You can order print and ebook versions of Think Bayes 2e from Bookshop.org and Amazon.
3. Distributions#
In the previous chapter we used Bayes’s Theorem to solve a cookie problem; then we solved it again using a Bayes table.
In this chapter, at the risk of testing your patience, we will solve it one more time using a Pmf object, which represents a “probability mass function”.
I’ll explain what that means, and why it is useful for Bayesian statistics.
We’ll use Pmf objects to solve some more challenging problems and take one more step toward Bayesian statistics.
But we’ll start with distributions.
3.1. Distributions#
In statistics a distribution is a set of possible outcomes and their corresponding probabilities. For example, if you toss a coin, there are two possible outcomes with approximately equal probability. If you roll a six-sided die, the set of possible outcomes is the numbers 1 to 6, and the probability associated with each outcome is 1/6.
To represent distributions, we’ll use a library called empiricaldist.
An “empirical” distribution is based on data, as opposed to a
theoretical distribution.
We’ll use this library throughout the book. I’ll introduce the basic features in this chapter and we’ll see additional features later.
3.2. Probability Mass Functions#
If the outcomes in a distribution are discrete, we can describe the distribution with a probability mass function, or PMF, which is a function that maps from each possible outcome to its probability.
empiricaldist provides a class called Pmf that represents a
probability mass function.
To use Pmf you can import it like this:
from empiricaldist import Pmf
The following example makes a Pmf that represents the outcome of a
coin toss.
coin = Pmf()
coin['heads'] = 1/2
coin['tails'] = 1/2
coin
| probs | |
|---|---|
| heads | 0.5 |
| tails | 0.5 |
Pmf creates an empty Pmf with no outcomes.
Then we can add new outcomes using the bracket operator.
In this example, the two outcomes are represented with strings, and they have the same probability, 0.5.
You can also make a Pmf from a sequence of possible outcomes.
The following example uses Pmf.from_seq to make a Pmf that represents a six-sided die.
die = Pmf.from_seq([1,2,3,4,5,6])
die
| probs | |
|---|---|
| 1 | 0.166667 |
| 2 | 0.166667 |
| 3 | 0.166667 |
| 4 | 0.166667 |
| 5 | 0.166667 |
| 6 | 0.166667 |
In this example, all outcomes in the sequence appear once, so they all have the same probability, \(1/6\).
More generally, outcomes can appear more than once, as in the following example:
letters = Pmf.from_seq(list('Mississippi'))
letters
| probs | |
|---|---|
| M | 0.090909 |
| i | 0.363636 |
| p | 0.181818 |
| s | 0.363636 |
The letter M appears once out of 11 characters, so its probability is \(1/11\).
The letter i appears 4 times, so its probability is \(4/11\).
Since the letters in a string are not outcomes of a random process, I’ll use the more general term “quantities” for the letters in the Pmf.
The Pmf class inherits from a Pandas Series, so anything you can do with a Series, you can also do with a Pmf.
For example, you can use the bracket operator to look up a quantity and get the corresponding probability.
letters['s']
0.36363636363636365
In the word “Mississippi”, about 36% of the letters are “s”.
However, if you ask for the probability of a quantity that’s not in the distribution, you get a KeyError.
You can also call a Pmf as if it were a function, with a letter in parentheses.
letters('s')
0.36363636363636365
If the quantity is in the distribution the results are the same.
But if it is not in the distribution, the result is 0, not an error.
letters('t')
0
With parentheses, you can also provide a sequence of quantities and get a sequence of probabilities.
die([1,4,7])
array([0.16666667, 0.16666667, 0. ])
The quantities in a Pmf can be strings, numbers, or any other type that can be stored in the index of a Pandas Series.
If you are familiar with Pandas, that will help you work with Pmf objects.
But I will explain what you need to know as we go along.
3.4. 101 Bowls#
Next let’s solve a cookie problem with 101 bowls:
Bowl 0 contains 0% vanilla cookies,
Bowl 1 contains 1% vanilla cookies,
Bowl 2 contains 2% vanilla cookies,
and so on, up to
Bowl 99 contains 99% vanilla cookies, and
Bowl 100 contains all vanilla cookies.
As in the previous version, there are only two kinds of cookies, vanilla and chocolate. So Bowl 0 is all chocolate cookies, Bowl 1 is 99% chocolate, and so on.
Suppose we choose a bowl at random, choose a cookie at random, and it turns out to be vanilla. What is the probability that the cookie came from Bowl \(x\), for each value of \(x\)?
To solve this problem, I’ll use np.arange to make an array that represents 101 hypotheses, numbered from 0 to 100.
import numpy as np
hypos = np.arange(101)
We can use this array to make the prior distribution:
prior = Pmf(1, hypos)
prior.normalize()
101
As this example shows, we can initialize a Pmf with two parameters.
The first parameter is the prior probability; the second parameter is a sequence of quantities.
In this example, the probabilities are all the same, so we only have to provide one of them; it gets “broadcast” across the hypotheses. Since all hypotheses have the same prior probability, this distribution is uniform.
Here are the first few hypotheses and their probabilities.
prior.head()
| probs | |
|---|---|
| 0 | 0.009901 |
| 1 | 0.009901 |
| 2 | 0.009901 |
The likelihood of the data is the fraction of vanilla cookies in each bowl, which we can calculate using hypos:
likelihood_vanilla = hypos/100
likelihood_vanilla[:5]
array([0. , 0.01, 0.02, 0.03, 0.04])
Now we can compute the posterior distribution in the usual way:
posterior1 = prior * likelihood_vanilla
posterior1.normalize()
posterior1.head()
| probs | |
|---|---|
| 0 | 0.000000 |
| 1 | 0.000198 |
| 2 | 0.000396 |
The following figure shows the prior distribution and the posterior distribution after one vanilla cookie.
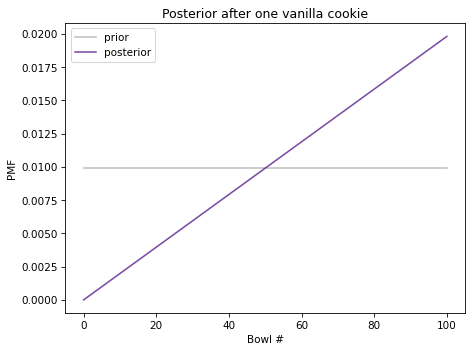
The posterior probability of Bowl 0 is 0 because it contains no vanilla cookies. The posterior probability of Bowl 100 is the highest because it contains the most vanilla cookies. In between, the shape of the posterior distribution is a line because the likelihoods are proportional to the bowl numbers.
Now suppose we put the cookie back, draw again from the same bowl, and get another vanilla cookie. Here’s the update after the second cookie:
posterior2 = posterior1 * likelihood_vanilla
posterior2.normalize()
And here’s what the posterior distribution looks like.
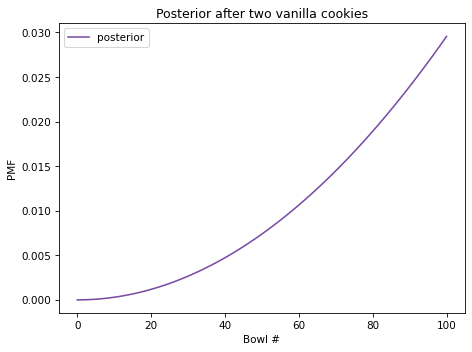
After two vanilla cookies, the high-numbered bowls have the highest posterior probabilities because they contain the most vanilla cookies; the low-numbered bowls have the lowest probabilities.
But suppose we draw again and get a chocolate cookie. Here’s the update:
likelihood_chocolate = 1 - hypos/100
posterior3 = posterior2 * likelihood_chocolate
posterior3.normalize()
And here’s the posterior distribution.
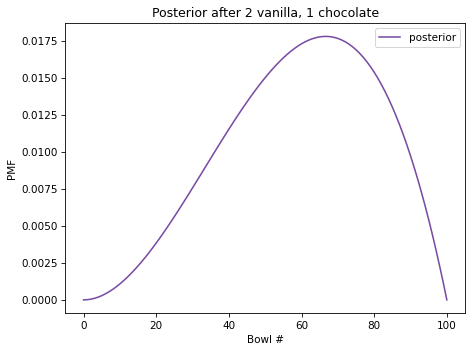
Now Bowl 100 has been eliminated because it contains no chocolate cookies. But the high-numbered bowls are still more likely than the low-numbered bowls, because we have seen more vanilla cookies than chocolate.
In fact, the peak of the posterior distribution is at Bowl 67, which corresponds to the fraction of vanilla cookies in the data we’ve observed, \(2/3\).
The quantity with the highest posterior probability is called the MAP, which stands for “maximum a posteriori probability”, where “a posteriori” is unnecessary Latin for “posterior”.
To compute the MAP, we can use the Series method idxmax:
posterior3.idxmax()
67
Or Pmf provides a more memorable name for the same thing:
posterior3.max_prob()
67
As you might suspect, this example isn’t really about bowls; it’s about estimating proportions. Imagine that you have one bowl of cookies. You don’t know what fraction of cookies are vanilla, but you think it is equally likely to be any fraction from 0 to 1. If you draw three cookies and two are vanilla, what proportion of cookies in the bowl do you think are vanilla? The posterior distribution we just computed is the answer to that question.
We’ll come back to estimating proportions in the next chapter.
But first let’s use a Pmf to solve the dice problem.
3.5. The Dice Problem#
In the previous chapter we solved the dice problem using a Bayes table. Here’s the statement of the problem:
Suppose I have a box with a 6-sided die, an 8-sided die, and a 12-sided die. I choose one of the dice at random, roll it, and report that the outcome is a 1. What is the probability that I chose the 6-sided die?
Let’s solve it using a Pmf.
I’ll use integers to represent the hypotheses:
hypos = [6, 8, 12]
We can make the prior distribution like this:
prior = Pmf(1/3, hypos)
prior
| probs | |
|---|---|
| 6 | 0.333333 |
| 8 | 0.333333 |
| 12 | 0.333333 |
As in the previous example, the prior probability gets broadcast across the hypotheses.
The Pmf object has two attributes:
qscontains the quantities in the distribution;pscontains the corresponding probabilities.
prior.qs
array([ 6, 8, 12])
prior.ps
array([0.33333333, 0.33333333, 0.33333333])
Now we’re ready to do the update. Here’s the likelihood of the data for each hypothesis.
likelihood1 = 1/6, 1/8, 1/12
And here’s the update.
posterior = prior * likelihood1
posterior.normalize()
posterior
| probs | |
|---|---|
| 6 | 0.444444 |
| 8 | 0.333333 |
| 12 | 0.222222 |
The posterior probability for the 6-sided die is \(4/9\).
Now suppose I roll the same die again and get a 7. Here are the likelihoods:
likelihood2 = 0, 1/8, 1/12
The likelihood for the 6-sided die is 0 because it is not possible to get a 7 on a 6-sided die. The other two likelihoods are the same as in the previous update.
Here’s the update:
posterior *= likelihood2
posterior.normalize()
posterior
| probs | |
|---|---|
| 6 | 0.000000 |
| 8 | 0.692308 |
| 12 | 0.307692 |
After rolling a 1 and a 7, the posterior probability of the 8-sided die is about 69%.
3.6. Updating Dice#
The following function is a more general version of the update in the previous section:
def update_dice(pmf, data):
"""Update pmf based on new data."""
hypos = pmf.qs
likelihood = 1 / hypos
impossible = (data > hypos)
likelihood[impossible] = 0
pmf *= likelihood
pmf.normalize()
The first parameter is a Pmf that represents the possible dice and their probabilities.
The second parameter is the outcome of rolling a die.
The first line selects quantities from the Pmf which represent the hypotheses.
Since the hypotheses are integers, we can use them to compute the likelihoods.
In general, if there are n sides on the die, the probability of any possible outcome is 1/n.
However, we have to check for impossible outcomes! If the outcome exceeds the hypothetical number of sides on the die, the probability of that outcome is 0.
impossible is a Boolean Series that is True for each impossible outcome.
I use it as an index into likelihood to set the corresponding probabilities to 0.
Finally, I multiply pmf by the likelihoods and normalize.
Here’s how we can use this function to compute the updates in the previous section. I start with a fresh copy of the prior distribution:
pmf = prior.copy()
pmf
| probs | |
|---|---|
| 6 | 0.333333 |
| 8 | 0.333333 |
| 12 | 0.333333 |
And use update_dice to do the updates.
update_dice(pmf, 1)
update_dice(pmf, 7)
pmf
| probs | |
|---|---|
| 6 | 0.000000 |
| 8 | 0.692308 |
| 12 | 0.307692 |
The result is the same. We will see a version of this function in the next chapter.
3.7. Summary#
This chapter introduces the empiricaldist module, which provides Pmf, which we use to represent a set of hypotheses and their probabilities.
empiricaldist is based on Pandas; the Pmf class inherits from the Pandas Series class and provides additional features specific to probability mass functions.
We’ll use Pmf and other classes from empiricaldist throughout the book because they simplify the code and make it more readable.
But we could do the same things directly with Pandas.
We use a Pmf to solve the cookie problem and the dice problem, which we saw in the previous chapter.
With a Pmf it is easy to perform sequential updates with multiple pieces of data.
We also solved a more general version of the cookie problem, with 101 bowls rather than two. Then we computed the MAP, which is the quantity with the highest posterior probability.
In the next chapter, I’ll introduce the Euro problem, and we will use the binomial distribution. And, at last, we will make the leap from using Bayes’s Theorem to doing Bayesian statistics.
But first you might want to work on the exercises.
3.8. Exercises#
Exercise: Suppose I have a box with a 6-sided die, an 8-sided die, and a 12-sided die. I choose one of the dice at random, roll it four times, and get 1, 3, 5, and 7. What is the probability that I chose the 8-sided die?
You can use the update_dice function or do the update yourself.
Exercise: In the previous version of the dice problem, the prior probabilities are the same because the box contains one of each die. But suppose the box contains 1 die that is 4-sided, 2 dice that are 6-sided, 3 dice that are 8-sided, 4 dice that are 12-sided, and 5 dice that are 20-sided. I choose a die, roll it, and get a 7. What is the probability that I chose an 8-sided die?
Hint: To make the prior distribution, call Pmf with two parameters.
Exercise: Suppose I have two sock drawers. One contains equal numbers of black and white socks. The other contains equal numbers of red, green, and blue socks. Suppose I choose a drawer at random, choose two socks at random, and I tell you that I got a matching pair. What is the probability that the socks are white?
For simplicity, let’s assume that there are so many socks in both drawers that removing one sock makes a negligible change to the proportions.
Exercise: Here’s a problem from Bayesian Data Analysis:
Elvis Presley had a twin brother (who died at birth). What is the probability that Elvis was an identical twin?
Hint: In 1935, about 2/3 of twins were fraternal and 1/3 were identical.
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)