Distributions#
Click here to run this notebook on Colab.
from os.path import basename, exists
def download(url):
filename = basename(url)
if not exists(filename):
from urllib.request import urlretrieve
local, _ = urlretrieve(url, filename)
print("Downloaded " + str(local))
return filename
download('https://raw.githubusercontent.com/AllenDowney/ElementsOfDataScience/v1/utils.py')
import utils
In this chapter we’ll see three ways to describe a distribution:
A probability mass function (PMF), which represents a set of values and the number of times each one appears in a dataset.
A cumulative distribution function (CDF), which contains the same information as a PMF in a form that makes it easier to visualize, make comparisons, and perform some computations.
A kernel density estimate (KDE), which is like a smooth, continuous version of a histogram.
As examples, we’ll use data from the General Social Survey (GSS) to look at distributions of age and income, and to explore the relationship between income and education. But we’ll start with one of the most important ideas in statistics, the distribution.
Distributions#
A distribution is a set of values and their corresponding probabilities. For example, if you roll a six-sided die, there are six possible outcomes – the numbers 1 through 6 – and they all have the same probability, \(1/6\). We can represent this distribution of outcomes with a table, like this:
Outcome |
1 |
2 |
3 |
4 |
5 |
6 |
|---|---|---|---|---|---|---|
Probability |
1/6 |
1/6 |
1/6 |
1/6 |
1/6 |
1/6 |
More generally, a distribution can have any number of values, the values can be any type, and the probabilities do not have to be equal.
To represent distributions in Python, we’ll use a library called empiricaldist, which stands for “empirical distribution”, where “empirical” means it is based on data rather than a mathematical formula.
empiricaldist provides an object type called Pmf, which stands for “probability mass function”.
A Pmf object contains a set of possible outcomes and their probabilities.
For example, here’s a Pmf that represents the outcome of rolling a six-sided die:
from empiricaldist import Pmf
outcomes = [1,2,3,4,5,6]
die = Pmf(1/6, outcomes)
The first argument is the probability of the outcomes; the second argument is the list of outcomes. We can display the result like this.
die
| probs | |
|---|---|
| 1 | 0.166667 |
| 2 | 0.166667 |
| 3 | 0.166667 |
| 4 | 0.166667 |
| 5 | 0.166667 |
| 6 | 0.166667 |
A Pmf object is a specialized version of a Pandas Series, so it provides all of the methods of a Series, plus some additional methods we’ll see soon.
Distribution of Education#
To get started with this dataset, let’s look at the educ column, which records the number of years of education for each respondent.
We can select this column from the DataFrame like this:
educ = gss['educ']
To see what the distribution of the responses looks like, we can use the hist method to plot a histogram.
import matplotlib.pyplot as plt
educ.hist(grid=False)
plt.xlabel('Years of education')
plt.ylabel('Number of respondents')
plt.title('Histogram of education level');
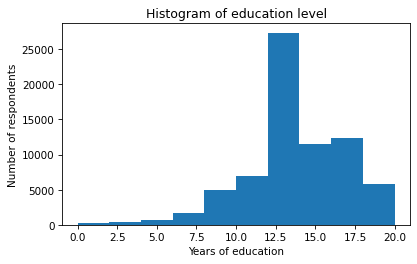
Based on the histogram, we can see the general shape of the distribution and the central tendency – it looks like the peak is near 12 years of education. But a histogram is not the best way to visualize this distribution because it obscures some important details.
An alternative is to use a Pmf object.
The function Pmf.from_seq takes any kind of sequence – like a list, tuple, or Pandas Series – and computes the distribution of the values.
pmf_educ = Pmf.from_seq(educ, normalize=False)
type(pmf_educ)
empiricaldist.empiricaldist.Pmf
With the keyword argument normalize=False, the result contains counts rather than probabilities.
Here are the first few values in educ and their counts.
pmf_educ.head()
| probs | |
|---|---|
| educ | |
| 0.0 | 177 |
| 1.0 | 49 |
| 2.0 | 158 |
In this dataset, there are 177 respondents who report that they have no formal education, and 49 who have only one year. Here are the last few values.
pmf_educ.tail()
| probs | |
|---|---|
| educ | |
| 18.0 | 2945 |
| 19.0 | 1112 |
| 20.0 | 1803 |
There are 1803 respondents who report that they have 20 or more years of formal education, which probably means they attended college and graduate school.
We can use the bracket operator to look up a value in pmf_educ and get the corresponding count.
pmf_educ[20]
1803
Often when we make a Pmf, we want to know the fraction of respondents with each value, rather than the counts.
We can do that by setting normalize=True.
Then we get a normalized Pmf, which means that the fractions add up to 1.
pmf_educ_norm = Pmf.from_seq(educ, normalize=True)
pmf_educ_norm.head()
| probs | |
|---|---|
| educ | |
| 0.0 | 0.002454 |
| 1.0 | 0.000679 |
| 2.0 | 0.002191 |
Now if we use the bracket operator to look up a value, the result is a fraction rather than a count.
pmf_educ_norm[20]
0.0249975737241255
The result indicates that about 2.5% of the respondents have 20 years of education. But we can also interpret this result as a probability – if we choose a random respondent, the probability is 2.5% that they have 20 years of education.
When a Pmf contains probabilities, we can say that it represents a proper probability mass function, or PMF.
With apologies for confusing notation, I’ll use Pmf to mean a kind of Python object, and PMF to mean the concept of a probability mass function.
Pmf provides a bar method that plots the values and their probabilities as a bar chart.
pmf_educ_norm.bar(label='educ')
plt.xlabel('Years of education')
plt.xticks(range(0, 21, 4))
plt.ylabel('PMF')
plt.title('Distribution of years of education')
plt.legend();
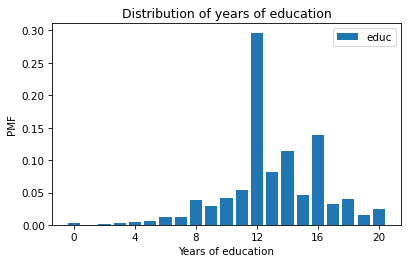
In this figure, we can see that the most common value is 12 years, but there are also peaks at 14 and 16, which correspond to two and four years of college.
For this data, plotting the Pmf is probably a better choice than the histogram.
The Pmf shows all unique values, so we can see where the peaks are.
Exercise: Let’s look at the year column in the DataFrame, which represents the year each respondent was interviewed.
Make an unnormalized Pmf for year and plot the result as a bar chart.
Use the bracket operator to look up the number of respondents interviewed in 2022.
Cumulative Distribution Functions#
If we compute the cumulative sum of a PMF, the result is a cumulative distribution function (CDF). To see what that means, and why it is useful, let’s look at a simple example. Suppose we have a sequence of five values.
values = 1, 2, 2, 3, 5
Here’s the Pmf of these values.
pmf = Pmf.from_seq(values)
pmf
| probs | |
|---|---|
| 1 | 0.2 |
| 2 | 0.4 |
| 3 | 0.2 |
| 5 | 0.2 |
If you draw a random value from values, the Pmf tells you the chance of getting x, for any value of x.
The probability of the value
1is0.2,The probability of the value
2is0.4, andThe probabilities for
3and5are0.2each.
The Pmf object has a method called make_cdf that computes the cumulative sum of the probabilities in the Pmf and returns a Cdf object.
cdf = pmf.make_cdf()
cdf
| probs | |
|---|---|
| 1 | 0.2 |
| 2 | 0.6 |
| 3 | 0.8 |
| 5 | 1.0 |
If you draw a random value from values, the Cdf tells you the chance of getting a value less than or equal to x, for any given x.
The
Cdfof1is0.2because one of the five values is less than or equal to 1,The
Cdfof2is0.6because three of the five values are less than or equal to2,The
Cdfof3is0.8because four of the five values are less than or equal to3,The
Cdfof5is1.0because all of the values are less than or equal to5.
If we make a Cdf from a proper Pmf, where the probabilities add up to 1, the result represents a proper CDF.
As with Pmf and PMF, I’ll use Cdf to refer to a Python object and CDF to refer to the concept.
CDF of Age#
To see why CDFs are useful, let’s consider the distribution of ages for respondents in the General Social Survey.
The column we’ll use is age.
Documentation of age is at https://gssdataexplorer.norc.org/variables/53/vshow.
According to the codebook, the range of the values is from 18 to 89, where 89 means “89 or older”.
The special codes 98 and 99 mean “Don’t know” and “Didn’t answer”.
We can use replace to replace the special codes with NaN.
age = gss['age']
empiricaldist provides a Cdf.from_seq function that takes any kind of sequence and computes the CDF of the values.
from empiricaldist import Cdf
cdf_age = Cdf.from_seq(age)
The result is a Cdf object, which provides a method called plot that plots the CDF as a line.
cdf_age.plot()
plt.xlabel('Age (years)')
plt.ylabel('CDF')
plt.title('Distribution of age');
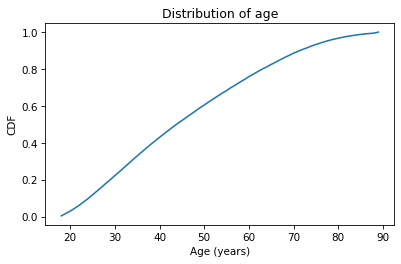
The x-axis is the ages, from 18 to 89.
The y-axis is the cumulative probabilities, from 0 to 1.
The Cdf object can be used as a function, so if you give it an age, it returns the corresponding probability in a NumPy array.
q = 51
p = cdf_age(q)
p
array(0.62121445)
q stands for “quantity”, which is another name for a value in a distribution.
p stands for probability, which is the result.
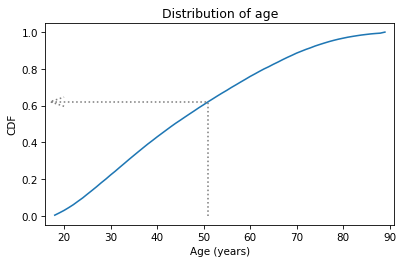
In this example, the quantity is age 51, and the corresponding probability is about 0.62.
That means that about 62% of the respondents are age 51 or younger.
The arrow in the following figure shows how you could read this value from the CDF, at least approximately.
Show code cell source
cdf_age.plot()
x = 17
draw_line(p, q, x)
draw_arrow_left(p, q, x)
plt.xlabel('Age (years)')
plt.xlim(x-1, 91)
plt.ylabel('CDF')
plt.title('Distribution of age');
The CDF is an invertible function, which means that if you have a probability, p, you can look up the corresponding quantity, q.
The Cdf object provides a method called inverse that computes the inverse of the cumulative distribution function.
p1 = 0.25
q1 = cdf_age.inverse(p1)
q1
array(32.)
In this example, we look up the probability 0.25 and the result is 32. That means that 25% of the respondents are age 32 or less. Another way to say the same thing is “age 32 is the 25th percentile of this distribution”.
If we look up probability 0.75, it returns 60, so 75% of the respondents are 60 or younger.
p2 = 0.75
q2 = cdf_age.inverse(p2)
q2
array(60.)
In the following figure, the arrows show how you could read these values from the CDF.
Show code cell source
cdf_age.plot()
x = 17
draw_line(p1, q1, x)
draw_arrow_down(p1, q1, 0)
draw_line(p2, q2, x)
draw_arrow_down(p2, q2, 0)
plt.xlabel('Age (years)')
plt.xlim(x-1, 91)
plt.ylabel('CDF')
plt.title('Distribution of age');
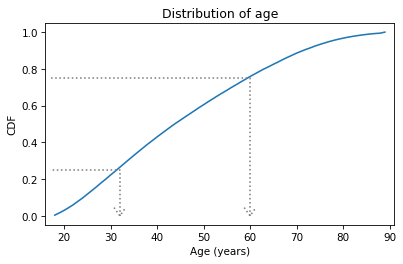
The distance from the 25th to the 75th percentile is called the interquartile range or IQR. It measures the spread of the distribution, so it is similar to standard deviation or variance. Because it is based on percentiles, it doesn’t get thrown off by outliers as much as standard deviation does. So IQR is more robust than variance, which means it works well even if there are errors in the data or extreme values.
Exercise: Using cdf_age, compute the fraction of respondents in the GSS dataset who are older than 65.
Recall that the CDF computes the fraction who are less than or equal to a value, so the complement is the fraction who exceed a value.
Exercise: The distribution of income in almost every country is long-tailed, which means there are a small number of people with very high incomes.
In the GSS dataset, the realinc column represents total household income, converted to 1986 dollars.
We can get a sense of the shape of this distribution by plotting the CDF.
Select realinc from the gss dataset, make a Cdf called cdf_income, and plot it. Remember to label the axes!
Because the tail of the distribution extends to the right, the mean is greater than the median.
Use the Cdf object to compute the fraction of respondents whose income is at or below the mean.
Comparing Distributions#
So far we’ve seen two ways to represent distributions, PMFs and CDFs.
Now we’ll use PMFs and CDFs to compare distributions, and we’ll see the pros and cons of each.
One way to compare distributions is to plot multiple PMFs on the same axes.
For example, suppose we want to compare the distribution of age for male and female respondents.
First we’ll create a Boolean Series that’s true for male respondents and another that’s true for female respondents.
male = (gss['sex'] == 1)
female = (gss['sex'] == 2)
We can use these Series to select ages for male and female respondents.
male_age = age[male]
female_age = age[female]
And plot a PMF for each.
pmf_male_age = Pmf.from_seq(male_age)
pmf_male_age.plot(label='Male')
pmf_female_age = Pmf.from_seq(female_age)
pmf_female_age.plot(label='Female')
plt.xlabel('Age (years)')
plt.ylabel('PMF')
plt.title('Distribution of age by sex')
plt.legend();
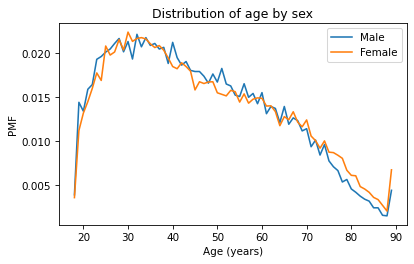
A plot as variable as this is often described as noisy. If we ignore the noise, it looks like the PMF is higher for men between ages 40 and 50, and higher for women between ages 70 and 80. But both of those differences might be due to randomness.
Now let’s do the same thing with CDFs – everything is the same except we replace Pmf with Cdf.
cdf_male_age = Cdf.from_seq(male_age)
cdf_male_age.plot(label='Male')
cdf_female_age = Cdf.from_seq(female_age)
cdf_female_age.plot(label='Female')
plt.xlabel('Age (years)')
plt.ylabel('CDF')
plt.title('Distribution of age by sex')
plt.legend();
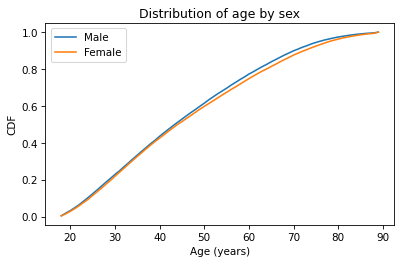
Because CDFs smooth out randomness, they provide a better view of real differences between distributions. In this case, the lines are close together until age 40 – after that, the CDF is higher for men than women.
So what does that mean? One way to interpret the difference is that the fraction of men below a given age is generally more than the fraction of women below the same age. For example, about 79% of men are 60 or less, compared to 76% of women.
cdf_male_age(60), cdf_female_age(60)
(array(0.7721998), array(0.7474241))
Going the other way, we could also compare percentiles. For example, the median age woman is older than the median age man, by about one year.
cdf_male_age.inverse(0.5), cdf_female_age.inverse(0.5)
(array(44.), array(45.))
Exercise: What fraction of men are over 80? What fraction of women?
Comparing Incomes#
As another example, let’s look at household income and compare the distribution before and after 1995 (I chose 1995 because it’s roughly the midpoint of the survey).
We’ll make two Boolean Series objects to select respondents interviewed before and after 1995.
pre95 = (gss['year'] < 1995)
post95 = (gss['year'] >= 1995)
Now we can plot the PMFs of realinc, which records household income converted to 1986 dollars.
realinc = gss['realinc']
Pmf.from_seq(realinc[pre95]).plot(label='Before 1995')
Pmf.from_seq(realinc[post95]).plot(label='After 1995')
plt.xlabel('Income (1986 USD)')
plt.ylabel('PMF')
plt.title('Distribution of income')
plt.legend();
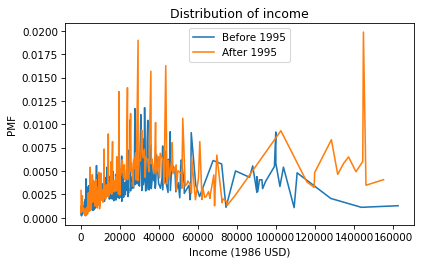
There are a lot of unique values in this distribution, and none of them appear very often. As a result, the PMF is so noisy and we can’t really see the shape of the distribution. It’s also hard to compare the distributions. It looks like there are more people with high incomes after 1995, but it’s hard to tell. We can get a clearer picture with a CDF.
Cdf.from_seq(realinc[pre95]).plot(label='Before 1995')
Cdf.from_seq(realinc[post95]).plot(label='After 1995')
plt.xlabel('Income (1986 USD)')
plt.ylabel('CDF')
plt.title('Distribution of income')
plt.legend();
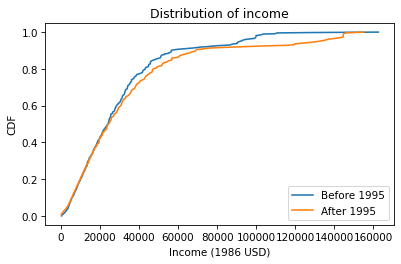
Below $30,000 the CDFs are almost identical; above that, we can see that the post-1995 distribution is shifted to the right. In other words, the fraction of people with high incomes is about the same, but the income of high earners has increased.
In general, I recommend CDFs for exploratory analysis. They give you a clear view of the distribution, without too much noise, and they are good for comparing distributions.
Exercise: Let’s compare incomes for different levels of education in the GSS dataset.
We’ll use the degree column, which represents the highest degree each respondent has earned.
In this column, the value 1 indicates a high school diploma, 2 indicates an Associate’s degree, and 3 indicates a Bachelor’s degree.
Compute and plot the distribution of income for each group. Remember to label the CDFs, display a legend, and label the axes. Write a few sentences that describe and interpret the results.
# You can use the following Boolean Series objects to select groups from `realinc`
# Select educ
degree = gss['degree']
# Bachelor's degree
bach = (degree == 3)
# Associate degree
assc = (degree == 2)
# High school
high = (degree == 1)
Modeling Distributions#
Some distributions have names. For example, you might be familiar with the normal distribution, also called the Gaussian distribution or the bell curve. And you might have heard of others like the exponential distribution, binomial distribution, or maybe Poisson distribution. These “distributions with names” are called theoretical because they are based on mathematical functions, as contrasted with empirical distributions, which are based on data.
Many things we measure have distributions that are well approximated by theoretical distributions, so these distributions are sometimes good models for the real world. In this context, what I mean by a model is a simplified description of the world that is accurate enough for its intended purpose.
To check whether a theoretical distribution is a good model for a dataset, we can compare the CDF of the data to the CDF of a normal distribution with the same mean and standard deviation. I’ll demonstrate with a sample from a normal distribution, then we’ll try it with real data.
The following statement uses NumPy’s random library to generate 1000 values from a normal distribution with mean 10 and standard deviation 1.
Show code cell content
import numpy as np
np.random.seed(17)
sample = np.random.normal(10, 1, size=1000)
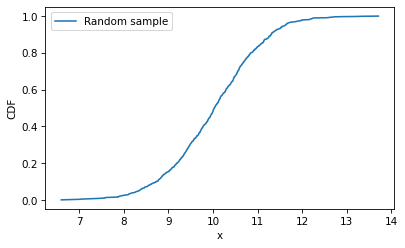
Here’s what the empirical distribution of the sample looks like.
cdf_sample = Cdf.from_seq(sample)
cdf_sample.plot(label='Random sample')
plt.xlabel('x')
plt.ylabel('CDF')
plt.legend();
Now let’s compute the CDF of a normal distribution with the actual values of the mean and standard deviation.
from scipy.stats import norm
qs = np.linspace(6, 14)
ps = norm(10, 1).cdf(qs)
First we import norm from scipy.stats, which is a collection of functions related to statistics.
Then we use linspace() to create an array of equally-spaced values from -3 to 3 – those are the qs where we will evaluate the normal CDF.
Next, norm(10, 1) creates an object that represents a normal distribution with mean 10 and standard deviation 1.
Finally, cdf computes the CDF of the normal distribution, evaluated at each of the qs.
I’ll plot the normal CDF with a gray line and then plot the CDF of the data again.
plt.plot(qs, ps, color='gray', label='Normal CDF')
cdf_sample.plot(label='Random sample')
plt.xlabel('x')
plt.ylabel('CDF')
plt.legend();
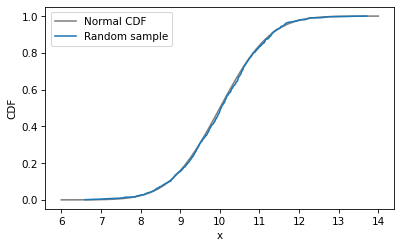
The CDF of the random sample agrees with the normal model – which is not surprising because the data were actually sampled from a normal distribution. When we collect data in the real world, we do not expect it to fit a normal distribution as well as this. In the next exercise, we’ll try it and see.
Exercise: In many datasets, the distribution of income is approximately lognormal, which means that the logarithms of the incomes fit a normal distribution. Let’s see whether that’s true for the GSS data.
Extract
realincfromgssand compute the logarithms of the incomes usingnp.log10().Compute the mean and standard deviation of the log-transformed incomes.
Use
normto make a normal distribution with the same mean and standard deviation as the log-transformed incomes.Plot the CDF of the normal distribution.
Compute and plot the CDF of the log-transformed incomes.
How similar are the CDFs of the log-transformed incomes and the normal distribution?
# Extract realinc and compute its log
realinc = gss['realinc']
log_realinc = np.log10(realinc)
Kernel Density Estimation#
We have seen two ways to represent distributions, PMFs and CDFs.
Now we’ll learn another way: a probability density function, or PDF.
The norm function, which we used to compute the normal CDF, can also compute the normal PDF.
xs = np.linspace(6, 14)
ys = norm(10, 1).pdf(xs)
Here’s what it looks like.
plt.plot(xs, ys, color='gray', label='Normal PDF')
plt.xlabel('x')
plt.ylabel('PDF')
plt.title('Normal density function')
plt.legend();
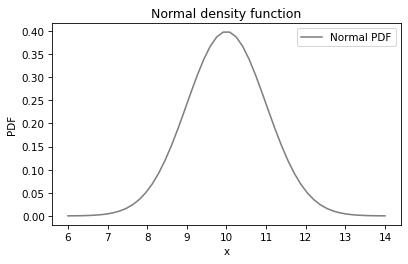
The normal PDF is the classic “bell curve”. Now, it is tempting to compare the PMF of the data to the PDF of the normal distribution, but that doesn’t work. Let’s see what happens if we try:
plt.plot(xs, ys, color='gray', label='Normal PDF')
pmf_sample = Pmf.from_seq(sample)
pmf_sample.plot(label='Random sample')
plt.xlabel('x')
plt.ylabel('PDF')
plt.title('Normal density function')
plt.legend();
The PMF of the sample is a flat line across the bottom. In the random sample, every value is unique, so they all have the same probability, one in 1000.
However, we can use the points in the sample to estimate the PDF of the distribution they came from.
This process is called kernel density estimation, or KDE.
To generate a KDE plot, we’ll use the Seaborn library, imported as sns.
Seaborn provides kdeplot, which takes the sample, estimates the PDF, and plots it.
import seaborn as sns
sns.kdeplot(sample, label='Estimated sample PDF')
plt.xlabel('x')
plt.ylabel('PDF')
plt.title('Normal density function')
plt.legend();
Now we can compare the KDE plot and the normal PDF.
plt.plot(xs, ys, color='gray', label='Normal PDF')
sns.kdeplot(sample, label='Estimated sample PDF')
plt.xlabel('x')
plt.ylabel('PDF')
plt.title('Normal density function')
plt.legend();
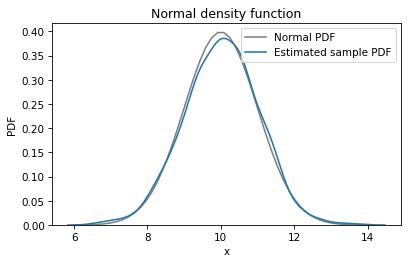
The KDE plot matches the normal PDF well. We can see places where the data deviate from the model, but because we know the data really came from a normal distribution, we know those deviations are due to random sampling.
Comparing PDFs is a sensitive way to look for differences, but often it is too sensitive – it can be hard to tell whether apparent differences mean anything, or if they are just random, as in this case.
Exercise: In a previous exercise, we used CDFs to see if the distribution of income fits a lognormal distribution. We can make the same comparison using a PDF and KDE.
Again, extract
realincfromgssand compute its logarithm usingnp.log10().Compute the mean and standard deviation of the log-transformed incomes.
Use
normto make a normal distribution with the same mean and standard deviation as the log-transformed incomes.Plot the PDF of the normal distribution.
Use
sns.kdeplot()to estimate and plot the density of the log-transformed incomes.
# Extract realinc and compute its log
realinc = gss['realinc']
log_realinc = np.log10(realinc)
Summary#
In this chapter, we’ve seen three ways to visualize distributions: PMFs, CDFs, and KDE plots. In general, I use CDFs when I am exploring data – that way, I get the best view of what’s going on without getting distracted by noise. Then, if I am presenting results to an audience unfamiliar with CDFs, I might use a PMF if the dataset contains a small number of unique values, or KDE if there are many unique values.