Political Alignment and Polarization#
This is the second in a series of notebooks that make up a case study in exploratory data analysis. This case study is part of the Elements of Data Science curriculum. Click here to run this notebook on Colab.
from os.path import basename, exists
def download(url):
filename = basename(url)
if not exists(filename):
from urllib.request import urlretrieve
local, _ = urlretrieve(url, filename)
print('Downloaded ' + local)
download('https://github.com/AllenDowney/PoliticalAlignmentCaseStudy/raw/v1/utils.py')
This chapter and the next make up a case study that uses data from the General Social Survey (GSS) to explore political beliefs and political alignment (conservative, moderate, or liberal) in the United States. In this chapter, we will:
Compare the distributions of political alignment from 1974 and 2022.
Plot the mean and standard deviation of responses over time as a way of quantifying shifts in political alignment and polarization.
Use local regression to plot a smooth line through noisy data.
Use cross tabulation to compute the fraction of respondents in each category over time.
Plot the results using a custom color palette.
As an exercise, you will look at changes in political party affiliation over the same period. In the next chapter, we’ll use the same dataset to explore the relationship between political alignment and other attitudes and beliefs.
The following cell installs the empiricaldist library if necessary.
try:
import empiricaldist
except ImportError:
!pip install empiricaldist
If everything we need is installed, the following cell should run without error.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from empiricaldist import Pmf
Loading the data#
In the previous notebook, we downloaded GSS data, loaded and cleaned it, resampled it to correct for stratified sampling, and then saved the data in an HDF file, which is much faster to load. In this and the following notebooks, we’ll download the HDF file and load it.
The following cell downloads the data file if necessary.
download(
'https://github.com/AllenDowney/PoliticalAlignmentCaseStudy/raw/v1/gss_pacs_resampled.hdf'
)
We’ll use an extract of the data that I have cleaned and resampled to correct for stratified sampling.
Instructions for downloading the file are in the notebook for this chapter.
It contains three resamplings – we’ll use the first, gss0, to get started.
datafile = 'gss_pacs_resampled.hdf'
gss = pd.read_hdf(datafile, key='gss0')
gss.shape
(72390, 207)
Political Alignment#
The people surveyed for the GSS were asked about their “political alignment”, which is where they place themselves on a spectrum from liberal to conservative. They were asked:
We hear a lot of talk these days about liberals and conservatives. I’m going to show you a seven-point scale on which the political views that people might hold are arranged from extremely liberal–point 1–to extremely conservative–point 7. Where would you place yourself on this scale?
Here is the scale they were shown:
Code |
Response |
|---|---|
1 |
Extremely liberal |
2 |
Liberal |
3 |
Slightly liberal |
4 |
Moderate |
5 |
Slightly conservative |
6 |
Conservative |
7 |
Extremely conservative |
The variable polviews contains the responses.
polviews = gss['polviews']
To see how the responses have changed over time, we’ll inspect them at the beginning and end of the observation period.
First we’ll make a Boolean Series that’s True for responses from 1974,
and select the responses from 1974.
year74 = (gss['year'] == 1974)
polviews74 = polviews[year74]
And we can do the same for 2022.
year22 = (gss['year'] == 2022)
polviews22 = polviews[year22]
We’ll use the following function to count the number of times each response occurs.
def values(series):
'''Count the values and sort.
series: pd.Series
returns: series mapping from values to frequencies
'''
return series.value_counts(dropna=False).sort_index()
Here are the responses from 1974.
values(polviews74)
1.0 31
2.0 201
3.0 211
4.0 538
5.0 223
6.0 181
7.0 30
NaN 69
Name: polviews, dtype: int64
And here are the responses from 2022.
values(polviews22)
1.0 184
2.0 433
3.0 391
4.0 1207
5.0 472
6.0 548
7.0 194
NaN 115
Name: polviews, dtype: int64
Looking at these counts, we can get an idea of what the distributions look like, but in the next section we’ll get a clearer picture by plotting them.
Visualizing Distributions#
To visualize these distributions, we’ll use a Probability Mass Function (PMF), which is similar to a histogram, but there are two differences:
In a histogram, values are often put in bins, with more than one value in each bin. In a PMF each value gets its own bin.
A histogram computes a count, that is, how many times each value appears; a PMF computes a probability, that is, what fraction of the time each value appears.
We’ll use the Pmf class from empiricaldist to compute a PMF.
from empiricaldist import Pmf
pmf74 = Pmf.from_seq(polviews74)
pmf74
| probs | |
|---|---|
| 1.0 | 0.021908 |
| 2.0 | 0.142049 |
| 3.0 | 0.149117 |
| 4.0 | 0.380212 |
| 5.0 | 0.157597 |
| 6.0 | 0.127915 |
| 7.0 | 0.021201 |
The following cell imports the function we’ll use to decorate the axes in plots.
from utils import decorate
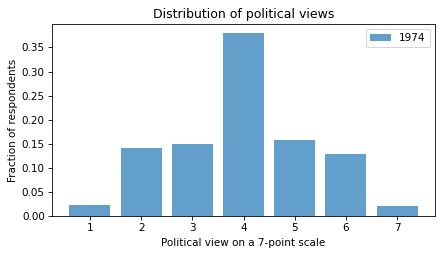
Here’s the distribution from 1974:
pmf74.bar(label='1974', color='C0', alpha=0.7)
decorate(
xlabel='Political view on a 7-point scale',
ylabel='Fraction of respondents',
title='Distribution of political views',
)
And from 2022:
pmf22 = Pmf.from_seq(polviews22)
pmf22.bar(label='2022', color='C1', alpha=0.7)
decorate(
xlabel='Political view on a 7-point scale',
ylabel='Fraction of respondents',
title='Distribution of political views',
)
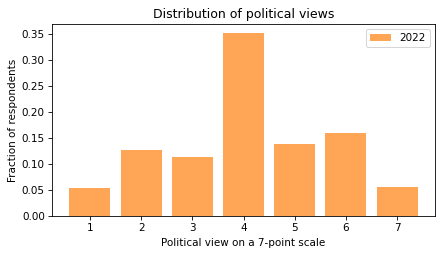
In both cases, the most common response is 4, which is the code for ‘moderate’. Few respondents describe themselves as ‘extremely’ liberal or conservative.
So maybe we’re not so polarized after all.
To make it easier to compare the distributions, I’ll plot them side by side.
df = pd.DataFrame({'pmf74': pmf74, 'pmf22': pmf22})
df.plot(kind='bar')
decorate(
xlabel='Political view on a 7-point scale',
ylabel='Fraction of respondents',
title='Distribution of political views',
)

Now we can see the changes in the distribution more clearly – the fraction of people at the extremes (1, 6, and 7) has increased, and the fraction of people near the middle (2, 3, 4, and 5) has decreased.
Exercise: To summarize these changes, we can compare the mean and standard deviation of polviews in 1974 and 2022.
The mean of the responses measures the balance of people in the population with liberal or conservative leanings.
If the mean increases over time, that might indicate a shift in the population toward conservatism.
The standard deviation measures the dispersion of views in the population – if it increases over time, that might indicate an increase in polarization.
Compute the mean and standard deviation of polviews74 and polviews22.
What do they indicate about changes over this interval?
Plotting a Time Series#
At this point we have looked at the endpoints, 1974 and 2022, but we don’t know what happened in between.
To see how the distribution changed over time, we can use groupby to group the respondents by year.
gss_by_year = gss.groupby('year')
type(gss_by_year)
pandas.core.groupby.generic.DataFrameGroupBy
The result is a DataFrameGroupBy object that represents a collection of groups.
We can loop through the groups and display the number of respondents in each:
for year, group in gss_by_year:
print(year, len(group))
1972 1613
1973 1504
1974 1484
1975 1490
1976 1499
1977 1530
1978 1532
1980 1468
1982 1860
1983 1599
1984 1473
1985 1534
1986 1470
1987 1819
1988 1481
1989 1537
1990 1372
1991 1517
1993 1606
1994 2992
1996 2904
1998 2832
2000 2817
2002 2765
2004 2812
2006 4510
2008 2023
2010 2044
2012 1974
2014 2538
2016 2867
2018 2348
2021 4032
2022 3544
Now we can use the bracket operator to select the polviews column.
polviews_by_year = gss_by_year['polviews']
type(polviews_by_year)
pandas.core.groupby.generic.SeriesGroupBy
A column from a DataFrameGroupBy is a SeriesGroupBy.
If we invoke mean on it, the result is a series that contains the mean of polviews for each year of the survey.
mean_series = polviews_by_year.mean()
And here’s what it looks like.
mean_series.plot(color='C2', label='polviews')
decorate(xlabel='Year',
ylabel='Mean (7 point scale)',
title='Mean of polviews')
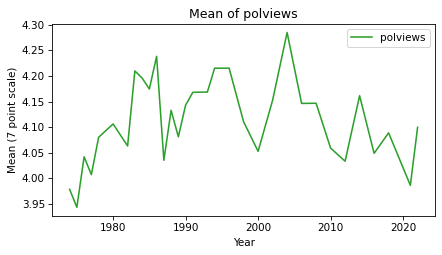
The mean increased between 1974 and 2000, decreased since then, and ended up almost where it started. The difference between the highest and lowest points is only 0.3 points on a 7-point scale, so none of these changes are drastic.
mean_series.max() - mean_series.min()
0.34240143126104083
Exercise: The standard deviation quantifies the spread of the distribution, which is one way to measure polarization.
Plot standard deviation of polviews for each year of the survey from 1972 to 2022.
Does it show evidence of increasing polarization?
Smoothing the Curve#
In the previous section we plotted mean and standard deviation of polviews over time.
In both plots, the values are highly variable from year to year.
We can use local regression to compute a smooth line through these data points.
The following function takes a Pandas Series and uses an algorithm called LOWESS to compute a smooth line.
LOWESS stands for ‘locally weighted scatterplot smoothing’.
from statsmodels.nonparametric.smoothers_lowess import lowess
def make_lowess(series):
'''Use LOWESS to compute a smooth line.
series: pd.Series
returns: pd.Series
'''
y = series.values
x = series.index.values
smooth = lowess(y, x)
index, data = np.transpose(smooth)
return pd.Series(data, index=index)
We’ll use the following function to plot data points and the smoothed line.
def plot_series_lowess(series, color):
'''Plots a series of data points and a smooth line.
series: pd.Series
color: string or tuple
'''
series.plot(linewidth=0, marker='o', color=color, alpha=0.5)
smooth = make_lowess(series)
smooth.plot(label='', color=color)
The following figure shows the mean of polviews and a smooth line.
mean_series = gss_by_year['polviews'].mean()
plot_series_lowess(mean_series, 'C2')
decorate(xlabel='Year',
ylabel='Mean (7 point scale)',
title='Mean of polviews')
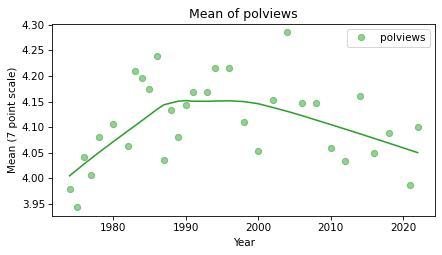
One reason the PMFs for 1974 and 2022 did not look very different is that the mean went up (more conservative) and then down again (more liberal). Generally, it looks like the U.S. has been trending toward liberal for the last 20 years, or more, at least in the sense of how people describe themselves.
Exercise: Use plot_series_lowess to plot the standard deviation of polviews with a smooth line.
Cross Tabulation#
In the previous sections, we treated polviews as a numerical quantity, so we were able to compute means and standard deviations.
But the responses are really categorical, which means that each value represents a discrete category, like ‘liberal’ or ‘conservative’.
In this section, we’ll treat polviews as a categorical variable, compute the number of respondents in each category during each year, and plot changes over time.
Pandas provides a function called crosstab that computes a cross tabulation
Here’s how we can use to compute the number of respondents in each category during each year.
year = gss['year']
column = gss['polviews']
xtab = pd.crosstab(year, column)
The result is a DataFrame with one row for each year and one column for each category.
Here are the first few rows.
xtab.head()
| polviews | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | 6.0 | 7.0 |
|---|---|---|---|---|---|---|---|
| year | |||||||
| 1974 | 31 | 201 | 211 | 538 | 223 | 181 | 30 |
| 1975 | 56 | 184 | 207 | 540 | 204 | 162 | 45 |
| 1976 | 31 | 198 | 175 | 564 | 209 | 206 | 34 |
| 1977 | 37 | 181 | 214 | 594 | 243 | 164 | 42 |
| 1978 | 21 | 140 | 255 | 559 | 265 | 187 | 25 |
It contains one row for each value of year and one column for each value of polviews. Reading the first row, we see that in 1974, 31 people gave response 1, 201 people gave response 2, and so on.
The number of respondents varies from year to year.
To make meaningful comparisons over time, we need to normalize the results, which means computing for each year the fraction of respondents in each category, rather than the count.
crosstab takes an optional argument that normalizes each row.
xtab_norm = pd.crosstab(year, column, normalize='index')
Here’s what that looks like for the 7-point scale.
xtab_norm.head()
| polviews | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | 6.0 | 7.0 |
|---|---|---|---|---|---|---|---|
| year | |||||||
| 1974 | 0.021908 | 0.142049 | 0.149117 | 0.380212 | 0.157597 | 0.127915 | 0.021201 |
| 1975 | 0.040057 | 0.131617 | 0.148069 | 0.386266 | 0.145923 | 0.115880 | 0.032189 |
| 1976 | 0.021877 | 0.139732 | 0.123500 | 0.398024 | 0.147495 | 0.145378 | 0.023994 |
| 1977 | 0.025085 | 0.122712 | 0.145085 | 0.402712 | 0.164746 | 0.111186 | 0.028475 |
| 1978 | 0.014463 | 0.096419 | 0.175620 | 0.384986 | 0.182507 | 0.128788 | 0.017218 |
Looking at the numbers in the table, it’s hard to see what’s going on. In the next section, we’ll plot the results.
To make the results easier to interpret, I’m going to replace the numeric codes 1-7 with strings. First I’ll make a dictionary that maps from numbers to strings:
polviews_map = {
1: 'Extremely liberal',
2: 'Liberal',
3: 'Slightly liberal',
4: 'Moderate',
5: 'Slightly conservative',
6: 'Conservative',
7: 'Extremely conservative',
}
Then we can use the replace function like this:
polviews7 = gss['polviews'].replace(polviews_map)
We can use values to confirm that the values in polviews7 are strings.
values(polviews7)
Conservative 9612
Extremely conservative 2145
Extremely liberal 2095
Liberal 7309
Moderate 24157
Slightly conservative 9816
Slightly liberal 7799
NaN 9457
Name: polviews, dtype: int64
If we make the cross tabulation again, we can see that the column names are strings.
xtab_norm = pd.crosstab(year, polviews7, normalize='index')
xtab_norm.columns
Index(['Conservative', 'Extremely conservative', 'Extremely liberal',
'Liberal', 'Moderate', 'Slightly conservative', 'Slightly liberal'],
dtype='object', name='polviews')
We are almost ready to plot the results, but first we need some colors.
Color Palettes#
To represent political views, we’ll use a color palette from blue to purple to red. Seaborn provides a variety of color palettes – we’ll start with this one, which includes shades of blue and red. To represent moderates, we’ll replace the middle color with purple.
You can read more about Seaborn’s color palettes here.
palette = sns.color_palette('RdBu_r', 7)
palette[3] = 'purple'
sns.palplot(palette)

We’ll make a dictionary that maps from the responses to the corresponding colors.
color_map = {}
for i, group in polviews_map.items():
color_map[group] = palette[i-1]
for key, value in color_map.items():
print(key, value)
Extremely liberal (0.16339869281045757, 0.44498269896193776, 0.6975009611687812)
Liberal (0.4206843521722416, 0.6764321414840447, 0.8186851211072664)
Slightly liberal (0.7614763552479817, 0.8685121107266438, 0.924567474048443)
Moderate purple
Slightly conservative (0.9824682814302191, 0.8006920415224913, 0.7061130334486736)
Conservative (0.8945790080738177, 0.5038062283737024, 0.39976931949250283)
Extremely conservative (0.7284890426758939, 0.15501730103806227, 0.1973856209150327)
Now we’re ready to plot.
Plotting a Cross Tabulation#
To see how the fraction of people with each political alignment has changed over time,
we’ll use plot_series_lowess to plot the columns from xtab_norm.
Here are the seven categories plotted as a function of time.
The bbox_to_anchor argument passed to plt.legend puts the legend outside the axes of the figure.
groups = list(polviews_map.values())
for group in groups:
series = xtab_norm[group]
plot_series_lowess(series, color_map[group])
decorate(
xlabel='Year',
ylabel='Proportion',
title='Fraction of respondents with each political view',
)
plt.legend(bbox_to_anchor=(1.02, 1.02));
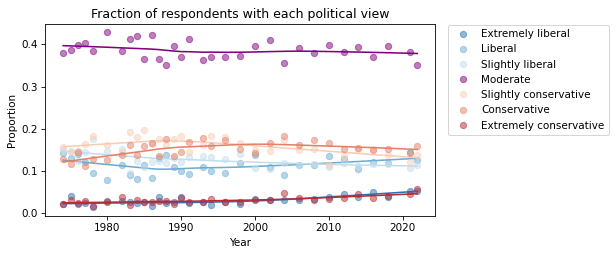
This way of looking at the results suggests that changes in political alignment during this period have generally been slow and small. The fraction of self-described moderates has decreased slightly. The fraction of conservatives increased, but seems to be decreasing now; the number of liberals seems to be increasing.
The fraction of people at the extremes has increased, but it is hard to see clearly in this figure. We can get a better view by plotting just the extremes.
selected_groups = ['Extremely liberal', 'Extremely conservative']
for group in selected_groups:
series = xtab_norm[group]
plot_series_lowess(series, color_map[group])
decorate(
xlabel='Year',
ylabel='Proportion',
ylim=[0, 0.065],
title='Fraction of respondents with extreme political views',
)
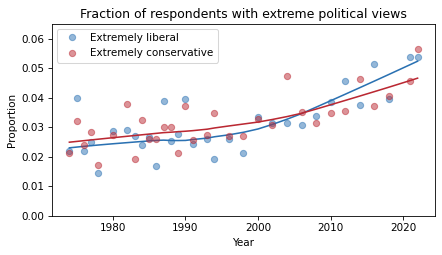
I used ylim to set the limits of the y-axis so it starts at zero, to avoid making the changes seem bigger than they are.
This figure shows that the fraction of people who describe themselves as ‘extreme’ has increased from about 2.5% to about 5%.
In relative terms, that’s a big increase.
But in absolute terms these tails of the distribution are still small.
Exercise: Let’s do a similar analysis with partyid, which encodes responses to the question:
Generally speaking, do you usually think of yourself as a Republican, Democrat, Independent, or what?
The valid responses are:
Code |
Response |
|---|---|
0 |
Strong democrat |
1 |
Not str democrat |
2 |
Ind, near dem |
3 |
Independent |
4 |
Ind, near rep |
5 |
Not str republican |
6 |
Strong republican |
7 |
Other party |
In the notebook for this chapter, there are some suggestions to get you started.
Here are the steps I suggest:
If you have not already saved this notebook, you should do that first. If you are running on Colab, select ‘Save a copy in Drive’ from the File menu.
Now, before you modify this notebook, make another copy and give it an appropriate name.
Search and replace
polviewswithpartyid(use ‘Edit->Find and replace’).Run the notebook from the beginning and see what other changes you have to make.
What changes in party affiliation do you see over the last 50 years? Are things going in the directions you expected?
Summary#
This chapter introduces two new tools: local regression for computing a smooth curve through noisy data, and cross tabulation for counting the number of people, or fraction, in each group over time.
Now that we have a sense of how political alignment as changed, in the next chapter we’ll explore the relationship between political alignment and other beliefs and attitudes.
Political Alignment Case Study
Copyright 2020 Allen B. Downey
License: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)