other questions and datasets, you will learn more as you go. In the next chapter, we will move on to a new topic, resampling, which is a versatile tool for statistical inference.