Inference and Gender Gaps#
Allen Downey
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
gss = pd.read_hdf('gss_feminism_2022.hdf', key='gss')
Here are the 10 fe variables and the text of the questions.
fechld
A. A working mother can establish just as warm and secure a relationship with her children as a mother who does not work.
fefam
D. It is much better for everyone involved if the man is the achiever outside the home and the woman takes care of the home and family.
fehelp
B. It is more important for a wife to help her husband’s career than to have one herself.
fehire
Because of past discrimination, employers should make special efforts to hire and promote qualified women.
fehome
Women should take care of running their homes and leave running the country up to men.
fejobaff
Some people say that because of past discrimination, women should be given preference in hiring and promotion. Others say that such preference in hiring and promotion of women is wrong because it discriminates against men. What about your opinion - are you for or against preferential hiring and promotion of women? IF FOR:Do you favor preference in hiring and promotion strongly or not strongly? IF AGAINST:Do you oppose preference in hiring and promotion strongly or not strongly?
fepol
A. Tell me if you agree or disagree with this statement: Most men are better suited emotionally for politics than are most women.
fepres
If your party nominated a woman for President, would you vote for her if she were qualified for the job?
fepresch
C. A preschool child is likely to suffer if his or her mother works.
fework
Do you approve or disapprove of a married woman earning money in business or industry if she has a husband capable of supporting her?
fe_columns = [x for x in gss.columns if x.startswith('fe')]
fe_columns
['fechld',
'fefam',
'fehelp',
'fehire',
'fehome',
'fejobaff',
'fepol',
'fepres',
'fepresch',
'fework']
from utils import decorate
grouped = gss.groupby('year')
intervals = pd.DataFrame(columns=['first', 'last', '# years'], dtype=int)
for column in fe_columns:
counts = grouped[column].count()
nonzero = counts.replace(0, np.nan).dropna()
n_years = len(nonzero)
first, last = nonzero.index.min(), nonzero.index.max()
intervals.loc[column] = first, last, n_years
intervals
| first | last | # years | |
|---|---|---|---|
| fechld | 1977 | 2022 | 23 |
| fefam | 1977 | 2022 | 23 |
| fehelp | 1977 | 1998 | 11 |
| fehire | 1996 | 2022 | 13 |
| fehome | 1974 | 1998 | 16 |
| fejobaff | 1996 | 2022 | 13 |
| fepol | 1974 | 2022 | 27 |
| fepres | 1972 | 2010 | 19 |
| fepresch | 1977 | 2022 | 23 |
| fework | 1972 | 1998 | 17 |
current_columns = intervals.query('last==2022').index.values
current_columns
array(['fechld', 'fefam', 'fehire', 'fejobaff', 'fepol', 'fepresch'],
dtype=object)
For each variable, I’ll select “agree” and “strongly agree”, except for fework, where I’ve selected “approve”.
agree_responses = {
'fechld': [1, 2],
'fefam': [1, 2],
'fehelp': [1, 2],
'fehire': [1, 2],
'fehome': [1],
'fejobaff': [1, 2],
'fepol': [1],
'fepres': [1],
'fepresch': [1, 2],
'fework': [1],
}
Resampling#
resample_by_year uses weighted bootstrap resampling to simultaneously correct for stratified sampling and estimate error bounds on a year-by year basis.
from utils import resample_by_year
np.random.seed(17)
samples = [resample_by_year(gss, "wtssall") for i in range(101)]
def make_series(data, query, column):
subset = data.query(query)
xtab = pd.crosstab(subset['year'], subset[column], normalize='index')
series = xtab[agree_responses[column]].sum(axis=1)
return series * 100
from utils import make_lowess
def make_smooth_series(data, query, column):
series = make_series(data, query, column)
smooth = make_lowess(series)
return smooth
plot_percentiles plots the median of the resampled estimates as a line and a 90% confidence interval as a shaded area.
def percentile_rows(series_seq, ps):
"""Computes percentiles from aligned series.
series_seq: list of sequences
ps: cumulative probabilities
returns: NumPy array
"""
array = np.array(series_seq)
rows = np.percentile(array, ps, axis=0)
return rows
def plot_percentiles(series_seq, ps=None, **options):
"""Plot the low, median, and high percentiles.
series_seq: sequence of Series
options: options passed plt.plot and plt.fill_between
"""
label = options.pop('label', '')
ps = [5, 50, 95]
xs = series_seq[0].index
low, med, high = percentile_rows(series_seq, ps)
plt.plot(xs, med, alpha=0.5, **options)
plt.fill_between(xs, low, high, linewidth=0, alpha=0.2, **options)
offset = adjust_map.get((column, label), 0)
x = xs[0] - 0.5
y = med[0] + offset
plt.text(x, y, label, ha='right', va='center')
def plot_median(series_seq, column, **options):
"""Plot the low, median, and high percentiles.
series_seq: sequence of Series
ps: percentiles to use for low, medium and high
label: string label for the median line
options: options passed plt.plot and plt.fill_between
"""
label = options.pop('label', '')
xs = series_seq[0].index
med = percentile_rows(series_seq, 50)
plt.plot(xs, med, alpha=0.5, **options)
offset = adjust_map.get((column, label), 0)
x = xs[0] - 0.5
y = med[0] + offset
plt.text(x, y, label, ha='right', va='center')
def plot_series_bounds(column, query1, query2):
male_series_seq = [make_series(sample, query1, column)
for sample in samples]
female_series_seq = [make_series(sample, query2, column)
for sample in samples]
plot_percentiles(male_series_seq, label='male')
plot_percentiles(female_series_seq, label='female')
decorate(ylabel='Percent agree/approve',
xlim=[1971, 2023],
title=column)
def plot_four_series(column, smooth=False, bounds=False):
queries = ['sex==1 & age<30', 'sex==1 & age>=30',
'sex==2 & age<30', 'sex==2 & age>=30']
colors = ['C0', 'C0', 'C1', 'C1']
styles = ['-', '--', '-', '--']
short_labels = ['M<30', 'M≥30', 'F<30', 'F≥30']
long_labels = ['Male <30', 'Male ≥30', 'Female <30', 'Female ≥30']
for i, query in enumerate(queries):
if smooth:
series_seq = [make_smooth_series(sample, query, column)
for sample in samples]
else:
series_seq = [make_series(sample, query, column)
for sample in samples]
options = dict(color=colors[i], ls=styles[i], label=short_labels[i])
if bounds:
plot_percentiles(series_seq, **options)
else:
plot_median(series_seq, column, **options)
decorate(ylabel='Percent agree',
xlim=[1971, 2023])
Plot without smoothing#
adjust_map = {('fejobaff', 'M<30'): -1.3,
('fejobaff', 'M≥30'): -0.65,
('fepol', 'F≥30'): 1,
}
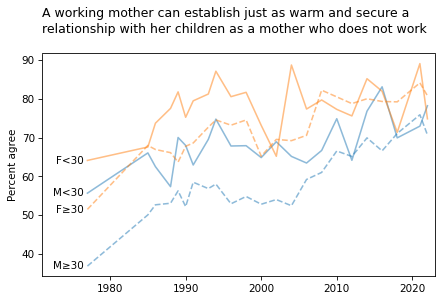
smooth = False
title = """A working mother can establish just as warm and secure a
relationship with her children as a mother who does not work
"""
plot_four_series('fechld', smooth=smooth)
plt.title(title, loc='left');
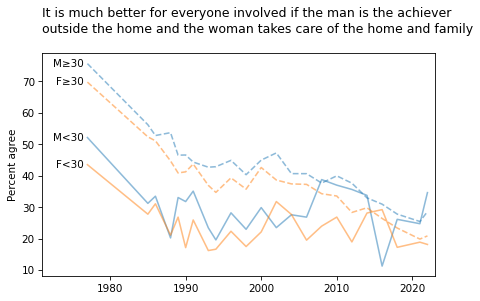
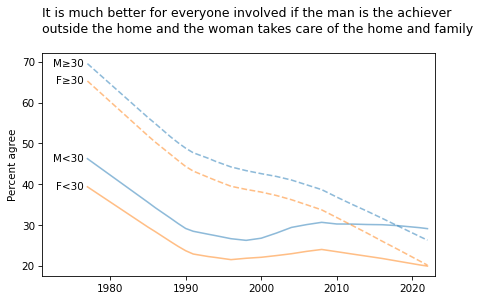
title = """It is much better for everyone involved if the man is the achiever
outside the home and the woman takes care of the home and family
"""
plot_four_series('fefam', smooth=smooth)
plt.title(title, loc='left');
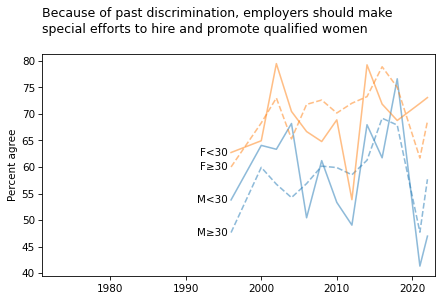
title = """Because of past discrimination, employers should make
special efforts to hire and promote qualified women
"""
plot_four_series('fehire', smooth=smooth)
plt.title(title, loc='left');
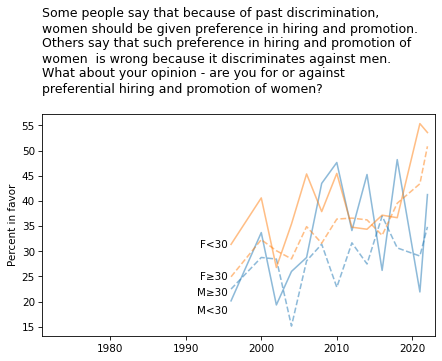
title = """Some people say that because of past discrimination,
women should be given preference in hiring and promotion.
Others say that such preference in hiring and promotion of
women is wrong because it discriminates against men.
What about your opinion - are you for or against
preferential hiring and promotion of women?
"""
plot_four_series('fejobaff', smooth=smooth)
plt.title(title, loc='left')
plt.ylabel('Percent in favor');
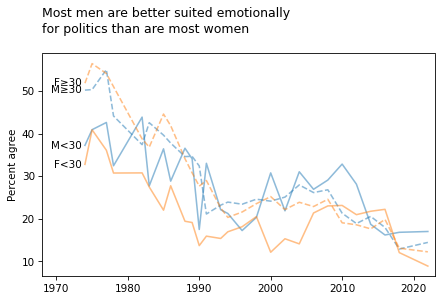
title = """Most men are better suited emotionally
for politics than are most women
"""
plot_four_series('fepol', smooth=smooth)
plt.title(title, loc='left')
plt.xlim([1968, 2023]);
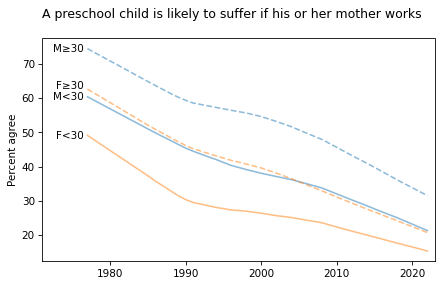
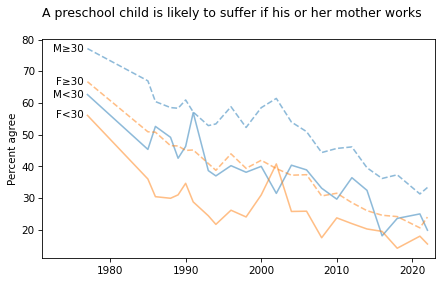
title = """A preschool child is likely to suffer if his or her mother works
"""
plot_four_series('fepresch', smooth=smooth)
plt.title(title, loc='left');
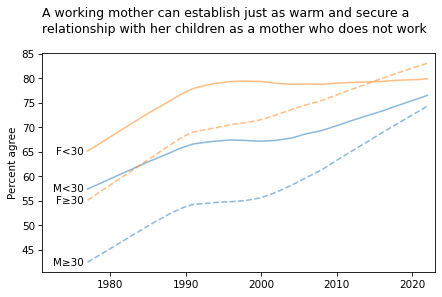
Plot with smoothing#
adjust_map = {('fepresch', 'F≥30'): 1,
}
smooth = True
title = """A working mother can establish just as warm and secure a
relationship with her children as a mother who does not work
"""
plot_four_series('fechld', smooth=smooth)
plt.title(title, loc='left');
title = """It is much better for everyone involved if the man is the achiever
outside the home and the woman takes care of the home and family
"""
plot_four_series('fefam', smooth=smooth)
plt.title(title, loc='left');
title = """Because of past discrimination, employers should make
special efforts to hire and promote qualified women
"""
plot_four_series('fehire', smooth=smooth)
plt.title(title, loc='left');
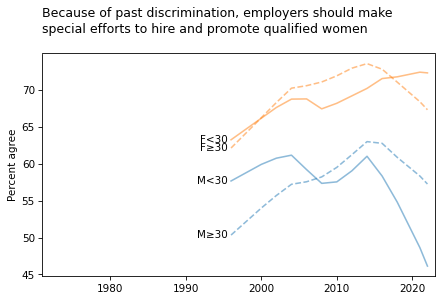
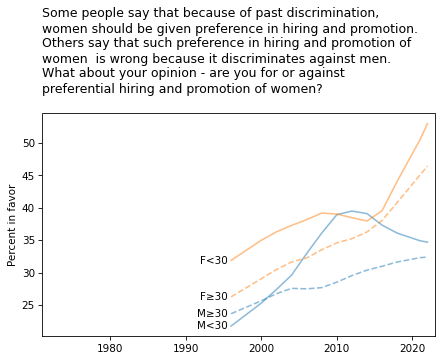
title = """Some people say that because of past discrimination,
women should be given preference in hiring and promotion.
Others say that such preference in hiring and promotion of
women is wrong because it discriminates against men.
What about your opinion - are you for or against
preferential hiring and promotion of women?
"""
plot_four_series('fejobaff', smooth=smooth)
plt.title(title, loc='left')
plt.ylabel('Percent in favor');
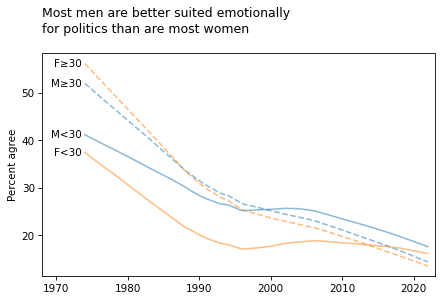
title = """Most men are better suited emotionally
for politics than are most women
"""
plot_four_series('fepol', smooth=smooth)
plt.title(title, loc='left')
plt.xlim([1968, 2023]);
title = """A preschool child is likely to suffer if his or her mother works
"""
plot_four_series('fepresch', smooth=smooth)
plt.title(title, loc='left');